Z-Image LoRA:它的含义以及何时需要它(初学者友好指南)

嗨,朋友们。我是多拉。上周我没有计划训练任何东西。我只是想要一个一致的小助手,一个可以坐在我截图角落里的插画角色。提示词不断让我接近,然后漂移。眉毛变了。颜色滑动了。在周二(2026 年 1 月 13 日)尝试了几次近乎成功的尝试后,我尝试了 Z-Image LoRA。我预期会陷入兔子洞。结果更像是一条短走廊。
这不是胜利圈。这不是即时的。但该设置消除了足够的摩擦,我不再考虑设置,而是开始思考我的图像。以下是什么有效、什么无效,以及何时你可能根本不需要 LoRA。
Z-Image LoRA 一分钟版本
LoRA(低秩自适应)是一个小附加程序,你可以在基础图像模型上训练,以将其推向特定的风格或主题,而无需重新训练整个模型。
 Z-Image LoRA(初学者友好)做得很好的地方:
Z-Image LoRA(初学者友好)做得很好的地方:
- 隐藏了吓人的旋钮。你仍然需要选择一些基础设置(图像、标题、目标),但默认值是明智的。
- 训练速度足以迭代。我的第一次尝试(10 张图像)在中等 GPU 上花了大约 12-18 分钟。
- 像图层一样加载。你在生成工具中切换它,像往常一样提示,加上可选的触发词。
你得到的是:一个小文件,在你需要一致性、徽标、角色、毛刷水彩外观时推动模型,而不会锁定你。如果你不打开它,基础模型的行为如常。
你不需要 LoRA 的情况
我带着爱说这一点:我们很多人反应太快就去训练了。我不费力的几种情况:
- 基础模型已经很接近了。如果带有参考图像的简短提示能给你 8/10 的可用结果,你就完成了。IP-Adapter 或图像提示可能就够了。
- 你需要变化,而不是一致性。如果每个输出都应该漂移,LoRA 可能会过度转向。
- 一次性视觉效果。对于单个横幅,我会花五分钟额外的提示,而不是设置训练。
- 约束存在于构图中,而不是身份中。ControlNet 或姿势引导等工具可以在不教模型新概念的情况下塑造布局。
我使用的快速测试:如果简单的种子扫描和 2-3 个提示调整无法在五张图像中保持我关心的元素(相同的角色、相同的徽标比例),那就是我考虑 LoRA 的时候。否则,我保持简单。
LoRA 何时有帮助
本周(2026 年 1 月)我在两种情况下感受到了最大的差异:
- 一个我想在文档中重复使用的小吉祥物。提示词不断摇晃眼睛和衣服颜色。经过短期 LoRA 后,这些稳定了下来,我可以专注于姿势和背景。
- 用于图表的柔软铅笔纹理。我可以提示”铅笔素描”,但阴影每次都会改变。一个 15 张图像的风格 LoRA 给了我稳定的线条质量,而不会固定内容。
LoRA 可能会有帮助的信号:
- 你需要同一主题跨越许多场景。
- 特定的艺术纹理很重要(交叉影线、油印点、厚重的蛋彩颜料边缘)并不断漂移。
- 你想减少提示词体操。训练后,我的提示词从 80-100 个令牌降至 30-40 个。心理努力比时间下降得更多。
让我惊讶的是影响感觉有多么平静。没有戏剧化的前后对比。只是更少的重试,更少的”几乎”。
数据要求
 我保持这个简单,效果比预期好。上周两次短期运行的一些注意事项:
我保持这个简单,效果比预期好。上周两次短期运行的一些注意事项:
数量
- 角色/主题: 8-20 张图像如果多样化(角度、照明、轻微的服装变化)可能就足够了。我用了 12 张。
- 风格/纹理: 10-30 张共享相同外观但内容不同的图像。我用了 15 张。
质量
- 分辨率: 提供与你的生成大小大致匹配的图像。如果你计划在 1024 生成,不要在微小的 256 裁剪上训练。
- 多样性胜过数量: 同一姿势的五个副本教会模型很少,并推动它向过度拟合。
- 干净背景有助于角色: 繁忙的场景会模糊信号。
标题
- 简短和字面意思:“一个蓝色的小吉祥物,圆眼睛,红色衬衫”、“铅笔素描、交叉影线、柔软阴影”。
- 命名要一致。如果你为角色发明唯一的名字(如”mori-kiko”),在每个标题中使用它,这样你以后可以触发它。
- 你可以从自动标题开始,然后轻轻清理它们。我削减了不反映核心想法的形容词。
我使用的过程
- 12 张主题照片(正面/四分之三侧/侧面),中性背景。
- 来自我自己的图表的 15 个风格帧,相同的纸张纹理。
- 一次通过,默认秩,轻正则化。训练时间:在租用的 A10G 上约 16 分钟。设置:约 10 分钟。第二次运行使用了 20% 更少的步骤并保持良好。
如果你只记得一件事:较少、更清晰的图像胜过大的、嘈杂的文件夹。
风格 vs 角色 LoRA
我以前把这些混在一起。它们的行为不同。
角色/主题 LoRA
- 目标: 教授特定的身份(一个人、吉祥物、产品)。
- 数据: 一致的主题,多样的背景:如果面部身份很重要,则近距离的脸部。
- 提示词: 保持触发名称加上简短描述。让 LoRA 处理身份:你引导姿势/场景。
- 风险: 过度拟合服装或背景。混合它们。
风格/纹理 LoRA
- 目标: 教授表面质量(线条工作、调色板、笔触、纹理)。
- 数据: 许多不同的主题,一种风格。
- 提示词: 不需要触发名称,但简单的标记有帮助(“sketchline style”)。
- 风险: 风格吞没内容。如果一切都变成同样的模糊绘画,请降低强度。
强度和混合
- 大多数工具都会公开 LoRA 权重。我很少超过 0.8 用于角色或 0.6 用于风格。小推动很重要。
- 你可以堆叠两个 LoRA(一个风格,一个角色)。当一个占主导地位而另一个保持在 0.4 以下时,我获得了最佳结果。
我学会了将角色 LoRA 视为”谁”,将风格 LoRA 视为”如何”。简单,但它让我不会责备错误的东西。
常见神话
我经常遇到的一些说法,以及我实际看到的:
- “你需要数百张图像。“我用 12 张训练了一个可用的角色。更多有帮助,但仅当它们多样化和干净时。
- “这需要数小时。“使用适度的 GPU 和初学者预设,我的运行时间不到 20 分钟。沉重的自定义配置可能需要更长时间。
- “LoRA 取代提示工程。“它减少了摆弄,但没有消除它。我仍然提示构图、照明和情绪。
- “一个 LoRA 适合所有模型。“不总是。在一个基础上训练的 LoRA 可以在兄弟模型上转移得还可以,但结果会改变。我把它们视为相关的,而不是可互换的。
- “更高的强度 = 更好。“超过一定点,图像会崩溃成相同。如果细节变糊,降低权重。
- “自动标题未编辑也可以。“它们是一个很好的开始。我仍然修剪了奇怪的形容词(“不祥的”、“电影化的”),这些不是概念的一部分。
这没有什么魔法。这是小的、可重复的调整,会以复合方式增加。
快速术语表
- LoRA: 一组紧凑的学习权重更新,将大模型适应到目标概念,而无需重新训练所有内容。根据 IBM 的 LoRA 文档,与完全微调相比,它可以将可训练参数减少高达 10,000 倍。
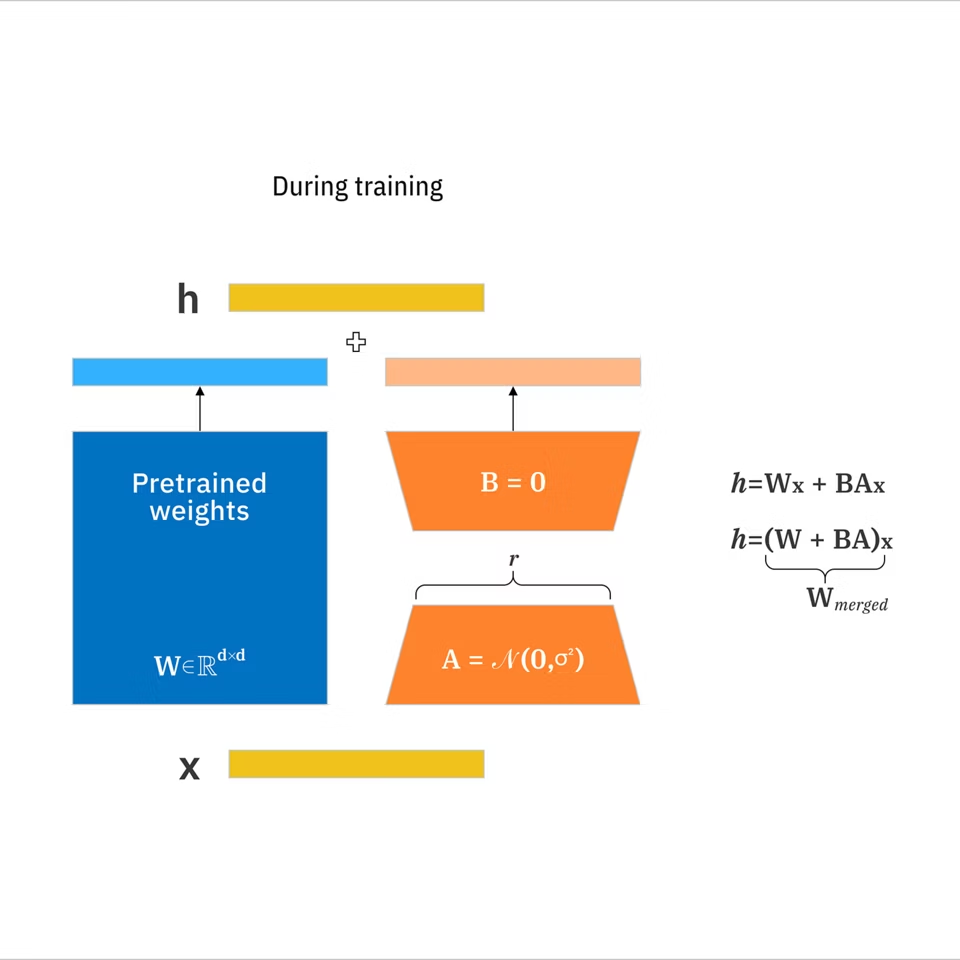
- 基础模型: 你生成的基础(在任何 LoRA 之前加载的内容)。
- 秩 (r): 控制 LoRA 表现力的设置。更高的秩可以捕捉更多细微差别,但可能过度拟合并使大小膨胀。
- 权重/强度: 在推理时 LoRA 影响生成的强度。
- 触发词: 一个唯一的令牌,你在提示中使用来调用主题 LoRA(例如,你在标题中使用的虚构名字)。
- 过度拟合: 当模型记住训练图像并停止泛化时。显示为近似副本。
- 正则化: 防止过度拟合的技术或额外数据。
- UNet/文本编码器: 处理图像和文本的模型部分。一些训练更新两者:初学者预设通常更多地触及图像端。
- 标题: 与每个训练图像配对的文本。
- 检查点: 模型或 LoRA 的保存状态。
如果其中任何一个感觉模糊,你仍然可以训练。初学者预设的设计目的是让你远离麻烦。
WaveSpeed 上的后续步骤
我在 WaveSpeed 上使用初学者友好的路径来运行 Z-Image LoRA,而不需要追逐设置。流程很平静:
- 选择一个基础模型。
- 拖放 8-20 张图像和简短标题。
- 选择”风格”或”角色”。
- 开始训练并泡茶。
- 为生成加载 LoRA 并尝试两个权重(0.4 和 0.8)来感受范围。
最有帮助的是将第一次运行视为草图。我寻找两件事:身份是否在五个提示中保持不变,以及风格是否保持其纹理而不吞没内容?如果一个失败了,我调整了数据集,而不仅仅是滑块。
如果你正在处理相同的约束,漂移的角色,漂移的纹理,这是值得看一看。这对我有效:你的里程数可能会有所不同。
这正是我们构建 WaveSpeed 的原因。当角色漂移、风格摇晃、提示变成体操时,我们想要一种更平静的方式来获得一致性,而无需过度设计。在 WaveSpeed 上,我们使用初学者友好的流程运行 Z-Image LoRA—清晰的默认值、快速迭代,以及足够的控制来保持身份和纹理稳定,因此你可以花更少的时间重试,花更多的时间实际制作图像。
→ 在 WaveSpeed 上训练简单的 LoRA
 我为自己保留的一个小笔记:我在提示中争斗的词越少,我对我面前的图像的关注就越多。那是我不想自动化的部分。
我为自己保留的一个小笔记:我在提示中争斗的词越少,我对我面前的图像的关注就越多。那是我不想自动化的部分。





