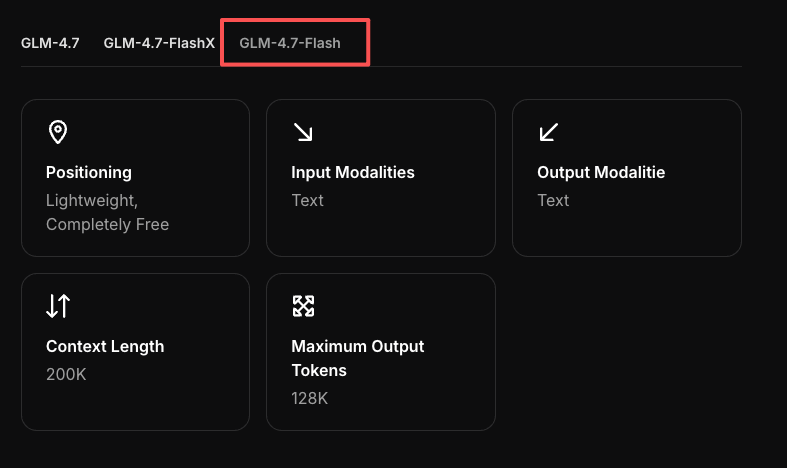
GLM-4.7-Flash API:聊天完成與串流快速入門

嗨,我是Dora。上週我遇到了一個小問題:一項草稿摘要任務感覺比實際需要的要沉重得多。我通常使用的工具要么太慢,要么聰慧得有些過頭。我需要一些快速且可預測的東西,即使它不是那麼花哨。
所以我好好試用了一下GLM-4.7-Flash API(2026年1月)。我不是在尋找「哇」的感覺。我想要乾淨的請求、快速的回應,以及行為符合其說法的設置。以下是我設置的內容、什麼有幫助、它在哪裡遇到困難,以及為什麼當我需要無戲劇速度時會再次使用它。
獲取您的API密鑰
我開始簡單:獲取一個密鑰、發出一個請求、看看基礎是否合理。我欣賞那些不隱藏控制項的API。作為背景,GLM-4.7-Flash是由Zhipu AI製作的更廣泛GLM模型系列的一部分,這決定了許多關於速度和可預測性的設計決策。

WaveSpeed儀表板逐步解說
我使用了WaveSpeed儀表板,它包裝了對GLM-4.7-Flash API的訪問。流程很簡單:
- 建立一個項目(我將其命名為「flash-notes」)。
- 生成一個伺服器密鑰和一個輕量級客戶端令牌。我在本地指令碼中只使用了伺服器密鑰。
- 瀏覽使用情況面板以發現默認速率限制。我的顯示了適度的突發上限和每分鐘配額,足以進行測試但不足以應對生產峰值。
我喜歡的一個小事情:儀表板顯示帶有時間戳的最近4xx/5xx錯誤。當我稍後達到限制時,我不必猜測。如果您進行團隊工作,基於角色的密鑰可見性會有所幫助:我將可寫密鑰保存在.env文件中,並在一週期間輪換一次以檢查撤銷是否有效(確實有效,並且是即時的)。
基本請求
我的第一個檢查點與我用於任何新模型的相同:一個簡短的提示、一個簡短的答案,JSON中沒有意外。
API模式遵循官方GLM-4.7 API指南中概述的相同聊天完成模式,這意味著我不需要重新學習請求語義。
curl示例
以下是對我來說始終有效的最簡單調用。端點名稱可能因提供商而異:這是我在測試期間使用的模式。
curl https://api.wavespeed.ai/v1/chat/completions \
-H "Authorization: Bearer $WAVESPEED_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "GLM-4.7-Flash",
"messages": [
{"role": "system", "content": "You are concise and helpful."},
{"role": "user", "content": "Summarize this in one sentence: GLM-4.7-Flash API quick test."}
],
"temperature": 0.2,
"max_tokens": 120
}'運行中的筆記
- 延遲: 在上午時段(美國時間)的小提示上,我看到第一個令牌約200–400毫秒。短回複的端對端完成時間不到一秒。
- 穩定性: 當流關閉時,回應每次都是格式正確的JSON。
- 成本: 我不能談論您的計畫,但令牌在使用日誌中清楚地報告。當您進行快速迭代時,這很重要。
Python示例
對於小指令碼,我更喜歡使用環境加載密鑰的單個函數。
import os
import requests
API_KEY = os.getenv("WAVESPEED_API_KEY")
BASE_URL = "https://api.wavespeed.ai/v1/chat/completions"
payload = {
"model": "GLM-4.7-Flash",
"messages": [
{"role": "system", "content": "You are concise and helpful."},
{
"role": "user",
"content": "Give me 3 bullet points on maintaining a calm writing workflow."
}
],
"temperature": 0.3,
"max_tokens": 180
}
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
resp = requests.post(BASE_URL, json=payload, headers=headers, timeout=30)
resp.raise_for_status()
data = resp.json()
print(data["choices"][0]["message"]["content"]) # typical OpenAI-style schema兩個小反應:
- 寬心: 模式與通常的聊天完成格式相匹配,這意味著沒有適配器層。我將其放入預先存在的工具中,只需最少的更改。
- 一個限制: 更高溫度下的更長輸出有時會變得冗長。這對「Flash」類型的模型是正常的:我使用
max_tokens進行修剪,並通過更緊密的系統提示調整語氣。
啟用流式傳輸
我只在實時塑造文本或當延遲比完整性更重要時才打開流式傳輸。GLM-4.7-Flash感覺就是為此而設計的:快速的第一個令牌,設置參數正確後穩定的分塊。
流參數設置
要啟用伺服器發送事件(SSE),我設置了stream: true。就這樣。其餘的是內務:確保您的客戶端讀取事件行並在[DONE]處停止。
我使用的curl版本:
curl https://api.wavespeed.ai/v1/chat/completions \
-H "Authorization: Bearer $WAVESPEED_API_KEY" \
-H "Content-Type: application/json" \
-N \
-d '{
"model": "GLM-4.7-Flash",
"messages": [
{"role": "user", "content": "Draft a two-sentence intro about quiet tools."}
],
"stream": true,
"temperature": 0.2,
"max_tokens": 120
}'兩個字段注意:
- 如果您忘記使用curl的
-N(無緩衝),流看起來可能會卡住。 - 如果您得到一個純JSON blob而不是事件,請仔細檢查
stream是否為布爾值true而不是字符串。
在程式碼中處理塊
在Python中,我逐行讀取、解析data:幀,並在哨兵處停止。此模式運行順利。
import os, json, requests
API_KEY = os.getenv("WAVESPEED_API_KEY")
BASE_URL = "https://api.wavespeed.ai/v1/chat/completions"
payload = {
"model": "GLM-4.7-Flash",
"messages": [{"role": "user", "content": "Write a calm closing paragraph."}],
"stream": True,
"temperature": 0.2,
}
with requests.post(
BASE_URL,
json=payload,
headers={
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
},
stream=True,
timeout=60
) as r:
r.raise_for_status()
for line in r.iter_lines(decode_unicode=True):
if not line or not line.startswith("data:"):
continue
data = line[len("data:"):].strip()
if data == "[DONE]":
break
try:
delta = json.loads(data)["choices"][0]["delta"].get("content", "")
print(delta, end="", flush=True)
except (KeyError, json.JSONDecodeError):
# Skip malformed or heartbeat frames gracefully
continue
print() # newline讓我有點驚訝的是:塊時序很穩定。我試了幾個更長的提示,仍然得到可預測的速度。流式傳輸不會在非常短的回複上節省牆鐘時間,但它減少了我的等待感,這在我直接在終端編輯時很重要。
參數參考
我每天只調整幾個旋鈕。使用GLM-4.7-Flash API,這些行為符合預期。
temperature / top_p / max_tokens
- temperature: 我將其保持在0.1到0.4之間以應對生產類型的任務。較低的數字給出了更緊密、想像力較少的措辭,這對摘要和支持文本很好。如果您漂移到0.7以上,則預期會有切線。
- top_p: 我將top_p留在約0.9。當我在低溫度下將其縮緊至0.6時,輸出感覺被剪裁,對要點很有用,對細微入微的寫作則不然。
- max_tokens: 這是我的護欄。對於短形式任務,150–250保持成本整潔並防止漫談。對於大綱,600–800就足夠了。如果模型提前停止,通常是這個原因,而不是錯誤。
當我需要清晰、事實的答案時,一個對我有效的小設置:
{
"model": "GLM-4.7-Flash",
"temperature": 0.2,
"top_p": 0.9,
"max_tokens": 200
}為什麼這在實踐中很重要:當您想要速度時,您不想要重寫。保守的溫度加上慷慨但不無限的max_tokens使我免於為了修剪措辭而必須運行相同調用兩次。
常見錯誤
 我在測試時在我身邊放了一個小筆記本。兩個錯誤出現得足夠頻繁,值得簡潔地提及。
我在測試時在我身邊放了一個小筆記本。兩個錯誤出現得足夠頻繁,值得簡潔地提及。
429速率限制
我看到的內容:
- 並行請求突發(5–10個一次)有時會觸發429。在新密鑰的第一分鐘時發生得更多。
什麼有幫助:
- 退避: 抖動指數延遲(例如,200毫秒、400毫秒、800毫秒,最多約3秒)清除峰值,無需我照看。
- 隊列: 將接近相同的提示合併到短批處理窗口(100–200毫秒)中,將我的峰值速率降低約30%,無需改變用戶體驗。
- 儀表板檢查: 使用情況面板確認我何時是問題。沒有謎團,我對此表示感謝。
誰會觸發此問題: 同時將GLM-4.7-Flash連接到UI預覽和伺服器掛鉤的團隊。如果重要,請向您的提供商詢問更高的每分鐘上限或使用輕量級內存隊列。
無效的JSON回應
我看到的內容:
- 當流打開時,某些客戶端嘗試將每個
data:幀解析為完整JSON。這不是SSE的工作方式。幀是部分的。 - 曾經,在連接嘈雜時,我得到了一個截斷的事件行,破壞了嚴格的解析器。
什麼有幫助:
- 保護您的解析器: 僅在
data:之後解析JSON,並期望它包含一個小的增量,而不是完整的消息。在[DONE]處停止。 - 超時: 保持合理的讀取超時,但避免因單個格式不當的幀殺死流。
- 如果您需要非流JSON:關閉流,您通常會得到乾淨的單個JSON對象。在我的運行中,非流模式從未產生格式不當的JSON。
還有一個小問題:如果您的代理或伺服器將日誌注入到標準輸出,它可能會污染流。將日誌與回應管道分開。
經過所有這些測試,我堅持WaveSpeed的原因非常簡單:我不想考慮管道。
 我們構建WaveSpeed是為了成為您的程式碼和GLM-4.7-Flash等快速模型之間無聊、可靠的層。乾淨的端點、可預測的行為,以及一個儀表板告訴您當事情出錯時實際發生了什麼——速率限制、錯誤、使用情況——無需猜測。
我們構建WaveSpeed是為了成為您的程式碼和GLM-4.7-Flash等快速模型之間無聊、可靠的層。乾淨的端點、可預測的行為,以及一個儀表板告訴您當事情出錯時實際發生了什麼——速率限制、錯誤、使用情況——無需猜測。
如果您正在將Flash連接到摘要、草稿、UI預覽或後台工作,只是希望它不干擾,那正是我們試圖填補的空隙。→ 點擊這裡!





