TranslateGemma 線上示範 + 快速入門指南

嗨,我是 Dora。你聽過「TranslateGemma」嗎?
促使我嘗試這個工具的原因很簡單:一位客戶送來了混合英文和西班牙文的文案,還有一些隱藏的佔位符,我不想逐行監督翻譯模型。你知道那種情況:一個錯誤步驟,佔位符就會崩潰。我不斷看到「TranslateGemma」在討論串中出現,所以我試了試,不是因為它新穎,而是因為我想要一個更輕鬆的方式來獲得忠實的翻譯,而不會破壞格式。劇透:它基本上有不負所託。我在 2026 年 1 月期間透過幾個線上示範和本地設定進行了測試。以下是實際幫助的地方、它失敗的地方,以及我如何最終構建提示詞來保持它的穩定性。
在線嘗試 TranslateGemma(無需設定)
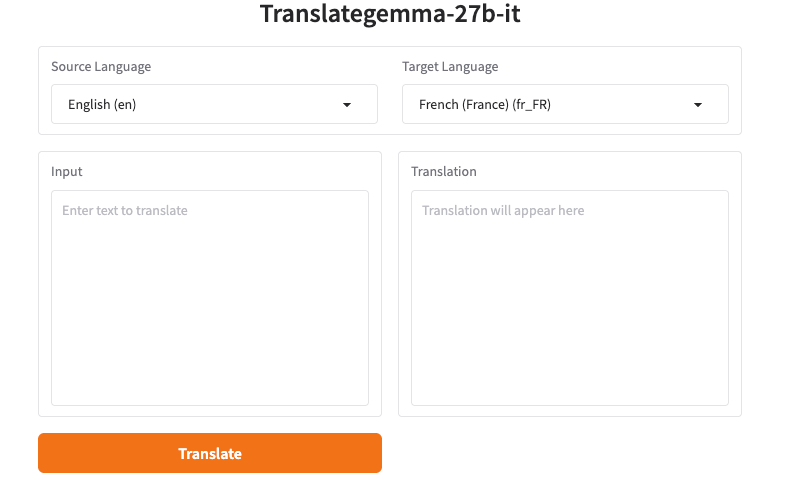
我不喜歡只是為了看它是否有用就安裝東西。所以我從線上 TranslateGemma 開始。如果你搜尋「TranslateGemma online」,你會找到一些託管的遊樂場:Hugging Face Spaces、Replicate 示範,以及一些輕量級 Web UI 包裝為翻譯調整的 Gemma 檢查點。有些需要免費登入;有些則不需要。無論如何,你通常可以貼上文本並選擇語言。
讓我驚訝的是:即使在共享示範上速度也不錯。短段落在一兩秒內返回;較長的頁面花費的時間更長,但不足以促使我喝咖啡。我還是盯著螢幕看。老習慣,我想。更大的區別不是速度,而是我如何構建提示詞。
簡單的「翻譯為法文」有效,但當文本混合語調、包含內嵌程式碼或使用 {{first_name}} 之類的變數時,輸出會漂移。修復方法是一組簡短、明確的說明。當示範公開「系統提示詞」欄位時,我使用它。當它沒有時,我將說明放在使用者消息的頂部。
以下是為我一致減少清理工作的最小提示詞:
- 說出來源語言和目標語言。
- 告訴模型要保持不變的內容(佔位符、程式碼區塊、標籤)。
- 使用柵欄圍起文本,以便模型知道從何處開始和停止。
- 要求純粹翻譯,不要評論。
我在線上使用的例子:
我在線上使用的例子:
將以下文本從英文翻譯為西班牙文。保持 {{first_name}}、{{price}} 等佔位符和 HTML 標籤不變。保留換行符和標點符號。只返回翻譯後的文本,沒有其他內容。
<
Subject: Welcome, {{first_name}}.
Your total is {{price}}.
Click <a href="/start">here</a> to begin.
>>>這第一次沒有節省時間。經過兩次運行後,它節省了,主要是因為我停止修復破碎的佔位符。如果你只是在檢查 TranslateGemma 線上的完整性,嘗試一段短文本,有和沒有該結構。差異顯示得很快。
你必須遵循的聊天範本格式
 Gemma 風格的聊天模型在你尊重轉動標記時反應最好。某些 UI 會為你添加它們。其他則期望原始文本。如果你直接發送提示詞(API、Python 或基本 UI),清晰、可重複的範本會有所幫助。
Gemma 風格的聊天模型在你尊重轉動標記時反應最好。某些 UI 會為你添加它們。其他則期望原始文本。如果你直接發送提示詞(API、Python 或基本 UI),清晰、可重複的範本會有所幫助。
兩個可靠的模式對我有效:
1. 純文本範本(在大多數 Web 示範中有效)
你是一個精確的翻譯助手。
- 來源語言:英文
- 目標語言:西班牙文
- 保持 {{...}}、markdown 反引號和 HTML 標籤不變。
- 保留標點符號和換行符。不要添加說明。
文本待翻譯:
<
[貼上你的文本]
>>>2. Gemma 聊天轉動風格(在公開聊天範本的庫中有用)
<start_of_turn>user
你是一個精確的翻譯助手。
來源:英文
目標:西班牙文
規則:保持 {{佔位符}}、程式碼區塊和 HTML 不變;保留換行符;只輸出翻譯。
文本:
<
[貼上你的文本]
>>>
<end_of_turn>
<start_of_turn>model我沒想到轉動標記會如此重要,但它們確實很重要。沒有它們,我看到更多「有幫助的」改寫(模型試圖改進措辭)。有了它們,以及有柵欄的輸入,模型更接近任務。
細小的細節產生了很大的差異:
- 明確命名語言。「從英文翻譯為西班牙文」的表現好於「翻譯為西班牙文」。
- 在文本之前放置規則。如果你將規則放在文本之後,它們更容易被忽略。
- 用不同的開始/停止來圍起文本(
<<<和>>>或三重反引號)。這減少了在開始或結束時意外修剪。
在本地執行 TranslateGemma(Python)
 我喜歡為更長的工作或敏感的草稿擁有本地備用方案。叫我偏執狂,但有時雲端就是感覺太…健談。在我的機器上(32 GB RAM、消費級 GPU),一個較小的基於 Gemma 的翻譯檢查點舒適運行;較大的檢查點需要更多 VRAM 或量化。如果你只有 CPU,它很慢但可以通過仔細的設定完成。
我喜歡為更長的工作或敏感的草稿擁有本地備用方案。叫我偏執狂,但有時雲端就是感覺太…健談。在我的機器上(32 GB RAM、消費級 GPU),一個較小的基於 Gemma 的翻譯檢查點舒適運行;較大的檢查點需要更多 VRAM 或量化。如果你只有 CPU,它很慢但可以通過仔細的設定完成。
以下是一個簡單的 Hugging Face Transformers 模式。我故意讓 model_id 保持通用,從 Hub 選擇一個你信任的 Gemma 或 Gemma 衍生翻譯模型,最好是有翻譯記錄的。下面的範本鏡像線上提示詞。
# 使用 transformers >= 4.40 在 2026 年 1 月測試
from transformers import AutoTokenizer, AutoModelForCausalLM, TextStreamer
import torch
model_id = "<your-gemma-translation-checkpoint>" # e.g., a Gemma chat or translation-tuned model
device = "cuda" if torch.cuda.is_available() else "cpu"
dtype = torch.float16 if device == "cuda" else torch.float32
# Load
tokenizer = AutoTokenizer.from_pretrained(model_id, use_fast=True)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=dtype,
device_map="auto" if device == "cuda" else None
)
# Prompt template (plain text). Swap for chat turns if your model requires them.
prompt = (
"You are a precise translation assistant.\n"
"Source language: English\n"
"Target language: Spanish\n"
"Rules: keep placeholders like {{...}}, code blocks, and HTML tags unchanged: "
"preserve punctuation and line breaks: output only the translation.\n\n"
"Text:\n<<<\n"
"Subject: Welcome, {{first_name}}.\nYour total is {{price}}.\n"
"<p>Click <a href=\"/start\">here</a> to begin.</p>\n"
">>>\n"
)
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
gen = model.generate(
**inputs,
max_new_tokens=300,
temperature=0.3,
top_p=0.9,
repetition_penalty=1.02,
do_sample=True,
eos_token_id=tokenizer.eos_token_id,
)
output = tokenizer.decode(gen[0][inputs["input_ids"].shape[1]:], skip_special_tokens=True)
print(output)從測試中得出的一些注意事項
- 如果你的檢查點包括聊天範本,請使用庫的
apply_chat_template()實用程式而不是手動字符串。它減少了一半的奇怪行為。 - 對於長輸入,設定
max_new_tokens足夠高,並保持temperature低(0.2–0.4)。更溫暖的抽樣邀請「改進」。有些有幫助,有些…不太有幫助。 - 量化在較小的 GPU 上有幫助。4 位元(bitsandbytes)在直接翻譯時運行良好。
- 如果你需要批量翻譯,將提示詞包裝在一個小函數中並流式傳輸行。我發現按段落分塊比巨大的塊更安全,失去結構的可能性更小。
需要運行翻譯工作負載而無需管理 GPU 基礎設施或本地設定嗎?
我們建立了 WaveSpeed,所以我們的團隊可以透過統一 API 呼叫模型並處理批量任務,而無需啟動伺服器或與驅動程式搏鬥 → 試試看!
常見錯誤和修復
 這些是我在線上和本地嘗試 TranslateGemma 時遇到的最常見模式,以及實際上為我減少摩擦的修復。
這些是我在線上和本地嘗試 TranslateGemma 時遇到的最常見模式,以及實際上為我減少摩擦的修復。
輸出不是目標語言
我主要在沒有聲明來源語言時看到這種情況。混合語言輸入使其感到困惑,足以保留英文短語。粘住的修復:
- 命名兩種語言:「從英文翻譯為西班牙文。」當準確性很重要時,不要依賴檢測。
- 將溫度降低(0.2–0.4)並使用輕量
repetition_penalty(大約 1.02)。它推動模型遠離創意改寫。 - 添加最終防線:「如果文本已經是西班牙文,則原封不動返回。」這減少了雙語程式碼片段上的過度翻譯。
丟失格式或佔位符
這是行銷電子郵件和產品字符串的大問題。早期運行破壞了 {{variables}} 或重新排序了 HTML。有幫助的:
- 明確:「保持
{{...}}之類的佔位符和 HTML 標籤不變。不要翻譯程式碼柵欄內的內容。」 - 圍起輸入並保留換行符。
<<<和>>>模式比依賴空白行效果更好。 - 對於脆弱的內容,在提示詞中用標記圍起佔位符:「佔位符受雙大括號保護,如
{{this}}。不要改變它們。」如果示範不斷丟棄大括號,我在翻譯前臨時將{{替換為[[[,將}}替換為]]],然後交換回去。這不優雅,但對批量工作更安全。
模型改寫而不是翻譯
有時輸出讀起來像編輯的改寫,而不是翻譯。在某些情況下有幫助,在大多數情況下令人厭煩。我的實用修復:
- 在頂部陳述角色和限制:「你是一個翻譯助手。只輸出忠實的翻譯。沒有摘要,沒有說明。」
- 降低溫度並避免對短輸入的長
max_new_tokens:額外的空間在某些檢查點上鼓勵評論。 - 如果模型仍然過度修飾,請嘗試使用清晰停止的聊天轉動範本。在本地程式碼中,設定停止序列到你的轉動標記(例如
<end_of_turn>)。在託管示範中不支援停止,添加「只返回翻譯後的文本」約 80% 的時間減少了廢話。
還有一個安靜的注意事項:某些標記為翻譯的社群檢查點實際上是指令調整的通用模型。它們會翻譯,但它們更健談。如果你同時遇到所有三個問題,請嘗試不同的檢查點或更小、更嚴格的檢查點。不那麼聰明通常意味著在這個領域更忠實。老實說,這就是我所需要的。
你試過 TranslateGemma 嗎?你保持佔位符完整或最困難的文本使其失敗的首選提示詞是什麼?在下面分享你的成功、失敗或最愛的技巧吧!





