在本地運行 GLM-4.7-Flash:Ollama、Mac 和 Windows 設置指南

嗨,我是Dora。幾天前,一件小事推動了我去做這件事:我一直在等待遠程完成一些微小的草稿任務。不是幾分鐘,只是足夠的延遲讓我會轉向電子郵件並失去思路。上週(2026年1月),我試著在本地運行GLM-4.7-Flash,看看削減幾秒鐘是否真的能幫助我更清晰地思考。
簡短版本:確實有幫助,但不是因為那些令人印象深刻的原因。GLM-4.7-Flash感覺更像是一個穩定的助手,而不是一個頭條模型。它的速度足夠快,能讓我保持在流動狀態,也足夠輕量級,可以在筆記本電腦上運行而不會發熱。我會分享什麼有效,什麼停滯了,以及保持事情無聊的設置,但這是好的方式。
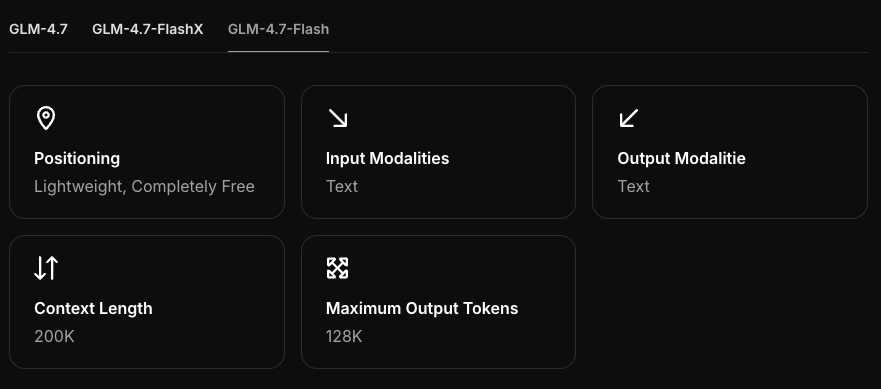
硬體需求
最低GPU / RAM
我在三台機器上運行了GLM-4.7-Flash:
- MacBook Pro M3 Pro(12核CPU / 18核GPU,36 GB RAM)
- Mac mini M2(24GB統一內存)
- Windows台式機,配RTX 4090(24GB VRAM)
根據這些測試,實際的下限:
- 僅CPU(Mac/Windows/Linux):16GB系統內存可行,32GB更友好。預期首個token較慢。
- Apple Silicon(Metal):16GB統一內存在4位/5位量化和適度上下文(2–4K)下可用。8GB感覺很緊張。
- NVIDIA:8–12GB VRAM是我願意為4位量化嘗試的最低要求。16GB及以上更舒適。
GLM-4.7-Flash感覺像是一個中等大小的模型(想想10–12B參數以下)。在4位量化中,您通常需要大約5–6GB的設備內存加上KV緩存。如果您推送長上下文或多個並行提示,內存會增加。
推薦配置
如果您想要那種”始終反應迅速”的感覺:
- Apple Silicon:M3或更新版本,配24–36GB統一內存:保持上下文4–8K。
- NVIDIA:24GB VRAM(例如3090/4090)為更高的上下文和併發性提供了空間。
- 存儲:快速SSD:模型加載更快,交換更少。
我注意到,當內存壓力開始時,模型停止感覺”閃亮”,頁面輸出或VRAM溢出會增加微妙的卡頓,打破流動。額外的一點空間可以帶來很大幫助。
Ollama設置
我使用Ollama是因為它能使本地運行簡單且在機器間保持一致。版本上下文在這裡很重要。
安裝Ollama 0.14.3+
- macOS:brew install ollama(或使用brew upgrade ollama更新)。
- Windows:使用Ollama網站的官方安裝程序。

- Linux:按照文檔中的curl腳本操作。
我在此測試中使用0.14.3版本(2026年1月)。較新的版本有時會改變默認後端或量化行為,所以我堅持對我穩定的版本,除非有理由升級。
拉取並運行GLM-4.7-Flash
兩個路徑對我有效:
-
如果您的Ollama庫包含官方GLM-4.7-Flash構建:
- ollama pull glm-4.7-flash
- ollama run glm-4.7-flash
-
如果它沒有顯示(這在一台機器上發生了):
- 創建指向GLM-4.7-Flash的已知GGUF或兼容工件的Modelfile。
- 示例Modelfile(簡化):
- FROM ./glm-4.7-flash-q4.gguf
- 僅在您知道需要時添加提示模板:我保持最少。
- 然後:ollama create glm-4.7-flash-local -f Modelfile
- 運行:ollama run glm-4.7-flash-local
使用時的注意事項:
- 首次加載速度較慢,因為它會預熱緩存。
- 我保持num_ctx保守(4K或8K),除非我在總結書籍草稿。更大的上下文感覺不錯,但它們內存消耗大,對日常草稿的質量幫助不總是大。
- 如果生成感覺猶豫,嘗試將溫度降至0.6–0.7並稍微提高top_p:它為我緊化了輸出,而不失速度。
參考資料:Ollama文檔對於特定於平台的標誌和當前後端很好。

Mac性能
M4 / M3 / M2基準
這些不是實驗室級別的,只是在寫作和輕程式碼提示上的穩定運行,溫度0.7,4K上下文,4位量化:
- M4(借用機器,48GB):預熱後60–85 tok/s。首個token約350–500毫秒。
- M3 Pro(36GB):35–55 tok/s。首個token約500–800毫秒。
- M2(24GB):20–30 tok/s。首個token約900–1200毫秒。
將範圍視為氛圍檢查。我在M3 Pro上推了一些8K上下文:速度下降了約20–30%,但對於草稿仍然可用。在M2上,長上下文穿過我的”感覺粘稠”的界線。我在那裡保持2–4K。
內存優化
在macOS上最有幫助的是:
- 保持較少的終端標籤運行模型。顯而易見,是的,但我忘記了。
- 正確調整上下文大小。4K對我來說是甜蜜點。
- 在可能的情況下使用4位量化。5位在質量上感覺相似,但速度較慢。
- 關閉會佔用GPU時間的應用程序(視頻編輯器、帶WebGL的某些瀏覽器標籤)。
我還注意到使用穩定的系統提示減少了返工。在紙上沒有更快,但更少的重試意味著更好的”感受速度”。一個小提示,如:“簡潔,使用簡單英語,無營銷語氣。“它符合模型的優勢。
Windows + NVIDIA
RTX 3090 / 4090配置
在4090上(24GB),GLM-4.7-Flash感覺始終很快:
- 4位量化,4–8K上下文:預熱後120–220 tok/s。
- 首個token:約250–400毫秒。
- 並行提示:2–3個流,然後我看到卡頓。
一位朋友在3090(24GB)上運行它,看到類似設置下的吞吐量約低15–25%。如果您推送超過8K上下文或同時保持許多回應,您將達到VRAM上限。我通常退回到4–6K並保持批次較小。
CUDA設置
實踐中的重要事項:
- 最近的NVIDIA驅動程序(乾淨安裝幫助了一台卡頓的機器)。
- CUDA 12.x和匹配的運行時,如果您正在步出Ollama(vLLM/SGLang)。對於Ollama本身,您不總是需要完整的工具包,但最新的驅動程序是非協商的。
- 電源設置:將您的GPU設置為”首選最大性能”。它聽起來像遊戲建議,但它在長時間運行中停止了時鐘降速。
如果您遇到加載錯誤或硬回退到CPU,我會再檢查:
- 驅動程序版本與CUDA運行時的對齐。
- 防病毒軟體是否在掃描您的模型目錄(它發生過:很愚蠢:速度很慢)。
參考資料:NVIDIA的驅動程序–CUDA兼容性表在沉入一小時的調試之前值得快速檢查。
vLLM / SGLang
當我想更好地控制批處理和服務器樣式端點時,我用vLLM和SGLang嘗試了GLM-4.7-Flash。
vLLM
- 安裝:最近的Python、CUDA兼容的PyTorch,然後pip install vllm。
- 運行:
python -m vllm.entrypoints.openai.api_server --model <your_glm_flash_id> --dtype auto --max-model-len 4096 - 我使用它的原因:穩定的OpenAI兼容API,多用戶或多標籤工作流的固體吞吐量。
SGLang
- 安裝:pip install sglang
- 運行:
python -m sglang.launch_server --model <your_glm_flash_id> --context-length 4096 - 我使用它的原因:低延遲流感覺靈敏,它與小路由任務配合得很好。
兩者都想要一個適當的模型路徑或HF repo ID。如果GLM-4.7-Flash不在您的默認索引中,您需要將其指向本地GGUF或兼容的權重格式。另外:匹配CUDA和驅動程序版本,否則您會追逐不透明的內核錯誤。我保持dtype為自動,只有在我知道我有VRAM空間時才強制fp16。
對於我的單用戶寫作會話,Ollama保持更簡單。vLLM/SGLang在我測試需要OpenAI樣式端點的工具時有意義。
故障排除
模型加載失敗
我看到了什麼:
- 加載期間”內存不足”。修復:切換到更小的量化(例如4位),降低num_ctx,或關閉GPU密集型應用程序。
- Windows上”沒有兼容的後端”。修復:更新GPU驅動程序;確保您沒有安裝僅CPU的PyTorch,如果您使用vLLM/SGLang;驅動程序升級後重新啟動。
- Ollama中找不到模型。修復:創建Modelfile和ollama create;或從確切的repo標籤拉取(如果存在)。
如果模型無聲地回退到CPU,標誌是風扇噪聲(或缺乏)加上慢得多的token/秒。我學會了在假設模型變”更差”之前檢查設備利用率。
慢推理修復
小改動比我預期的更重要:
- 正確調整上下文。將上下文減半通常比修改採樣更能加快速度。
- 預熱緩存。快速短運行改善下一個。
- 減少並行流。並發看起來有效,直到KV緩存絆倒您。
- 對於NVIDIA:設置高性能電源模式,關閉覆蓋應用程序,停止後台編碼器。
- 在macOS上:保持充電器插入:某些筆記本電腦在電池上會降速。
還有一個:我停止追逐最大token/秒。對我來說更好的指標是”首個可用的想法”。GLM-4.7-Flash在我保持提示集中和上下文合理時迅速提供了這一點。
 如果您喜歡GLM-4.7-Flash的速度,但不喜歡監管驅動程序、CUDA版本或後端怪癖,請嘗試WaveSpeed - 我們自己的平台專注於穩定、快速推理,無需低級調整。您獲得可預測的延遲,而不用擔心模型文件、量化格式或GPU兼容性。
如果您喜歡GLM-4.7-Flash的速度,但不喜歡監管驅動程序、CUDA版本或後端怪癖,請嘗試WaveSpeed - 我們自己的平台專注於穩定、快速推理,無需低級調整。您獲得可預測的延遲,而不用擔心模型文件、量化格式或GPU兼容性。





