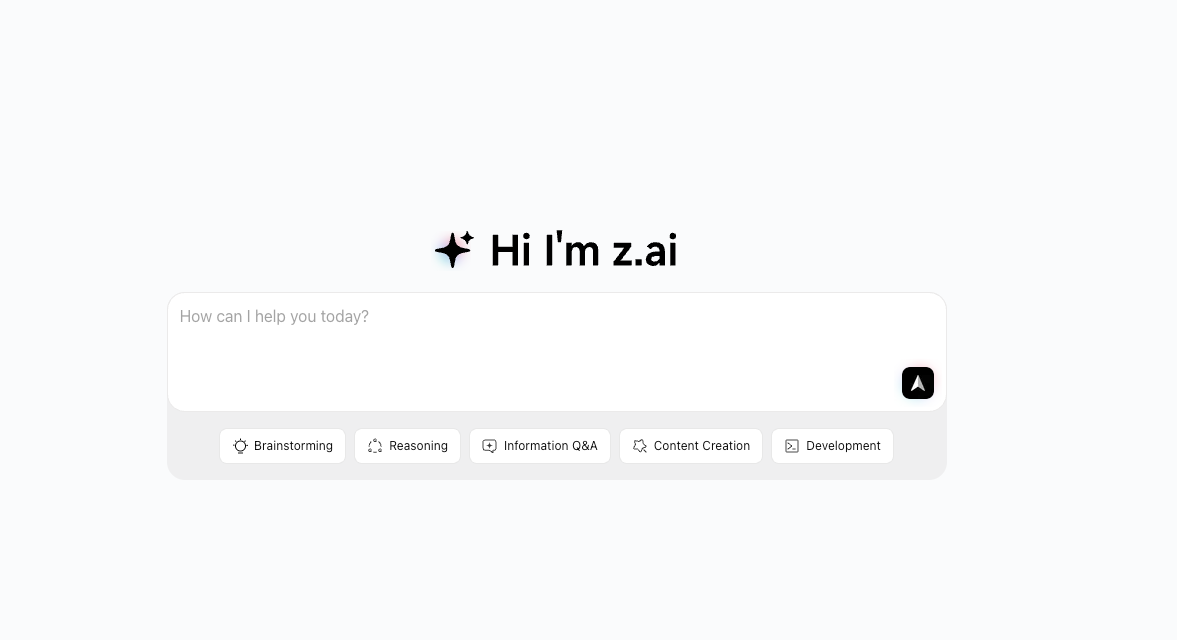
GLM-4.7-Flash:發佈日期、免費層級與主要功能 (2026)

嘿各位,我是Dora。
最近,GLM-4.7-Flash不斷出現在我信任的人的討論串裡,通常伴隨著一個不起眼的聳肩:“快得足以不礙事。“這句話說進我心坎。我現在不在追尋閃閃發光的模型:我在追尋能讓日常工作感覺更輕鬆的工具。你懂我的意思吧?
所以我在我的技術堆棧裡試用了GLM-4.7-Flash幾天(2026年1月20-21日)。簡短的提示詞、小型API腳本、幾個批次任務。沒什麼戲劇化的。我一直在思考的問題很簡單:這是實用的補充,還是另一個在時間軸上閃過的模型名稱?
GLM-4.7-Flash是什麼?
GLM-4.7-Flash是Zhipu AI的GLM-4.7系列推出的速度優先變體。把它想成是當你想要快速反應、低延遲生成而不需要重度推理開銷時會選擇的那個。它不是要在長篇基準測試或哲學辯論上取勝:它的目標是快速且便宜地返回不錯的答案。
製造者(Zhipu AI / Z.ai)
 Zhipu AI(也被看作Z.ai)是GLM系列背後的團隊。如果你用過早期的GLM模型,命名會感覺很熟悉:數字反映了世代,尾碼(Flash、Standard等)暗示了權衡。他們的文檔直率明瞭且經常更新:如果你在整合,請收藏Zhipu開發者入口網站上的官方API文檔。
Zhipu AI(也被看作Z.ai)是GLM系列背後的團隊。如果你用過早期的GLM模型,命名會感覺很熟悉:數字反映了世代,尾碼(Flash、Standard等)暗示了權衡。他們的文檔直率明瞭且經常更新:如果你在整合,請收藏Zhipu開發者入口網站上的官方API文檔。
過去一年我在需要多語言覆蓋和穩定、可預測輸出時不時使用過Zhipu模型。GLM-4.7-Flash延續了這個模式,只是更多地關注速度和吞吐量。
Flash vs Standard,定位
以下是我在實踐中感受到的差異:
- Flash:針對速度優化,每個請求的計算量較低,非常適合高容量端點、UI助手,以及批次分類或標籤。我發現它在簡潔提示詞和清晰結構下最開心。
- Standard(非Flash):在推理密集型任務上更慢但更穩定。如果我對Flash丟出多步分析,它試試看,但我能看出它為了保持低延遲而壓縮步驟。
如果你在兩者之間選擇,溫和的法則是:如果延遲和成本塑造了你的日常工作,從Flash開始。如果多跳推理的正確性是你的主要限制,Standard(或更大的推理調優同胞)可能會著陸得更好。你懂,選你的戰士。
官方發佈:2026年1月19日
Zhipu AI在2026年1月19日宣佈了GLM-4.7-Flash。我在隔天開始測試。版本背景對這些模型很重要:早期通常伴隨著快速迭代。如果你稍後讀到這個,請查看官方文檔中的發佈說明,確認對限制或行為的任何變更。
架構一覽
我不需要知道模型的內部來使用它,但某些細節幫助我估計成本以及它將在哪裡表現出色。
30B MoE,3B活躍參數
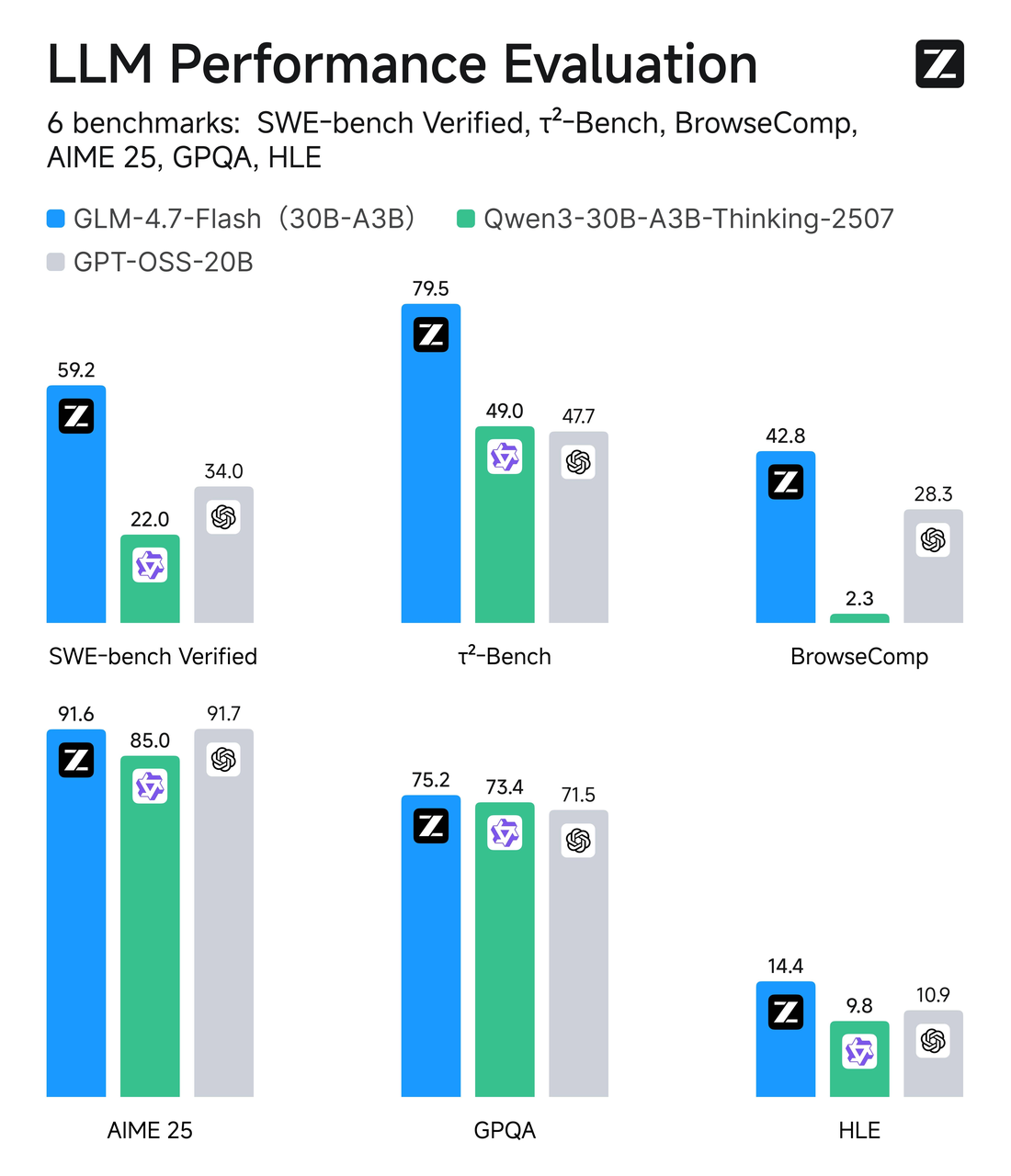 GLM-4.7-Flash使用專家混合(MoE)設計,總參數計數約30B,但每個令牌只有約3B專家處於活躍狀態。簡而言之:這是一個選擇性路由的寬模型。大多數情況下,網絡的只有一小部分處理你的令牌,這保持了推理的輕量化。
GLM-4.7-Flash使用專家混合(MoE)設計,總參數計數約30B,但每個令牌只有約3B專家處於活躍狀態。簡而言之:這是一個選擇性路由的寬模型。大多數情況下,網絡的只有一小部分處理你的令牌,這保持了推理的輕量化。
在實踐中,MoE通常給你一種”需要時更大的腦子”的感覺,而不總是付出全部計算代價。在我的測試中,這轉化為即使在負載下也能快速反應的輸出,以及比相似報告規模的密集模型更一致的延遲。這不是魔法,只是平衡容量和速度的聰慧方式。
MLA(多頭潛在注意力)
文檔提到了MLA(多頭潛在注意力)。我作為用戶的理解:這是一個注意力策略,旨在比經典完全自注意力更有效率,特別是在較長上下文下。我沒有在這裡推推長上下文限制:我的運行大多在幾千令牌下。儘管如此,記憶體足跡保持合理,當提示詞從”簡短”增長到”中等”時,我沒有看到通常的延遲緩慢下滑。
如果你在規劃檢索密集工作流或代理迴圈,MLA加上MoE是一個有用的信號:這個模型被設計來保持吞吐量up而不是追求最大單槍匹馬推理深度。
免費API — 包含什麼
免費存取脫穎而出。我在這裡很謹慎,因為免費層有時變化,有時每週。我分享的是我在2026年1月20-21日觀察到的,以及Zhipu文檔在發佈時建議的。發佈到生產環境前,始終再次檢查限制。
 簡言之:免費API讓我用合理的預設進行真實請求。我運行小任務而沒有在測試中途遇到付費牆。這降低了在實時腳本中試用它而不是從遊樂場試用的摩擦。
簡言之:免費API讓我用合理的預設進行真實請求。我運行小任務而沒有在測試中途遇到付費牆。這降低了在實時腳本中試用它而不是從遊樂場試用的摩擦。
速率限制和併發
我看到的:
- 併發:我可以舒適地從小型worker運行多個並行請求而不觸發錯誤。在我的測試中,5-10個並行呼叫保持穩定。當我尖峰更高時,我開始看到節流,這是免費層預期的。
- 吞吐量:簡短提示詞(分類、小型轉換)在亞秒到低秒範圍內返回。平均而言,我看到非常簡短響應的300-900毫秒和適度輸出的1.5-3秒。網絡差異適用。
- 安全:當我超過限制時,API用清晰的錯誤代碼回應。僅此一點就為我節省了時間,我不必猜測哪裡出錯了。
我沒有追尋精確的TPS上限:我的目標是看看小型管道是否能運行而不需要看管。它們可以。感覺像自由,老實說。如果你在規劃尖峰工作負載,用現實並發測試並構建簡單重試/退避。免費層一直很慷慨直到它們不是。
FlashX付費層級
Zhipu提到了一個”FlashX”付費選項,針對更高吞吐量和更可預測的性能。在這次運行期間我沒有將我的測試移動到FlashX,但以下是當你升級像這樣的提供者的層級時通常會改變的:
- 更高且保證的速率限制,節流更少。
- 每個鑰匙更多的並行請求,對於批次任務和面向用戶的助手很有用。
- 優先路由(較低尾部延遲)。當你關心最差5%的請求而不僅僅是中位數時,這很重要。
如果你在運送面向客戶的功能,FlashX是更安全的路線。如果你在修修補補,免費層足以獲得穩定性和整合工作的感受。你的里程數將取決於你的延遲預算以及你多頻繁地批次。
最佳使用案例
我試用了一些實際任務。沒什麼光彩的,只是在我一周裡出現的東西。
- 延遲殺死氛圍的界面助手。想想:行內重寫、小澄清、簡短跟進。GLM-4.7-Flash保持UI感覺即時。
- 批次文本轉換。我運行了一個小CSV(幾千行)進行語氣調整和類別標籤。模型保持一致並沒有在中途漂移。
- 起草支架。大綱、逐點擴展、簡單簡報。當我給它乾淨的指令時,它處理結構很好。就像有一個你不必賄賂的小幫手。
- 短上下文窗口的檢索總結。當我導入2-4個片段時,它乾淨地回應而沒有幻想奇怪的橋接。用長、雜亂上下文,它試著有幫助但有時壓縮太激進。
- “第一遍”代碼註解或文檔字符串。不是深度重構。只是澄清意圖和命名,快速且有用。
我不會使用它的地方:
- 多跳分析,其中精度比速度重要得多的邊界情況。我會接觸更重的推理模型。
- 長篇生成,其中你需要在數千令牌上保持穩定語氣和深度事實縫合。Flash可以做到,但感覺不合時宜。
為什麼這很重要:不會炸毀你預算的快速模型打開了你否則會削減的功能。如果你的產品每個會話需要數十個微小模型呼叫,削減的延遲和每個呼叫的較低計算加總。小贏,大回報。
💡 為了讓在真實工作流中運行GLM-4.7-Flash這樣的模型更容易和更可靠,我使用WaveSpeed — 我們自己的平台,處理API請求、併發和批次任務順利,所以你可以專注於結果而不是看管腳本。
試試WaveSpeed →
 來自壕溝的一個小注意:我的第一小時沒有更快。我修修補補了提示詞結構、溫度和最大令牌。經過幾次運行後,我找到了一個模式,簡短的系統提示詞、明確的輸出格式、清晰的限制。那減少了時間和心智力量。這不是魔法:這是設置。
來自壕溝的一個小注意:我的第一小時沒有更快。我修修補補了提示詞結構、溫度和最大令牌。經過幾次運行後,我找到了一個模式,簡短的系統提示詞、明確的輸出格式、清晰的限制。那減少了時間和心智力量。這不是魔法:這是設置。
還有誰開始了GLM-4.7-Flash(或任何Flash模型)的”快速10分鐘測試”並眨眼發現時鐘說午夜?扔出你的個人紀錄—以及最終讓它表現的一個提示詞調整—在評論中。





