SkyReels V4 是什麼?首個統一視訊音訊 AI 模型詳解
SkyReels V4 是首個能同時生成視訊與音訊的開源 AI,支援 1080p/32FPS 輸出。了解它的功能、運作原理及其重要性。

你好,我是 Dora。那天我生成了我的第一個 **SkyReels V4** 影片。十五秒的貓咪在黃昏時走過雨水浸透的小巷。影片效果很好——1080p、流暢的動作、漂亮的光線。但讓我停下來的是聲音。腳步聲濺起水窪。遠處的車流聲。小巷牆壁傳來的微弱回聲。這一切都同步生成,完美同步,而我完全沒有碰任何音訊編輯工具。
這才是讓人感到不同的地方。
V4 之前每個 AI 影片工具都有的問題
為什麼純影片生成總是感覺不完整
大多數 AI 影片工具生成的是無聲片段。 Runway、Pika,甚至早期的 SkyReels 版本——它們只產出視覺效果就停止了。你得到一個美麗的十秒海浪拍岸畫面,但完全是靜默的。海浪不發出聲音。風不吹拂。完全沒有任何環境音。
這不是技術上的疏忽。在影片旁邊同步生成音訊確實是一件相當困難的事。音訊不僅需要匹配整體場景,還需要與特定的視覺事件相符——腳踩地面時傳出腳步聲、門揮動關閉時發出聲響、聲音與嘴唇動作同步。
「後製加入音訊」的瓶頸
標準工作流程變成了:生成影片、匯出、打開音訊編輯器、手動加入音效或音樂、手動同步所有內容、再次匯出。對於一個十五秒的片段,這可能要花費二十到三十分鐘。
我上個月用 Pika 的輸出結果嘗試了這個流程。影片看起來很專業。但尋找合適的環境音、將它們定時配合視覺提示、避免那種「明顯是後來加上的」感覺,花費的時間比生成影片本身還要多。這個工作流程感覺很糟糕——就像買了一輛車卻還要自己另外安裝引擎。
SkyReels V4 究竟是什麼
由 SkyworkAI 打造(V1/V2/V3 的演進脈絡說明)
SkyworkAI 於 2025 年初發布了 SkyReels V1,作為基本的文字轉影片模型。V2 隨後引入了擴散強制架構,透過自回歸序列實現無限長度的生成。V3 於 2026 年 1 月推出,具備多模態情境學習功能——你可以輸入參考圖片、音訊片段或現有影片,它會生成連貫的延續內容。

V4 於 2026 年 2 月 25 日正式上線,代表了一種不同層次的飛躍。V3 是新增功能,而 V4 則是圍繞一個雙流系統重新構建整個架構,可以同時生成影片和音訊。
「統一影音基礎模型」的真正含義
技術論文描述 V4 使用了帶有兩個平行分支的多模態擴散 Transformer(MMDiT)。一個分支合成影片幀,另一個生成時間對齊的音訊。兩個分支共享一個基於多模態大型語言模型的文字編碼器,這意味著它們對你的提示詞處理相同的語義理解,並在整個生成過程中保持同步。
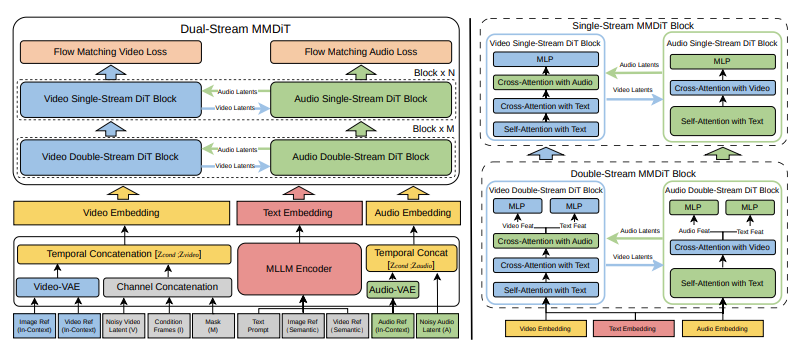
這不是影片生成後再附加音訊。這是一個單一模型,將視覺和聲音視為同等重要的輸出,從對場景相同的潛在理解中共同生成。
實際上,這意味著當你輸入「一位女性在講台上發言」時,模型會同時生成她嘴唇動作的視覺效果和實際的語音音訊,在幀級別同步。當你生成「大雨打在金屬屋頂上」時,你會得到雨水流下的視覺效果和特有的金屬鼓聲——不是大致匹配,而是作為統一的影音事件一起生成。
核心功能一覽
從單一提示詞同時生成影片與音訊
單一提示詞生成是核心功能。 你輸入「雷聲在沙漠景觀上滾滾而來」,V4 就會產出十五秒的雲層聚集、閃電劃過,以及與視覺時序匹配的同步雷聲轟鳴。不需要單獨的音訊生成步驟,不需要手動同步工作。
我用對話場景測試了這個功能。輸入「兩人在熱鬧的咖啡廳爭吵」,得到的不只是對話的視覺效果,還有背景人聲嘈雜、餐具碰撞聲,以及說話者聲音隨著動作強度起伏的效果。嘴形同步並不完美——我注意到有幾個時刻時序略有偏移——但已經比我手動同步的任何效果都要好。
1080p / 32FPS / 15 秒輸出
技術規格:最高 1080p 解析度、每秒 32 幀、最長 15 秒時長。作為參考,大多數競爭工具的上限是 720p,或者需要更長的時間才能生成高清輸出。
15 秒的限制比聽起來更重要。大多數社群媒體內容都在 10 到 15 秒之間。YouTube Shorts 上限為 60 秒,Instagram Reels 為 90 秒。對於這種使用場景,帶同步音訊的 15 秒比需要後製的 30 秒無聲影片更有用。
多模態輸入:文字、圖片、影片、遮罩、音訊參考
V4 接受五種輸入類型:文字提示詞、參考圖片、影片片段、用於修復的二值遮罩,以及音訊參考。你可以組合使用——上傳特定人物的圖片、提供碎石路上腳步聲的音訊樣本,然後輸入「黎明時在森林中行走」。模型使用這三種輸入來引導生成。
我使用特定建築風格的參考圖片和街道環境音訊片段測試了多模態提示功能。生成的影片保留了圖片中的建築細節,同時融入了音訊參考中的環境音效。雖然不是完美無缺——一些音訊元素感覺較為泛泛——但這個功能確實奏效了。
三合一任務:生成、修復、編輯
除了生成之外,V4 透過通道拼接(channel concatenation)處理修復和編輯。 提供一個影片和一個指示需要修改區域的遮罩,模型只重新生成這些區域,同時保留其餘部分。這樣就能實現移除物件、更換背景或替換特定元素等任務,而不需要重新生成整個片段。
V4 與過去版本的比較
V4 對比 SkyReels V1/V2/V3 的演進
V1 只有文字轉影片功能。V2 透過擴散強制技術增加了長度。V3 引入了多模態輸入,但仍然生成沒有原生音訊的影片。V4 是第一個將音訊作為與影片同時生成的一等輸出的版本。
誰應該關注 SkyReels V4?

內容創作者與電影製作人
任何為社群平台製作短影音內容的人都能立即受益。 工作流程的壓縮——從提示詞到完成的影音片段——消除了讓 AI 影片工具感覺創造了更多工作而非節省工作的瓶頸。
我看著一位電影製作人朋友使用 V4 為紀錄片生成 B-roll 素材。像是「城市燈光在黃昏時亮起的縮時攝影」或「窗玻璃上雨滴的特寫」這樣的提示詞,搭配適當的環境音。輸出效果與真實拍攝的素材並非無法分辨,但作為背景鏡頭已經足夠好了,而且每個都在不到 60 秒內完成,而不需要外景拍攝或授權購買素材庫影片。
建構影片處理管線的開發者
如果你正在建構生成或處理影片的應用程式,V4 統一的生成、修復和編輯介面能簡化技術堆疊。無需串接獨立的影片生成、音訊合成和同步校正模型,一個 API 呼叫就能處理整個流程。
模型架構有詳細的文件說明,SkyworkAI 也有開源舊版本的歷史,這意味著開發者的存取權限將會擴大。V3 的模型權重已可在 Hugging Face 和 GitHub 上取得。
目前的存取狀態與未來展望
截至 2026 年 3 月 2 日,V4 仍處於有限預覽階段。官方網站提供每日生成限制的免費方案,但尚無 API 存取。根據 V3 的時間線——從論文發布到公開 API 大約兩週——我預計更廣泛的可用性將在三月中旬前後到來。
技術論文指出,未來的工作包括延伸超過 15 秒的限制以及改進精細的音訊控制。這些限制目前感覺相當顯著,尤其是時長上限。但對於 V4 所解決的特定問題——生成短小的、同步的影音片段而無需後製——它的表現比我測試過的任何其他工具都要好。
自從第一次測試之後,我就將 V4 保留在我的工作流程中。不是用於所有事情——仍然有一些任務使用實地拍攝的素材或素材庫影片更合適。但對於需要同步音訊的快速 B-roll、環境場景或社群媒體短片,V4 消除了足夠多的摩擦,讓我現在會優先選擇它。
這種統一架構感覺不像是漸進式的功能增加,更像是修復了一個從一開始就應該如此運作的問題。



