DeepSeek V4 1M Token Context:如何提示整個程式碼庫

嘿,各位朋友。我是 Dora。當我第一次把一個完整的項目丟進 DeepSeek V4 的 100 萬 token 窗口時,我並沒有感到強大。我感到謹慎。一百萬 token 聽起來像是源源不絕的咖啡,但任何嘗試過靠著咖啡因注射思考數小時的人都知道邊界會變得模糊。我想看看這個新的上下文大小是否會真正改變我的工作方式,還是只會鼓勵我粘貼更多內容。
我花了幾天(2026 年 1 月 27-30 日)使用 DeepSeek V4 100 萬 token 來完成三項我經常遇到的任務:
- 閱讀中等規模的 monorepo,無需在本地設置
- 追蹤跨越相互通信的服務的 bug
- 要求重構建議,但不會破壞測試
我學到的是:你可以容納很多東西,但模型仍然需要你在地圖上指出位置。收益不是來自於塞入更多文件:而是來自於我如何組織提示,以及我如何要求模型通過它移動。
100 萬 Token 實際上意味著什麼
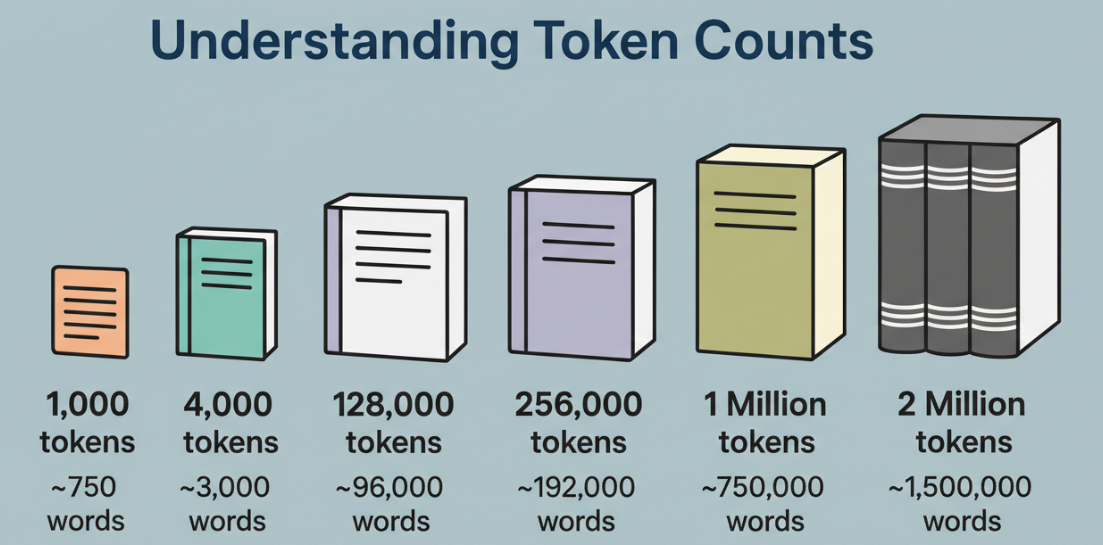 我不關心這個數字本身。我關心的是它在清晰頭腦下能容納什麼。
我不關心這個數字本身。我關心的是它在清晰頭腦下能容納什麼。
token 不是一個詞。它是一個塊,有時是一個完整的詞,有時是其中的一部分,有時是標點符號。在英文文本中,我通常將 1 個 token 視為約 0.75 個詞來進行粗略規劃。對於代碼,token 來得很快:括號、點、方法名稱,全部被切割。一百萬個 token 是很多的領域,但它不是無限的注意力。
這週對我改變的是:我停止了積極的修剪。使用 128K 上下文時,我會積極地總結,只保留熱路徑。使用 1M 時,我可以保留熱路徑加上「冷」文件,這些文件往往會在後面讓我感到驚訝(配置、遷移、構建腳本、工作流粘合)。話雖如此,如果我一次性傾倒所有內容,答案會變得模糊。當我分階段餵給模型時,有明確的標誌,輸出感覺更加扎根。
代碼行數等效
我在工作時使用的粗略數學:
- 許多 repo 混合代碼和文檔。在代碼密集的文件夾中,我在密集語言中看到約 2-3 個 token 每字符,但一個實用的快捷方式:簡單行大約每行 4 個 token,真實世界的行有縮進、名稱和註釋時約 8-12 個。
- 按照這個速度,1M token 大約容納 80K-150K 行代碼,取決於風格和語言。帶有註釋和 lint 友好命名的 TypeScript 服務位於較高一側。縮小的 bundle 會爆炸計數,不值得包含。
在實踐中,我的「安全範圍」是約 60K 行有意義的源代碼 + 目標文檔和測試。我可以走得更高,但延遲會增加,答案會變軟。你的里程會因 tokenizer 規則和語言混合而異。
vs 當前模型(128K)
從 128K 跳到 1M 的感覺不像是一個更大的背包,更像是帶著一個滾輪箱。你可以攜帶更多,但你不會衝刺。
我注意到的:
- 延遲:整個上下文提示花費的時間明顯更長。當我分塊會話(分階段)時,延遲感覺可控。
- 回憶:使用 128K 時,模型經常「忘記」早期的文件,除非我重複了關鍵部分。使用 1M 時,它沒有忘記,但有時它會泛化而不是引用具體內容。當我要求它引用文件路徑和行範圍時,我的運氣更好。
- 精度:上下文越大,你越需要在提示中進行索引行為。否則,你會得到能幹的摘要,避免了你實際關心的凌亂邊界情況。
如果你希望 1M token 意味著「不再需要提示工程」,我不會指望它。它轉變了你進行的轉向類型。
大型代碼庫的提示結構
 我停止將提示視為消息,開始將其視為閱讀計劃。模型現在可以閱讀很多,但它仍然受益於目錄和軌跡。
我停止將提示視為消息,開始將其視為閱讀計劃。模型現在可以閱讀很多,但它仍然受益於目錄和軌跡。
對我最有效的看起來像這樣:簡短的系統框架、簡潔的項目索引、聲明的探索順序,然後是一個具體的任務。然後我進行多輪對話,而不是一個巨大的提示。
文件排序
當我告訴模型首先、其次、第三個打開什麼時,我得到了更可靠的答案。頂部的單個列表幫助它構建了一個精神堆棧:
- 從入口點開始(CLI、HTTP 處理器、作業)。它錨定了流程。
- 然後是組合層(DI 容器、main.ts、app.py),依賴項在其中連接。
- 接下來,核心域模塊及其接口。
- 只有然後:幫助器、utils 和跨領域的部分(日誌記錄、遠測、配置)。
- 測試最後,除非我在調試特定的失敗,在這種情況下,從失敗的規範開始以設置期望。
我還為看起來重要但不是的文件夾包含了「不要閱讀」的說明:生成的代碼、編譯的資產、快照。它節省了 token,並將模型的注意力集中在活代碼上。
一個小技巧:我要求模型維護「活文件」的滾動列表(路徑和簡短摘要),並隨著我們移動而更新它。當它漂移時,我可以指向該列表說「現在stay 在這個集合內。」這保持了答案的具體性。
依賴關係映射
最有用的一次通過是很早就要求依賴關係圖,不是作為圖表,而是作為一個簡單的邊表:模塊 A 導入 B,B 使用 C,C 命中環境變量,等等。我保持它簡潔和簡潔。
這在實踐中做了什麼:
- 它暴露了流浪依賴項(那些跨越文件夾的關注點的類型)。
- 它給了我一個「壓力點」的簡短列表,可以在任何重構之前審查。
- 當我要求更改時,它幫助模型引用正確的位置。
我還讓模型陳述假設,它從命名、註釋或測試中推斷什麼。當一個假設偏離時,我一次糾正它,後來的步驟保持得更清潔。
一個警告:一次性在大型 repo 上要求完整的依賴關係圖導致超時和模糊的圖形。我通過按層限制範圍(例如,只有數據訪問、只有 HTTP 處理器)獲得了更好的結果,然後自己合併筆記。這花了額外的 10 分鐘,但在準確性上有所回報。
需要時的分塊策略
 即使有 1M token 窗口,我仍然分塊。不是因為它不適應,而是因為我的思考在階段中更好,當我縮小視野時,模型的回答更精確。
即使有 1M token 窗口,我仍然分塊。不是因為它不適應,而是因為我的思考在階段中更好,當我縮小視野時,模型的回答更精確。
本週堅持的幾種模式:
- 分階段簡介:我從小上下文、項目索引、任務、已知的約束開始,然後要求閱讀和驗證計劃。只有在那之後,我才按照我們同意的順序餵入代碼。
- 限制活動集:對於重構,我只保留了 5-12 個文件正在進行中,並要求進行明確路徑的更改。如果編輯涉及共享實用程序,我在下一個轉合中添加該文件。模型保持得更緊。
- 在邊邊總結:在移動到新文件夾之前,我要求簡短總結我們學到的東西和任何不確定性。這些摘要在轉合中充當麵包屑,無需重新粘貼每個文件。
- 有目的地使用檢索:對於不適合舒適的 repo,我使用嵌入按查詢調用文件(「付款 ID 規範化」、「重試退避」)。我保持每個轉合的檢索集很小,通常在 40K token 以下,所以回復不會模糊。
- 向前驗證,不向後:不是問「你用了我粘貼的一切嗎?」我問「指向你的建議所依賴的具體函數和行。」那強制具體引用並使錯誤明顯。
我遇到的摩擦:
- 當你每轉合發送完整上下文消息時,延遲會爬升。分階段將我在相同任務上的平均響應時間從 70-90 秒減少到 20-40 秒。
- 成本很重要。大提示相加。我通過修剪重申明顯的註釋、刪除編譯的工件和跳過供應商 bundle 來節省 token。
- 位置效應是真實的。巨大提示開始或結束的內容往往更「可用」。我通過在每個轉合的結尾重複微小的、關鍵的約束來對抗這一點。
誰受益於 1M 窗口?

- 如果你生活在 monorepos 中,處理審計,或進行跨領域的重構,它為你購買的設置步驟更少,本地索引開銷更少。這是一個更平靜的起點。
- 如果你的工作主要集中在小型服務中的 bug 修復,額外的容量不會幫助太多。一個較小的上下文加上一個緊密的檢索管道會感覺更快。
關於信任的說明:我要求模型為風險更改引用精確的代碼行(遷移、auth)。當它猶豫或改寫時,我將其視為縮小範圍或再次粘貼特定文件的標誌。這個小習慣防止了幾個近距離錯誤。
如果你想要模型限制或 tokenizer 行為的正式描述,請檢查提供商的文檔。當我需要具體內容時,我回到了官方模型卡和上下文窗口筆記。它讓我對我要求模型做什麼誠實。
這不是魔法。它只是一個更大的桌子。如果你安排椅子,很有用。
我一直在想星期二的一件小事:我要求一個修復,模型建議改變一個看起來一目了然的函數。它沒有。bug 位於兩層下的幫助程序中。一百萬 token 沒有改變那個。我的筆記改變了。





