GLM-4.7-Flash 對比 GLM-4.7:哪一個更適合您的專案?

你好,朋友們。我是Dora。如果這聽起來很熟悉,你並不孤單。我一直都在那裡:盯著一個小小的、重複的提示隊列,這些提示只需要快速、可靠的回覆——而與此同時,一些頑固的、多步驟推理任務坐在角落裡,悄悄地要求更多的運算能力。
所以我最後大聲問出了這個問題:輕量級、閃電般快速的GLM-4.7-Flash實際上在哪裡表現出色,而在哪裡你需要引入更重型、更謹慎的GLM-4.7?這是我得出的直接、無炒作的答案——以真實的運行、相關的基準測試和減輕日常技術棧感覺的安靜目標為基礎。如果你曾經在「我應該在這裡使用哪個模型」上停頓過,這是為你量身定做的。
30秒答案
如果速度和低成本是你的主要杠桿,GLM-4.7-Flash 可能會感到合適。如果你的工作傾向於推理深度、工具或更高保真度的輸出,GLM-4.7 是更穩定的選擇。其餘的都是圍繞延遲預算、上下文大小和你的提示在壓力下如何表現的細微差別。
如果…選擇Flash
Flash 並不是「較弱」——它只是對自己擅長的東西非常誠實。
- 你正在分派許多小工作:摘要、標籤、草稿、快速轉換。
- 延遲比挤出最後10%的質量更重要。
- 你在實驗、原型設計或構建應該感覺即時的UI交互。
- 長推理步驟中偶爾的波動不會使你脫軌。
- 你想要一個更便宜的默認模型,只有在需要時才能升級到 GLM-4.7。
如果…選擇GLM-4.7
這是你的「別搞砸了」模型。
- 你關心代碼可靠性、多步驟推理或工具使用精度。
- 提示很長、指令嚴格,或輸出需要一致。
- 你正在運行評估器、測試或工作流,其中一個錯誤代價很高。
- 你需要在編碼和長上下文任務上獲得更強的結果。
- 你可以容忍更高的成本和稍微更多的延遲以獲得更好的結果。
架構差異
 我不是為了運動而追求參數計數,但架構解釋了很多關於行為的東西:為什麼一個模型感覺靈敏,另一個感覺謹慎。
我不是為了運動而追求參數計數,但架構解釋了很多關於行為的東西:為什麼一個模型感覺靈敏,另一個感覺謹慎。
參數計數和活躍專家
GLM-4.7 似乎運行一個更大的主幹,並且(根據公開說明)使用優先考慮推理的專家路由。Flash 針對吞吐量進行了優化,路由更輕、每個令牌的活躍專家更少,以及激進的效率設置。在實踐中,這往往表現為:
- Flash:較低的每令牌計算、快速的首令牌時間,但在壓力下它可能會放棄推理鏈。
- GLM-4.7:每令牌更多的計算、更穩定的推理路徑、更好的工具調用選擇。
如果你略讀提供商圖表,你會看到混合專家(MoE)和激活稀疏性的提示。確切的數字在版本間漂移,所以我將它們視為方向性的,而不是絕對的。核心思想:Flash 每令牌花費更少的「思考」時間所以它移動得更快;GLM-4.7 思考得更長並在邊界情況上跌得更少。
上下文窗口和輸出限制
兩個實際問題比標題上下文數字更重要:
- 長提示的質量能保持多遠?
- 當輸出變長時,模型是否會失去線索?
Flash 通常宣傳一個健康的上下文窗口,但使用非常長的提示或密集指令時,質量往往會更早衰減。GLM-4.7 在長上下文深處保持連貫性,並在長輸出中對結構保持更多的服從。如果你在打包知識庫,GLM-4.7 是更安全的默認選擇。如果你在分割輸入或使用檢索來保持提示簡潔,Flash 通常足夠好——而且快得多。
基準比較
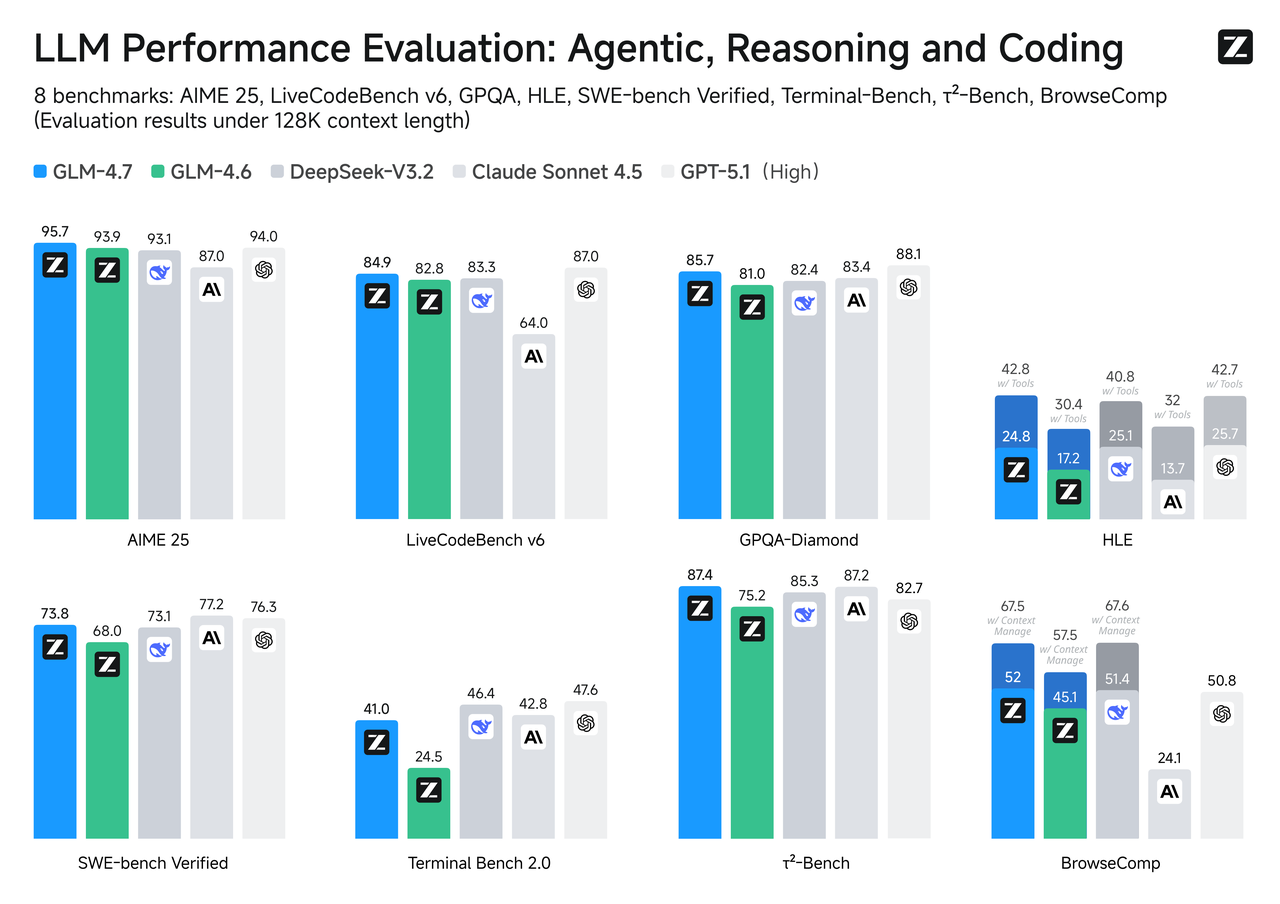 基準測試不是完整的故事,但當你的用例與任務一致時,它們是一個有用的指南針。
基準測試不是完整的故事,但當你的用例與任務一致時,它們是一個有用的指南針。
SWE-bench 驗證
對於必須實際編譯並通過測試的代碼更改,GLM-4.7 往往排名高於其 Flash 同級。這與你對為推理深度和工具使用調整的模型的期望相符。Flash 可以草擬修復並很好地解釋代碼,但當修補程序需要在文件間進行多個協調的編輯時,GLM-4.7 更可能遵循鏈條而不會放棄步驟。
如果你的管道包括自動PR或修復循環,值得先用小樣本進行理智檢查。差異在多跳問題上比在單文件調整上更明顯。
LiveCodeBench / τ²-Bench
在實時或時間旋轉編碼基準上,GLM-4.7 通常跟蹤更接近頂級層級的性能,鑑於其更重的推理預算。Flash 針對速度優化,排名略低但反應迅速。如果你的產品更依賴代碼合成質量而不是交互速度,GLM-4.7 是保守的選擇。如果代碼是建議性的(你無論如何都會審查它)並且響應度很重要,Flash 可能是正確的權衡。
速度和延遲
這是分割感覺最清晰的地方。Flash 經常以明顯更快的速度返回第一個令牌,總的時間到最後令牌保持低位於短中等輸出。如果你運行許多小調用或流式傳輸到UI,這會累加。
GLM-4.7 啟動較慢並運行更重,但對長代碼生成和複雜工具調用序列更穩定。你會看到更少的停頓、更少的奇怪迂迴以及更好的對函數模式的遵守。
如果你正在構建一個系統:
- 對高流量UX時刻使用Flash:自動完成、快速摘要、內聯幫助。
- 對慢車道使用GLM-4.7:評估器、代碼操作、策略檢查、最終通過。
一個簡單的路由規則經常為自己帶來回報:從Flash開始,當信心下降或閾值被越過時升級到GLM-4.7。讓規則決定,所以你不必。
價格分解
定價因地區和提供商而異,所以我將數字視為移動目標並保持結構穩定。
Flash 免費層 vs GLM-4.7 按令牌付費
-
Flash:許多平台為Flash類模型提供免費或低成本層,與旗艦模型相比有慷慨的速率限制。非常適合原型設計、後台工作和UI改進。
-
GLM-4.7:通常按較高速率按令牌計費。在認真任務上更好的成本價值,但如果你將其保留為默認值,很容易超支。
 實用提示:
實用提示: -
默認情況下限制輸出令牌。只在需要的路由中提高上限。
-
使用檢索來保持提示簡短:不要將整個語料庫倒入窗口。
-
緩存確定性子結果(正則表達式映射、模式片段、少數鏡頭塊),這樣你就不必再為它們支付。
-
記錄每個路由的令牌成本。你實際上會讀的報告是坐在你周週工作流中的報告,而不是有最多圖表的報告。
有疑問時,開始便宜,測量,然後提升。升級優於樂觀主義。
按用例選擇
以下是當目標是減少頭痛時,我會如何分配它們:
- 高流失內容操作(片段、主題行、元數據):Flash。勝利在於吞吐量和低成本的一致性。
- 支持宏和快速分類:首先是Flash,然後如果檢測標誌複雜性或策略風險,升級到GLM-4.7。
- 研究筆記、綜合、結構化摘要:Flash用於掃描;GLM-4.7用於必須源忠實和良好搭建的通過。
- 代碼協助:Flash用於解釋和「這是做什麼的?」;GLM-4.7用於多文件編輯、遷移和測試感知更改。
- 數據清理和轉換:Flash適合簡單映射;GLM-4.7用於嚴格模式、驗證和多步連接。
- 代理和工具使用:GLM-4.7。你會得到更可靠的函數參數和更少的重試。
- 長上下文閱讀或文檔基礎QA:如果你在推動窗口,則GLM-4.7;如果你保持塊精益,則Flash。
我保持的一些現場筆記:
- 短提示隱藏差異。當指令密集或輸出必須遵循結構時,差距會出現。
- 路由幫助。即使是一個簡單的規則「Flash除非提示> N令牌,則GLM-4.7」也可以在沒有戲劇的情況下節省金錢。
- 對於重複任務,護欄比模型選擇更重要。驗證、重試和小檢查器可防止下游混亂。
- 不要迷戀速度。不足一秒感覺「即時」對大多數用戶。過去那個,穩定行為擊敗剃須100毫秒。
為什麼這很重要:當工具減輕精神負擔時,工具就會長壽。Flash讓小東西輕。GLM-4.7 背著沉重的盒子而不放棄它們。大多數技術棧需要兩者。
如果你不確定,從Flash作為你的默認開始,為GLM-4.7創建一個清晰的通道。讓路由而不是心情決定。你的里程可能會有所不同,這很好。
我仍然注意到,在安靜的日子裡,這種分裂如何減少決策疲勞。沒有什麼花哨——只是更少的頭痛。
我如何在實踐中實際運行這種分裂
 當我需要將快速工作路由到Flash,並在不照看腳本的情況下將更重的工作升級到GLM-4.7時,我使用WaveSpeed——我們自己的平台。
當我需要將快速工作路由到Flash,並在不照看腳本的情況下將更重的工作升級到GLM-4.7時,我使用WaveSpeed——我們自己的平台。
我們構建它以乾淨地處理模型切換、並發和批量調用,所以「Flash優先、在需要時升級」的模式保持簡單而不是易碎。
如果你運行大量小調用,不想讓路由邏輯成為另一個需要維護的東西,試試Wavespeed!
常見問題:GLM-4.7-Flash vs GLM-4.7
1. GLM-4.7-Flash 和 GLM-4.7 之間的主要區別是什麼?
GLM-4.7-Flash 是 GLM-4.7 的輕量級、優化的變體。它通過減少活躍專家數量、簡化路由和應用效率調整來實現更快的推理和更低的成本。GLM-4.7 保留了更大的主幹和更強的推理能力,在複雜的多步驟推理、長上下文連貫性和精確工具調用中表現出色。
簡而言之: Flash 以一些智能換取速度;GLM-4.7 優先考慮深度和可靠性。
2. 哪個模型更快,在哪些場景中速度差異最明顯?
GLM-4.7-Flash 具有顯著更低的首令牌時間 (TTFT) 和每令牌延遲。它在高吞吐量、低延遲的用例中表現出色,如實時UI交互、內容摘要、元數據生成和快速原型設計。
GLM-4.7 具有更高的啟動開銷和更重的計算,但對於長輸出或複雜工具調用序列保持更穩定。在實踐中,Flash 對於短到中等輸出(500令牌以下)明顯更快。
3. 哪個模型在智能和推理方面更強?
GLM-4.7 在多步驟推理、代碼可靠性、工具使用和長上下文任務上優於Flash。例子:
- SWE-bench 驗證: GLM-4.7 在多文件代碼編輯和協調補丁中領先。
- LiveCodeBench / τ²-Bench: GLM-4.7 提供更高質量的代碼,特別是對於深度推理場景。
Flash 適合單文件編輯或容忍人工審查的協助任務,但在長推理鏈或密集提示上降級得更快。
4. 上下文長度和輸出限制如何比較?
兩個模型共享相似的上下文窗口,但GLM-4.7 在非常長的上下文(>32k令牌)或密集提示上保持更好的連貫性和指令遵守。Flash 在極端提示長度或密度下降級得更快——與分塊或RAG配對以獲得最佳結果。
5. 我應該根據定價和成本控制如何選擇?
GLM-4.7-Flash 通常提供更高的免費配額和更低(或甚至零)的每令牌定價,使其非常適合原型設計、後台任務和高容量低風險調用。GLM-4.7 具有更高的每令牌成本,但在關鍵任務上具有更好的價值。
推薦: 默認為Flash,升級到GLM-4.7以進行複雜工作,始終設置令牌上限和緩存以防止超支。





