停止训练,开始创作:在WaveSpeedAI上使用LoRA


介绍
什么是LoRA?可以把它看作一种轻量级微调方法:与其重新训练整个模型,你只需简单地向现有模型添加一个小的”快速适应”层来锁定你自己的风格——更快、更便宜。
在本教程中,我们将从零开始,向你展示如何在线查找你喜爱的LoRA模型,以及如何在WaveSpeedAI上使用它们。即使你是新手,你也会很快上手。
模型选择
使用AIGC创建图像和视频时,我们通常只能通过提示词来控制模型,这使得很难管理细节。如果你依赖模型”自己理解”手部姿态、布料褶皱或服装元素等事物,结果往往不尽人意。
此时,你可以探索开放平台 来查找创作者分享的LoRA模型。从整体艺术风格和相机纹理到特定的姿态、服装和微小配饰。有针对性的LoRA可以增强细节并给你更多控制——无需重新训练模型。
但是,在选择LoRA时请记住一条重要规则:它必须完全 匹配你使用的AIGC基础模型。相同的模型名称、相同的版本,以及** 相同的参数大小**。
例如,为Wan 2.2设计的LoRA无法用于Wan 2.1或任何其他模型。同样,Wan 2.2 14B LoRA无法用于Wan 2.2 5B。
如果这些不匹配,风格可能会在最好的情况下偏移。在最坏的情况下,你可能会遇到错误。在使用前始终仔细检查模型页面上的信息!
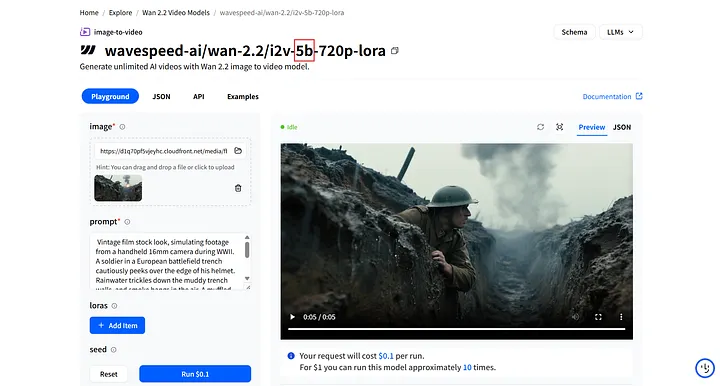 双重检查版本和参数
双重检查版本和参数
P.S. 在WaveSpeedAI上,LoRA从单个**.safetensors** 文件运行。只需导入它即可。避免**.PickleTensor、.zip、.GGUF** 等,因为WaveSpeedAI不支持这些格式。
注意文件大小。LoRA通常小于2 GB(通常只有几百MB)。如果你上传的文件明显更大,你可能选择了错误的文件(例如完整的基础模型或压缩包),导入将失败。在重新尝试之前,仔细检查文件名和扩展名!
以下是两个常用平台:Civitai和Hugging Face。
 Civitai平台
Civitai平台
 Hugging Face平台
Hugging Face平台
Hugging Face上的LoRA
Hugging Face是世界上最大的开源模型库之一,提供大量模型和数据集。你可以搜索LoRA并找到流行基础模型的官方权重和推理指南。
在本部分中,我们将专注于LoRA——如何定位它、在Hugging Face上选择它,以及在WaveSpeedAI上使用它。
首先,在网站顶部的搜索栏中输入LoRA 以查看相关存储库。
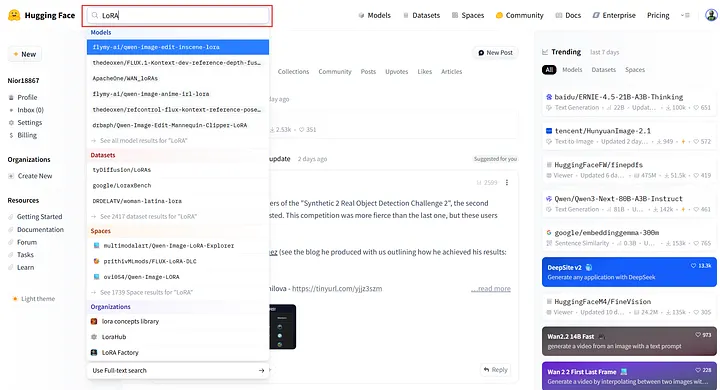 搜索LoRA
搜索LoRA
接下来,点击查看”LoRA”的所有模型结果 以查看完整的LoRA结果页面。
对于你自己的搜索,包括基础模型名称、版本和参数大小等限定词(例如,7B/14B)。这样可以缩小搜索范围并显示更相关的结果。
 模型结果页面
模型结果页面
在Hugging Face上,LoRA模型通常在标题或描述中指定兼容的基础模型和参数大小。
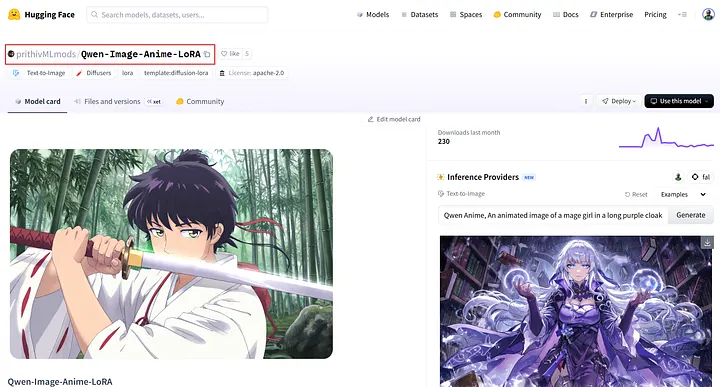
例如,prithivMLmods/Qwen-Image-Anime-LoRA是为Qwen-Image 创建的LoRA,用于生成日本动画风格 的图像。
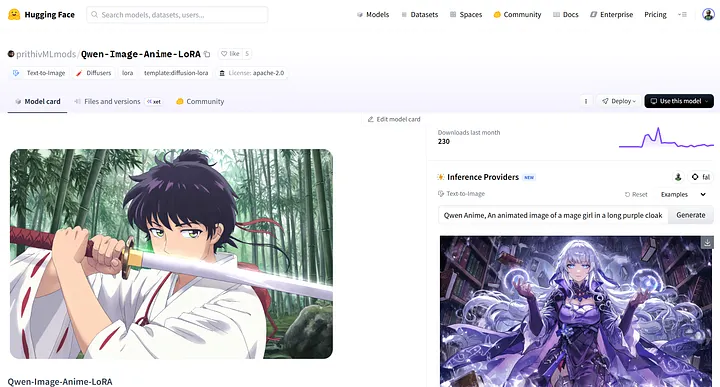 prithivMLmods/Qwen-Image-Anime-LoRA
prithivMLmods/Qwen-Image-Anime-LoRA
如页面所示,Qwen-Image-Anime-LoRA 由prithivMLmods 发布,专门为Qwen-Image 基础模型设计。
接下来,切换到WaveSpeedAI 并打开wavespeed-ai/qwen-image/text-to-image-lora模型。我们将使用它来加载并运行这个LoRA。
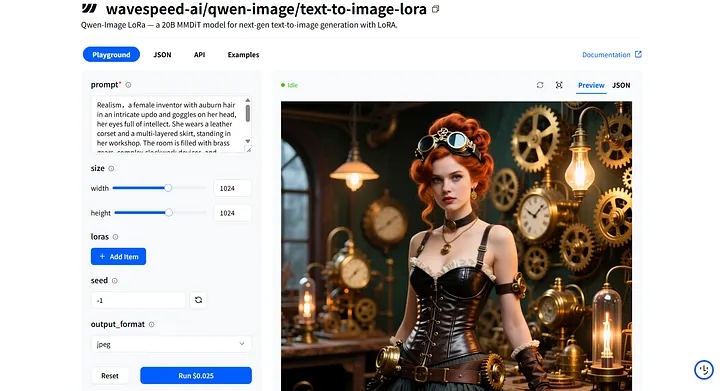 wavespeed-ai/qwen-image/text-to-image-lora
wavespeed-ai/qwen-image/text-to-image-lora
在模型的Playground页面上,你会找到prompt 输入字段来输入你的提示词,以及用于添加LoRA模型的loras 部分。
编写提示词时,除了清楚地描述你想要的场景、风格和细节外,记得包含LoRA的触发词!你通常可以在Hugging Face页面的Model Card 中找到这些信息。
例如,在prithivMLmods/Qwen-Image-Anime-LoRA 模型页面上,向下滚动Model Card 以查找其他详细信息,例如如何使用模型和所需的确切触发词。
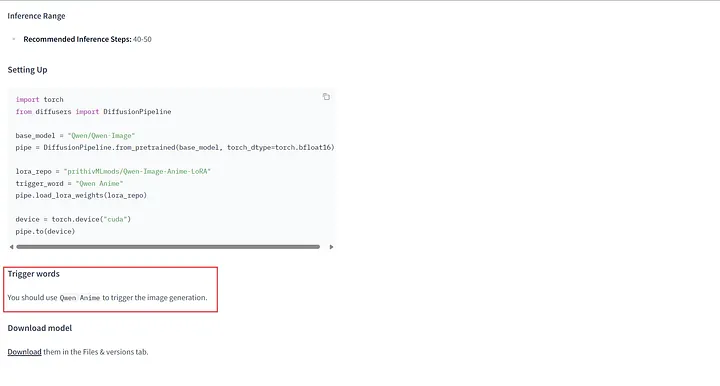 Model Card中的触发词
Model Card中的触发词
之后,我们将修改与LoRA模型相关的参数。
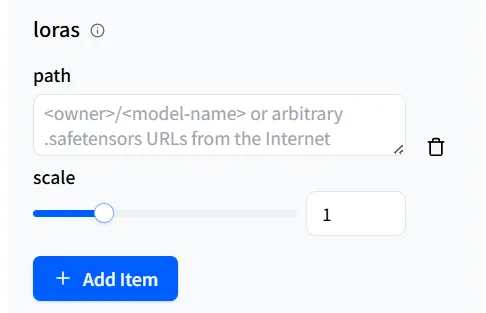
首先是path。这是WaveSpeedAI用来调用你想要的LoRA模型的路由。
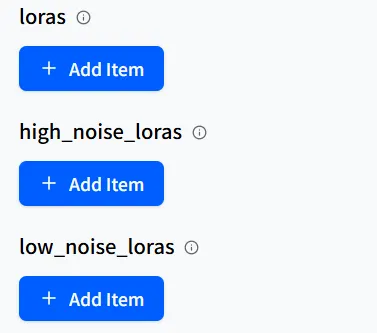
点击**+ Add Item** 以显示输入字段。qwen-image/text-to-image-lora管道允许添加最多三个LoRA模型。
此外,如果LoRA模型托管在Hugging Face上,WaveSpeedAI提供两种方式来引用它:一种是**<owner>/<model-name>**。
就像这个例子一样,作者名称加上模型页面上显示的模型名称。
 复制这个并粘贴到路径中!
复制这个并粘贴到路径中!
另一种方法是转到模型的Files and versions,右键单击下载图标,选择Copy link address,并将复制的URL粘贴到path 中。
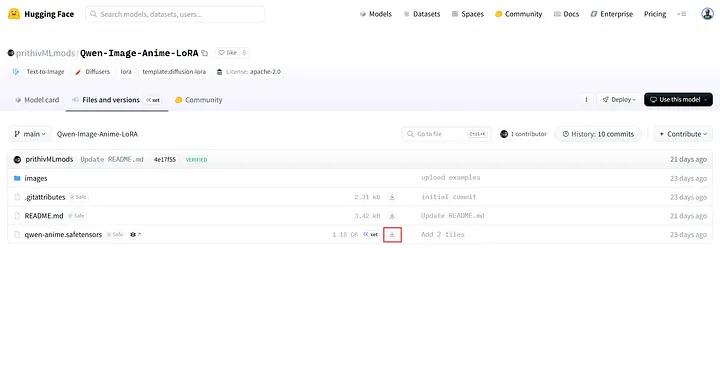 Files and versions中的下载按钮
Files and versions中的下载按钮
有时你可能会在模型页面上看到high-noise LoRA 和low-noise LoRA 选项。这些通常不常用,但Hugging Face通常会提供有关它们的详细信息。
只需使用匹配的名称填充LoRA模型到相应的字段中,就像普通LoRA一样,它就会工作良好。
在loras 参数设置中,有一个名为scale 的滑块,你可以将其视为”影响/浓度”音量旋钮。它调整LoRA对基础模型的影响强度。
在大多数情况下,默认值1 会给你很好的结果。如果结果与你的预期不同,你可以稍微增加scale。

Seed 用于控制随机性。可以将其视为”起始索引”。
当你使用相同的种子然后调整提示词时,整体风格和构图将保持大致一致。只有你在提示词中更改的部分才会不同,使比较和复现更容易。
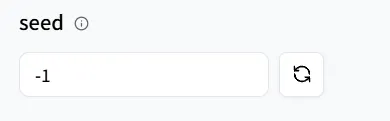
太好了!你已经完成了所有准备工作!让我们开始使用LoRA模型!
在提示词字段中,首先输入LoRA模型的触发词Qwen Anime。然后提供你想要生成的结果的描述。
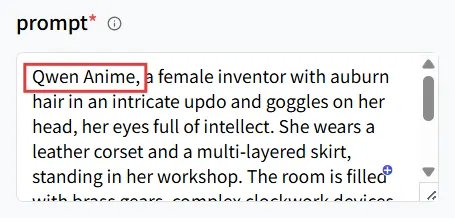 输入触发词
输入触发词
然后,在loras 字段中,在path 中,输入prithivMLmods/Qwen-Image-Anime-LoRA 或其URL,并保持scale为1。
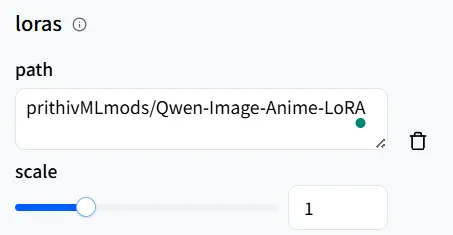 设置路径
设置路径
然后设置seed,这样你以后可以轻松复现任何你想要的结果。
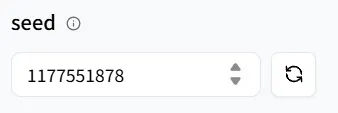 随机种子号
随机种子号
最后,点击Run 按钮生成动画风格的图像!
 结果
结果
既然我们已经提前设置了种子,如果你对背景和风格细节(例如服装)感到满意,但想改变角色的性别,只需编辑提示词并再次点击Run。
 你知道吗,我只是想比较结果
你知道吗,我只是想比较结果
看起来怎么样?你能看到变化吗?自己试试!WaveSpeedAI有许多可以调用LoRA的基础模型。随时尝试,然后在Inspiration中与我们和更广阔的创意社区分享你的作品!
 灵感页面
灵感页面
Civitai上的LoRA
Civitai 是一个专注于创意者的社区,共享模型,提供各种各样的LoRA资源。你可以按风格或主题搜索、浏览示例结果和参数,并快速找到合适的模型。
 Civitai页面
Civitai页面
Civitai上的搜索方法类似于Hugging Face:在搜索框中输入模型版本和参数大小等详细信息。添加关键词”LoRA”快速过滤大量相关模型(例如:“Wan 2.2 14B LoRA”)。
基本用法类似于在Hugging Face上调用模型,所以我们只会详细解释区别。
以游戏设计为例,如果你想创建一个风格类似于Baldur’s Gate 3 的角色,你可以直接尝试LoRA [[WAN2.1] Baldur’s Gate 3 [STYLE]]([WAN2.1] Baldur’s Gate 3 [STYLE])。
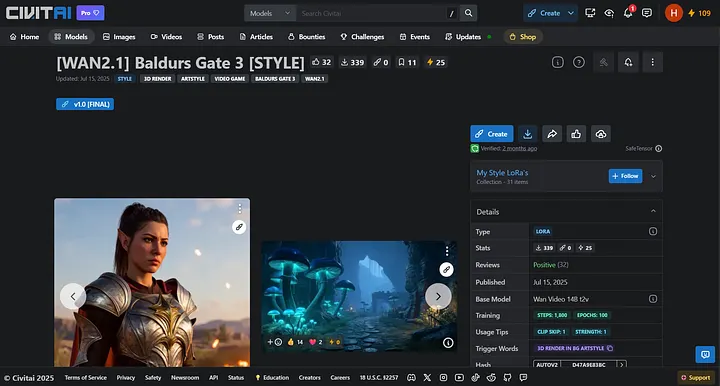 [WAN2.1]Baldur’s Gate 3 [STYLE]页面
[WAN2.1]Baldur’s Gate 3 [STYLE]页面
但请注意,对于Civitai平台上的模型,WaveSpeedAI不支持使用<owner>/<model-name>格式调用LoRA模型。
它们只能通过URL 调用。因此,在调用前一定要查看模型信息。
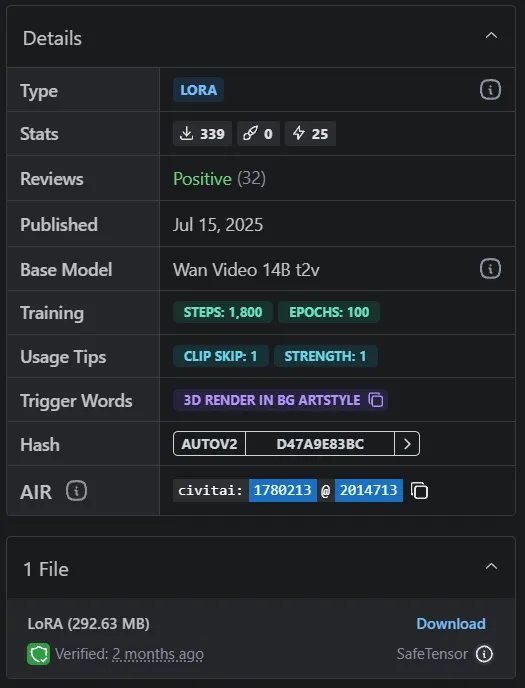 LoRA模型详情
LoRA模型详情
在模型的Details 部分,你可以看到有关模型的各种信息。
主要关注的项目是Base Model 和Trigger Words。在这里,我们看到这个LoRA的基础模型是Wan Video 14B t2v,触发词是** 3d render in bg artstyle**。
打开WaveSpeedAI并查找wavespeed-ai/wan-2.1/t2v-720p-lora。当然,你也可以选择其他支持调用LoRA的模型(例如wavespeed-ai/wan-2.1/i2v-720p-lora)。
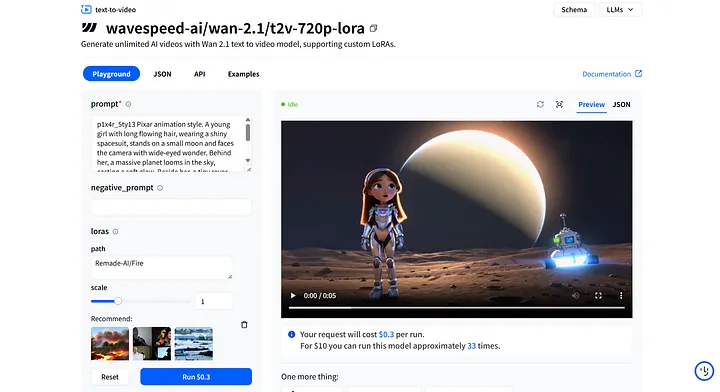 wavespeed-ai/wan-2.1/t2v-720p-lora页面
wavespeed-ai/wan-2.1/t2v-720p-lora页面
就像在Hugging Face平台上一样,你只需修改提示词并在Prompt 中添加LoRA触发词,然后在path 中包含用于调用LoRA模型的URL。
使用scale 来控制LoRA对基础模型的影响程度(默认值1 通常足够。如果感觉太弱或太强,做小的调整),最后使用seed 进行复现和比较。
有些模型有特定的参数,但在WaveSpeedAI上,我们已经为你设置了默认值。直接使用它们会给你很好的结果!
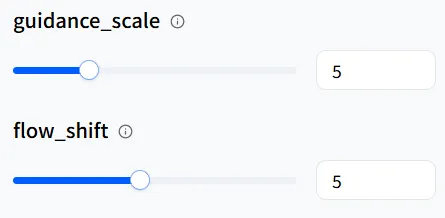
如果你想进一步完善细节,你可以尝试调整它们。但请注意,对于num_inference_steps 之类的参数,值越高,视频生成时间的增加就越明显。
在这里,你会找到LoRA模型的下载部分。确保为正确的功能选择SafeTensor 模型类型。
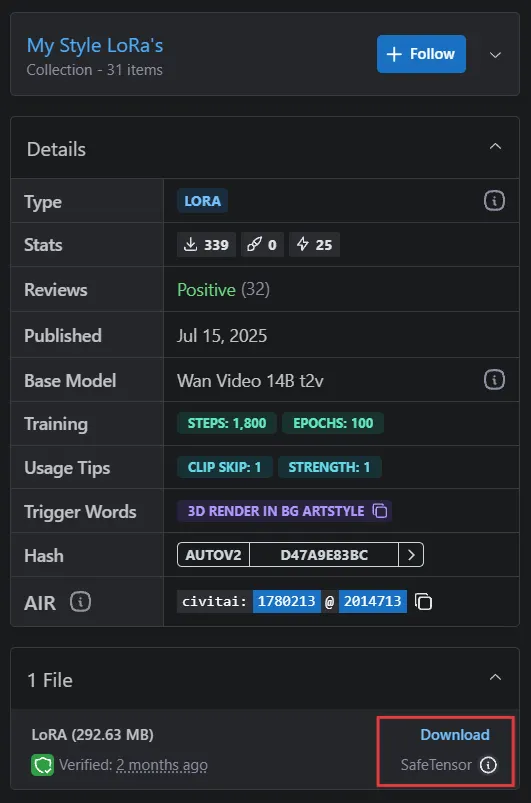 下载LoRA
下载LoRA
右键单击Download,然后复制链接地址——这是你将用来调用LoRA模型的URL。
同样,在wavespeed-ai/wan-2.1/t2v-720p-lora 的Playground中,找到loras 部分,点击**+ Add Item**,并将你刚复制的URL粘贴到path 中。
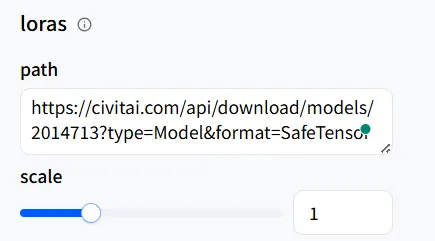 粘贴在路径中
粘贴在路径中
如果你不确定如何更有效地使用LoRA,你可以查看Civitai上的参考。模型作者通常提供你可以点击查看的示例。
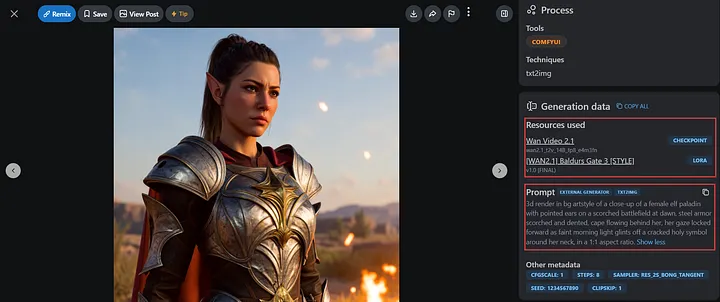 带有资源和提示词的示例页面
带有资源和提示词的示例页面
在这里,我们将复制作者示例中的提示词,以尝试创建我们自己的游戏角色。
我们创建的结果!
是不是很棒?生成的结果可能与作者的略有不同,但你可以根据你的目标调整提示词(澄清风格、材料、相机和情绪,添加或删除修饰符),逐步达到你想要的效果。
毕竟,最有意义的作品不是别人的复制品,而是那些始终展现你自己独特质感和风格的作品——这正是LoRA与你创作之间不言自明的理解所在。
结论
到此为止,你已经学会了如何在WaveSpeedAI上使用你喜欢的LoRA模型。但请记住,LoRA不会为你做美学选择。它只在你设定了方向后稳定细节。真正使作品独特的总是你的品味和想象力。
所以大胆一些——尝试、学习并不断改进。当你在Inspiration中分享你的第一批结果并与社区一起成长时,你会看到效率只是开始。让你的风格被认可是真正的目标。
祝你创意顺利,成功实现你的设想!





