Nano Banana Pro API 现已登陆WaveSpeed:如何调用 + 定价说明

你是否曾经盯着WaveSpeed上的Nano Banana Pro API文档,心想”我接下来到底应该怎么做?“你并不孤单。我是Dora,我亲自测试了数十个API,也经历过文档不完整的端点和意外的账单邮件。在本指南中,我将逐步引导你如何清晰地调用Nano Banana Pro API,并避免可能让你的项目预算措手不及的定价陷阱。
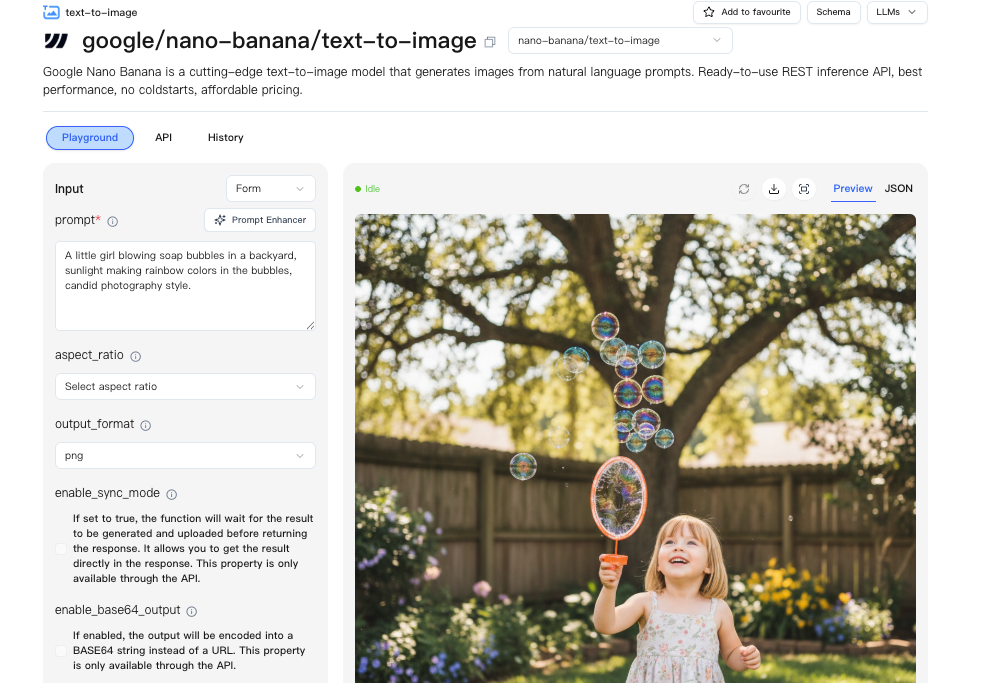
端点/流程
我没有切换整个技术栈。我在Nano Banana Pro后面包装了一个小的适配器服务,这样我可以在供应商之间切换而无需重写代码。WaveSpeed的仪表板让这比我预期的要容易得多。一个端点、一致的认证和一个简单的配额视图,让我不用费力寻找。
我的流程是这样的:
- 一个小的预处理器清理输入(转小写术语、删除多余空格、统一时区戳)。
- 我用稳定的系统指令和一个简短的示例集向Nano Banana Pro端点发送请求。
- 我缓存了稳定的提示和常见响应。没什么花哨的,只是一个本地TTL缓存和WaveSpeed自己对相同负载的响应缓存。
- 我存储了追踪数据:提示哈希、参数、延迟、令牌计数和错误代码。
最有帮助的是可预测性。该端点不会试图代表我进行聪明的路由。如果我要求Nano Banana Pro,我就能得到它。在我的运行过程中,中位延迟保持在一个稳定的范围内,方差在美国工作时间内的上升幅度不如我预期的那么大。不完美,但比我的基线平稳得多。
 如果你更关心稳定的路由和透明的使用情况,而不是追求最便宜的报价项,可以试试我们的Wavespeed。我们专注于可预测的端点、清晰的身份验证和不需要猜测的使用可见性。
如果你更关心稳定的路由和透明的使用情况,而不是追求最便宜的报价项,可以试试我们的Wavespeed。我们专注于可预测的端点、清晰的身份验证和不需要猜测的使用可见性。
有一个小问题:流式选项有效,但在我的使用中它没有充分减少感知延迟。对于短文本,流式传输感觉像是多余的步骤。对于较长的摘要,它很愉快但不必要。除了手动审查会话外,我对所有内容都关闭了它。
关键参数
我尽量不调整参数,除非有理由这样做。这里只有少数几个参数实际上很重要。
- 模型选择:Nano Banana Pro在我的测试期间保持一致(截至2026年1月)。没有意外的交换。这种稳定性是我继续使用的主要原因。
- 温度:对于标记和分类,我将其设置在接近零的地方。这减少了不一致性。对于具有一些综合的摘要,0.3-0.4给了我更流畅的措辞而不会偏离简介。
- 最大令牌数:我为短任务设置了紧密的上限以避免膨胀输出。对于长摘要,我给了慷慨的限制,并在事后依靠硬字符计数。
- 系统指令:简短清晰的指令比冗长的策略块更好。我用一句话来设置角色,加上一个小的规则”不要推断,不确定时显示证据”。我添加的内容越多,它就越谨慎。
- Top-p vs. 温度:我保持top-p固定在1.0,同时调整温度。同时混合两者使差异更难追踪。
让我吃惊的是这个模型对示例放置的敏感程度。在指令之后立即放置两个具体示例比在整个文本中混合五个效果更好。当我将示例移到最后时,边缘情况下的质量下降了。该API没有强制格式,但一致性是值得的:相同的字段名、相同的顺序、相同的标点。
质量调整
除了温度和令牌上限,几个举动改变了输出的感觉:
- 短入门比冗长政策更好。一行意图+两个示例产生的过度解释比一页指导要少。
- 证据提示有帮助。问”引用触发此标签的短语”大大减少了想象力标记。它也让质量保证更平稳,因为我可以快速发现幻觉。
- 软约束>硬约束。说”目标是3-5个要点”比”恰好4个要点”效果更好。模型尊重边界而不会变得不稳定。
- 确定性框架:我在最后添加了一点结构,“返回:标签、置信度(0-1)、证据(文本)“。它保持输出整洁而不会感到像模式监狱。
质量在两种情况下下降:杂乱的OCR输入和领域术语。修复不是更聪明的提示。它只是一个微小的前置步骤:修剪垃圾字符、统一连字符,并将未知术语列在顶部为”看到的术语”。一旦我这样做了,模型就停止猜测奇怪的标签。这在第一天没有为我节省时间,但到第四次运行时,我注意到我没有再重读。较少的心智努力计数。
定价考虑
 我没有追求最低的报价项。我想要可预测的支出来换取可预测的输出。
我没有追求最低的报价项。我想要可预测的支出来换取可预测的输出。
在我的测试中,Nano Banana Pro在WaveSpeed上每千个令牌的成本中等。真正的好处是更一致的令牌使用。因为模型在使用正确的提示形状时不会冗长,我看到的意外峰值更少。在添加软要点约束后,我的摘要平均输出长度稳定了。
两个小习惯在不伤害质量的情况下降低了成本:
- 对重复指令和示例进行提示缓存(WaveSpeed做了部分工作:我的适配器做了其余部分,因此相同的请求短路)。
- 无操作情况的早期退出。如果输入太短或显然不相关,跳过调用并返回默认值。这听起来很明显,但我倾向于忘记它,直到看到账单。
如果你处理流量不稳定的工作负载,按使用付费模式对我有意义。如果你的使用稳定且繁重,你可能会考虑承诺信用,但只有在一个月的真实数字之后。我不会基于直觉预先承诺。
批处理提示
我在试用期间进行了两个每周批处理。一些模式有帮助:
- 小的、稳定的批大小。我选定了50项的块。并发很温和(10-12)。吞吐量很好,错误处理保持理智。
- 带退避的重试预算。对于暂时性问题进行一次快速重试,然后进行较长的退避,然后停放项目。没有无限循环。
- 幂等性令牌。相同的输入、相同的哈希、相同的请求密钥。如果重试成功,我不会支付两倍或重复日志。
- 预验证。在向API发送任何内容之前,我拒绝了缺少必需字段的输入。很无聊,但节省了时间。
一个摩擦是速率限制透明度。WaveSpeed的仪表板清楚地显示了使用情况,但在高峰期间,每分钟的上限感觉有点不透明。我通过在我的适配器中添加移动平均防护并将429s视为信号而不是错误来解决这个问题。之后,这些批处理无戏剧性地进行。
错误处理
我保持错误处理简单和可观察,遵循REST API错误处理最佳实践。
- 超时:我设置了一个保守的客户端超时。如果请求运行时间过长,我将其标记为缓慢重试通道。长时间请求通常在重试时完成:关键是不要堵塞快速通道。
- 4xx vs 5xx:除了速率限制外,4xx被停放进行手动审查。5xx得到短重试突发。这避免了在不良输入上浪费周期。
- 输出中的护栏:我要求模型始终包含置信度分数。当分数低于0.6时,我将项目发送到人工审查队列。简单的分类,较少的遗憾。
- 日志:我仅对标记的情况记录原始提示和响应,而不是所有内容。隐私保持更清晰,我的日志更小。
确实有一些真正的模型失误,对讽刺的自信但错误的标签。我没有试图通过提示来解决这个问题。我添加了讽刺检查作为单独的轻量级传递,然后才应用主要标记器。两个步骤,较少的混乱。
示例负载逻辑(非代码解释)
这是我发送的内容的形状,用简单的语言。
- 系统角色:一句关于工作的话。例如,“你是一个仔细的分类器,用一小组标签标记营销文案,并指出驱动决策的单词。”
- 上下文:任何奇怪术语的小词汇表,加上两个清晰的示例,一个干净的,一个棘手的。
- 指令:要返回什么以及按什么顺序(标签、置信度、证据),以及语调约束(简洁、没有对冲语言)。
- 输入:原始文本,除了空格清理外保持不变。
- 限制:所需的证据最大长度和标签数量的上限。
在适配器一侧,我从系统角色+示例+指令生成了稳定的哈希。如果该哈希与具有相同输入的先前请求匹配,我检查了缓存。如果没有,我用WaveSpeed的Nano Banana Pro端点调用,设置温度和令牌上限用于工作负载。我按键解析输出,而不是按位置,所以小的措辞变化不会破坏任何内容。
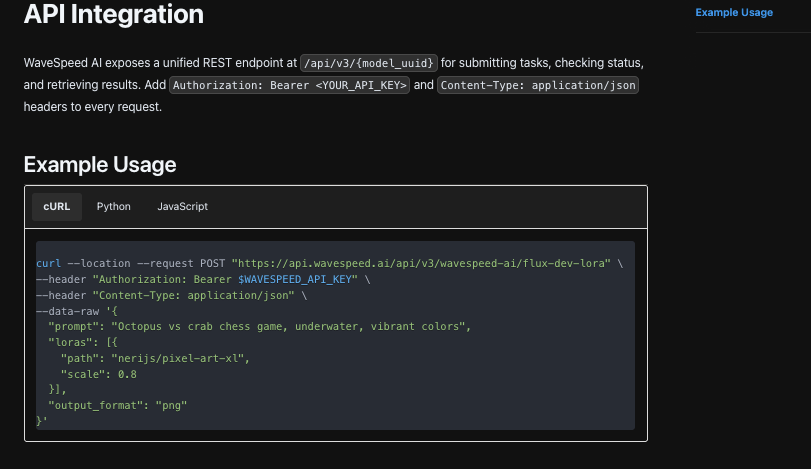 如果响应缺少任何必需的密钥,我不会要求模型就地修复自己。我用短提醒重新发出提示:“仅返回三个密钥。“最多一次重试。之后,它进入审查队列。这防止了系统将自己循环成无意义的内容。
如果响应缺少任何必需的密钥,我不会要求模型就地修复自己。我用短提醒重新发出提示:“仅返回三个密钥。“最多一次重试。之后,它进入审查队列。这防止了系统将自己循环成无意义的内容。





