5分鐘內建立AI主播:初學者數位人類建置指南

一份在 WaveSpeedAI 上建立數位人類的逐步教學。
前言
並非每個人生來就是天生的演說家,也不是每個人都樂於在眾人面前說話。
站起來說話可能會很緊張——但如果一個「虛擬的你」可以為你進行演講、直播或錄製你的宣傳讀白呢?你還會感到害怕嗎?
在 WaveSpeedAI 上,這已經不再只是個想法!你可以從零開始建立自己的數位人類,讓它用逼真的聲音和表情說出你的話語。
它不會怯場,永遠不會疲倦,你可以隨時隨地進行修改和重複使用。它是你工作和生活中可靠的夥伴。
在這個教學中,我們將逐步引導你從零開始建立一個簡單的數位人類。我們使用的模型只是開始——請盡情探索更多功能和風格,使你的數位人類獨一無二。
在 WaveSpeedAI 上,我們的模型生成清晰、穩定的視覺效果,邊界自然流暢,可以直接用於展示。它們非常適合正式的談話頭像片段、隨意的對話和產品講解。
圖像生成
一個英俊、可愛和自然逼真的數位人類能為觀眾提供更好的體驗。它也會為你的頻道吸引更多的關注和流量。
你也可以直接從個人照片建立一個。如果你已經有合適的照片準備好,可以跳過這個部分。
我將以 bytedance/seedream-v4 為例,幫助你創作一個獨特的虛擬化身。
在 WaveSpeedAI 上搜尋 bytedance/seedream-v4 —— 這是一個文本轉圖像模型。現在,讓我們輸入提示詞來創建你自己的數位人類:
Half-length portrait of a young female digital human (22–28),
natural makeup, white shirt and light gray blazer,
looking at camera, soft studio light,
plain light-gray background, ultra realistic, 4k, 85mm, f/2.8
你可以自訂性別、服裝和背景 等元素來滿足你的需求,創造出各種風格和氛圍,讓你的數位人類感覺更吸引人和符合品牌形象。
語音生成
現在你的數位人類已經準備好了,下一步是草擬清晰的旁白腳本,使其能「說話」自然。
在 WaveSpeedAI 上,進入 分類 > 文本轉音頻 來探索各種模型。我們提供自然旁白、語音複製甚至歌曲創作的模型。
在本章節中,我們將使用 minimax/speech-02-hd 作為示例。請隨時嘗試其他模型,探索不同的語音風格和效果。
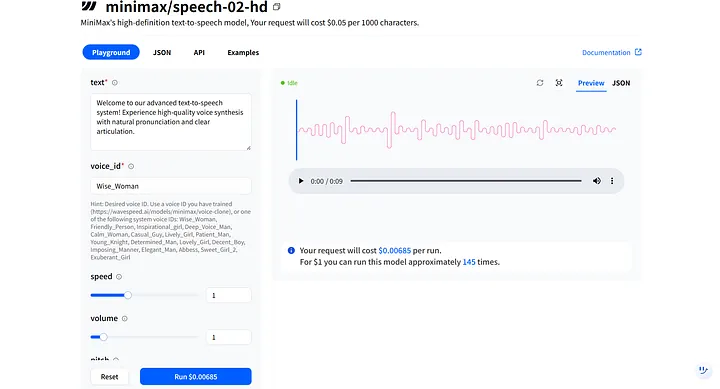
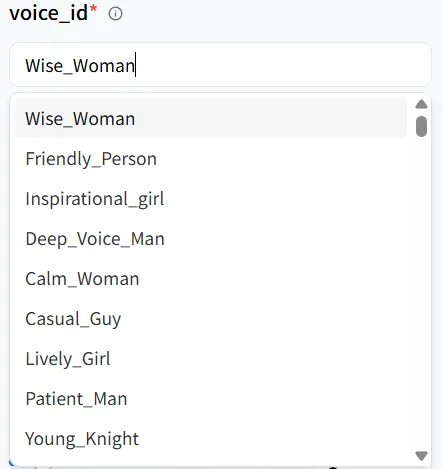
在模型的 Playground 中,你會看到關鍵參數,如 text 和 voice_id。這些參數協同工作,形成你的數位人類的音調和音質,你可以調整它們以適應不同的場景。例如,我創建的數位人類是女性,所以我可以選擇第一個語音選項 Wise_Woman。
關鍵參數
速度
speed 控制你的數位人類說話的快慢。選擇適合場景的節奏——例如,產品介紹時放慢一點,隨意交談時加快。值為 1 表示正常速度。

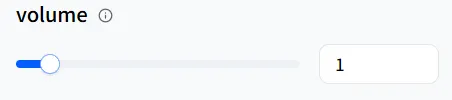
音量
volume 設定音量大小。如果你的數位人類在講述睡前故事,你可以降低 speed 來放慢速度,並降低 volume 以實現更柔和的表達。值為 1 是預設音量。
音高
pitch 調整語音的音調。調整此參數可使語音聽起來更明亮清晰或更深沉飽滿。值為 0 是預設音高。

情感
emotion 控制你的數位人類的說話風格。選擇與場景相符的語氣——這裡,我們將選擇 happy。
英文正規化
english_normalization 選項啟用時,使英文中的數字和符號在語音中聽起來自然。不啟用時,系統可能會逐個讀出數字(例如,「123」讀作「one two three」),而不是「one hundred and twenty-three」。

樣本速率
sample_rate 決定音頻品質(解析度)。如果你在製作 ASMR 風格的內容,應該選擇更高的樣本速率以獲得更豐富的細節。對於本教學範例,這不是關鍵——保留預設值就完全可以了。
位元率
bitrate 決定你的音頻檔案的品質和大小。它代表每秒處理的位元數。較低的位元率會產生較小的檔案,但可能會損失細節;較高的位元率會產生較大的檔案,但聲音更清晰。
聲道
channel 參數決定生成的音頻聲道數。
- channel = 1(單聲道): 所有聲音混合到單一聲道——適合電話語音、通話錄音或不需要空間寬度的對話內容。
- channel = 2(立體聲): 聲音分為左右聲道,創造寬度和空間感,提供更沉浸和分層的體驗——適合音樂、電影、遊戲和需要更高聆聽品質的視頻旁白。
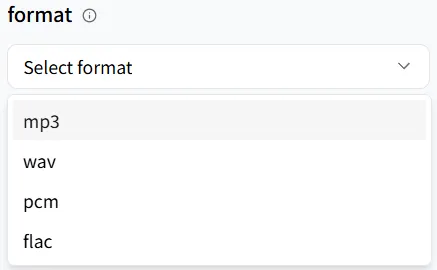
格式
format 允許你選擇輸出音頻檔案類型(我們在這裡跳過詳細說明)。
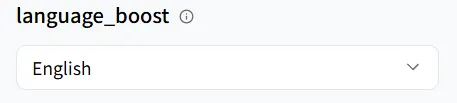
語言增強
language_boost 改善模型對你選定語言的理解。對於本教學,選擇 English。
生成音頻
接下來,貼上你的腳本並點擊 Run 來生成音頻!
Welcome to WaveSpeedAI’s Digital Human Tutorial. We’ll spark fresh ideas in AIGC and show you practical steps. Let’s unleash your creativity together!
下載音頻檔案——這是讓你的數位人類稍後能夠說話的關鍵部分!
讓數位人類說話
最後,令人興奮的時刻到了:我們將讓你的數位人類真正地說話!
在 WaveSpeedAI 上搜尋 wavespeed-ai/infinitetalk——我們專為數位人類旁白設計的高品質模型。
在模型的 Playground 中,你會看到兩個必需的輸入:audio 和 image。
- audio:上傳你剛下載的旁白檔案。
- image:上傳你之前生成的數位人類圖像。
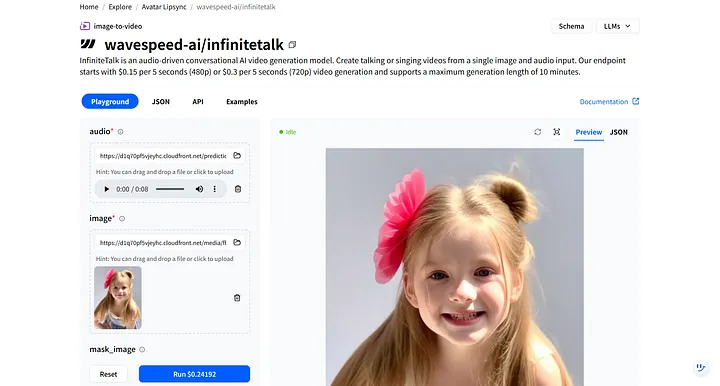
點擊 Run 後,數位人類將對音頻做出反應,並自動同步唇形和面部表情。
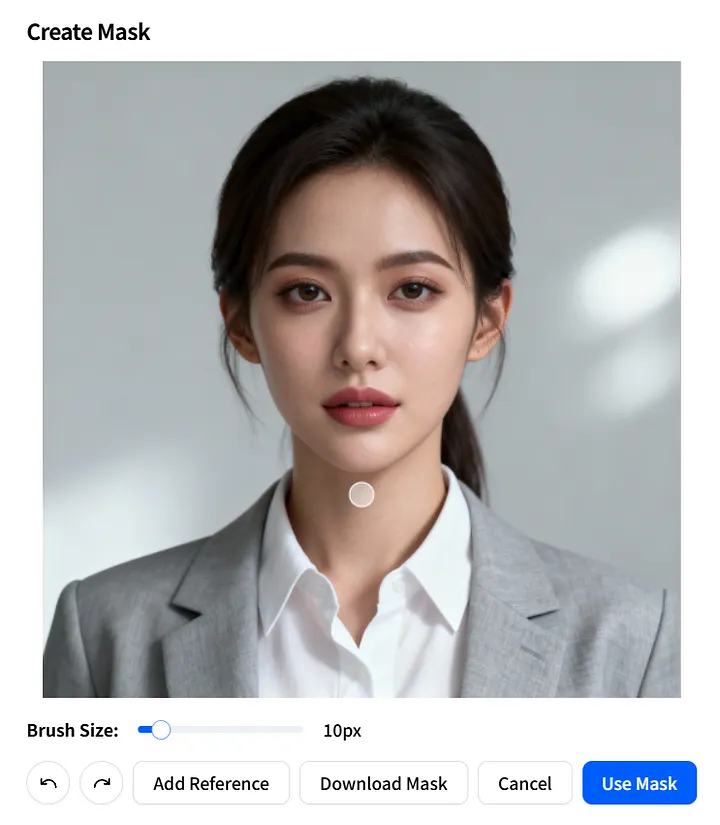
遮罩圖像參數
接下來,讓我們看看 mask_image 參數。它允許你指定圖像中的哪些部分應該被動畫化。
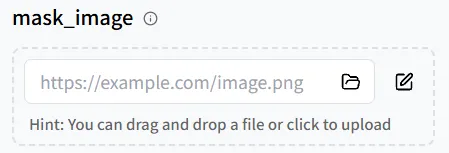
在 Create Mask 頁面上,準確定義可移動區域:調整 Brush Size,在你想動畫化的區域繪製,然後點擊 Use Mask 來應用。
你也可以點擊 Download Mask 來將 mask_image 儲存為範本,以便在未來的項目中快速重複使用。
額外自訂
如果你有額外的需求——例如指定姿勢、手勢或凝視方向——在 prompt 中添加更具體的指示。
為了方便重複,設定一個固定的 seed 值。這確保隨機性是一致的,所以你稍後可以重現相同的結果。
最後,點擊 Run,讓我們期待最終結果吧!
恭喜!你已經擁有自己的數位人類了!
準備好進階到多人場景 了嗎?WaveSpeedAI 也提供了專門的模型來實現這點。讓我們一起探索它們吧!
多人發言者生成
在 WaveSpeedAI 上,搜尋 wavespeed-ai/infinitetalk/multi。其步驟基本上與單人模型相同。
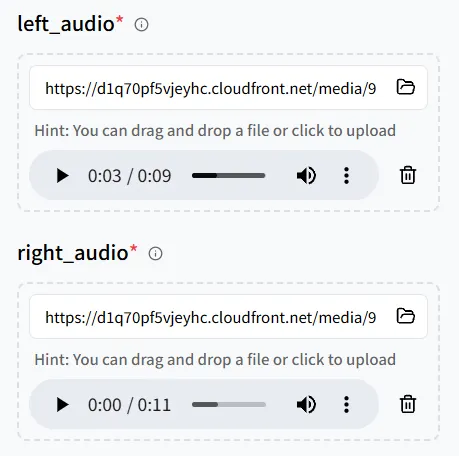
這次,添加兩個音頻檔案,然後上傳一個** 包含兩個數位人類的圖像**,以便兩個角色都能說出他們的台詞。
密切注意音頻和圖像上位置的配對:
- left_audio → 圖像中** 左邊**的人
- right_audio → 圖像中** 右邊**的人
仔細檢查映射;否則,聲音可能會被連接到錯誤的角色。
說話模式
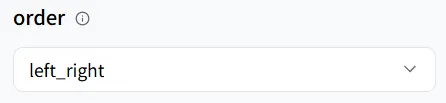
在 wavespeed-ai/infinitetalk/multi 模型中,它支持三種說話模式:
- left_right(由左至右)
- right_left(由右至左)
- meanwhile(同時說話)
同樣地,使用此模型,你可以通過 prompt 添加你想要的細節,並設定 seed 以便於重複。
就這樣,你擁有了一個雙人旁白秀!
其他模型
在 WaveSpeedAI 上,我們還為你提供許多額外的模型:
- wavespeed-ai/multitalk:完美適合「歌曲風格的數位人類」,支持多部分聲樂和更富表現力的演出。
- wavespeed-ai/infinitetalk/video-to-video:為現有視頻添加旁白或敘述,使視覺效果和音頻自然地保持同步。
- wavespeed-ai/song-generation:從零開始創作音樂,為你的內容設計自訂配樂和氛圍。
這些模型也提供了在其他平台上難以複製的獨特體驗。大膽嘗試——試試它們並分享你的作品!你可以在 Inspiration 部分發布與其他創作者互動和交流!

最後的思考
我們的世界在快速變化,AI 正越來越多地影響我們的日常生活。堅守舊方法只會增加成本、減緩進度並冒著錯失新機會的風險。
現在正是採用新技術並享受其便利和效率的完美時機。WaveSpeedAI 以可靠的技術和不斷成長的生態系統為你的內容創作提供長期支持。
無論你的創意引領你走向何方,WaveSpeedAI 都將作為你可靠的基礎和信任的夥伴而存在。
相關文章

Seedance 2.0即將推出:字節跳動下一代視頻模型,具有原生音頻功能

Seedance 2.0 完整指南:多模態視頻創建

Seedream 5.0-Preview 完整指南:智能圖像生成

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image:完整比較

Vidu Q3評測:與Sora 2、Wan 2.6、Seedance 1.5、Veo 3.1和Grok Imagine Video的對比
