Inworld TTS 1.5 теперь доступен на WaveSpeedAI (Max + Mini)
WaveSpeedAI теперь поддерживает Inworld TTS 1.5 — готовый к производственному использованию движок синтеза речи в реальном времени, разработанный для низкой задержки, высокой выразительности и масштабируемости.
WaveSpeedAI теперь поддерживает Inworld TTS 1.5 — готовый к производственному использованию движок преобразования текста в речь в реальном времени, разработанный для минимальной задержки, высокой выразительности и масштабируемости.
Если вы создаёте голосовых агентов, ассистентов реального времени, диалоги для NPC в играх или любой интерактивный голосовой UX, где важна каждая миллисекунда, эта интеграция решает одну задачу: обеспечить отзывчивый и естественный голосовой опыт — не жертвуя надёжностью и стоимостью при масштабировании.
Совместный маркетинг: мы проводим совместную акцию с Inworld начиная со вторника, 10 февраля 2026 года (вторник, 2:00 AM) — так что если вы оцениваете голосовые решения реального времени для своего продукта, эта неделя — лучшее время, чтобы протестировать всё от начала до конца.

Почему это важно: качество на вершине рейтинга + задержка реального времени
Последняя линейка TTS от Inworld позиционируется на основе измеримых независимых бенчмарков — особенно производительности в публичных таблицах лидеров и отзывчивости в реальном времени.
- Сигнал #1 (качество): Inworld TTS занимает верхние позиции в сравнениях TTS от Artificial Analysis, которые отслеживают качество (ELO) наряду со скоростью и ценой.
- Потоковая передача в реальном времени: Inworld акцентирует потоковую передачу в реальном времени через WebSocket, с вариантами модели, ориентированными на разные компромиссы между задержкой и качеством.
Если коротко: разработчикам нужны не просто «хорошие голоса» — им нужны хорошие голоса, которые отвечают мгновенно и не деградируют под нагрузкой.
Max vs Mini: какую модель выбрать?
WaveSpeedAI предоставляет два варианта для продакшена:
TTS 1.5 Max (рекомендуется для большинства приложений)
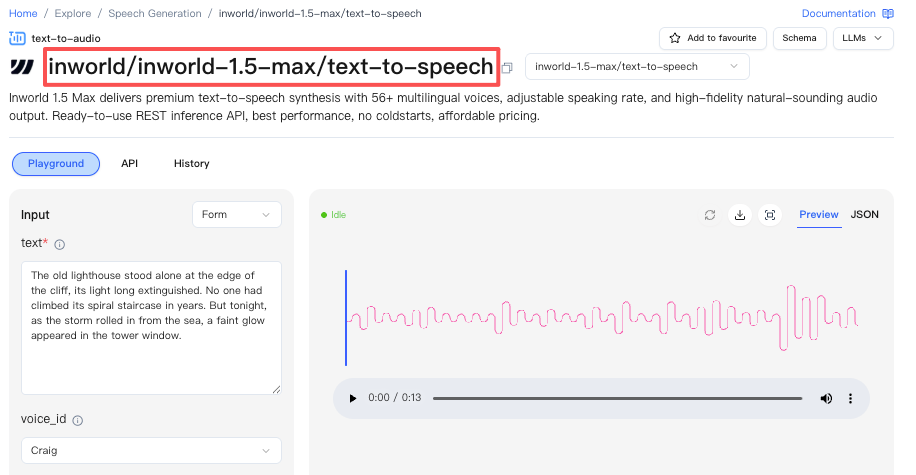
Выбирайте Max, если ваш приоритет — наилучшее общее качество голоса, стабильность и выразительность при сохранении задержки в диапазоне реального времени (Inworld описывает производительность класса ~200 мс для Max).
Типичное применение:
- Голосовые агенты, где важна естественность
- Клиентская поддержка / корпоративный UX
- Озвучивание контента, где выигрывает «человекоподобный» тон
Эндпоинт WaveSpeedAI: https://wavespeed.ai/models/inworld/inworld-1.5-max/text-to-speech
TTS 1.5 Mini (когда задержка — KPI №1)
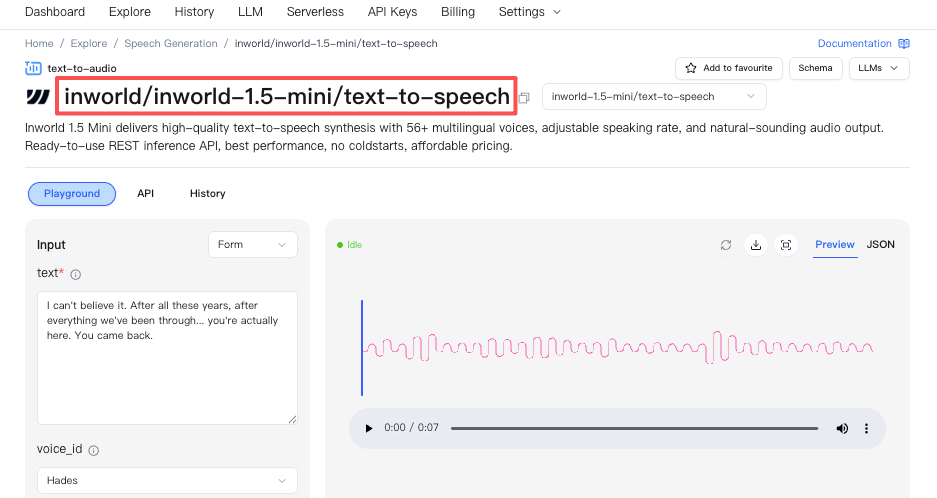
Выбирайте Mini, если ваш приоритет — сверхнизкая задержка для мгновенной смены реплик (Inworld описывает задержку P90 <120 мс для Mini).
Типичное применение:
- Диалоги NPC в играх реального времени
- Живые аватары / интерактивные стриминговые взаимодействия
- Любой продукт, где время отклика важнее точности воспроизведения
Эндпоинт WaveSpeedAI: https://wavespeed.ai/models/inworld/inworld-1.5-mini/text-to-speech
Что можно создать прямо сейчас (реальные сценарии использования)
Вот паттерны, которые команды внедряют быстрее всего:
Голосовые агенты реального времени (S2S / смена реплик) Синтез с низкой задержкой + потоковая передача — именно это делает разговор «живым», особенно когда вы связываете это с LLM и прерываемым аудиопайплайном.
Голосовые копайлоты для клиентской поддержки Когда нужны стабильный тон, высокая разборчивость и контроль затрат, «голосовой слой» не может быть узким местом. Inworld также предлагает опции клонирования голоса для брендированных или кастомизированных голосов.
Игры и интерактивные персонажи Короткие ответы, большая конкурентность и непредсказуемые пики нагрузки — здесь инфраструктура не менее важна, чем модель.
Быстрый старт: вызов Inworld TTS 1.5 на WaveSpeedAI
Используйте эндпоинты модели напрямую:
Советы по реализации (с прицелом на продакшен):
- Предпочитайте потоковую передачу через WebSocket, когда нужно воспроизведение в реальном времени и чёткая смена реплик.
- Если вы создаёте голосового агента, проектируйте с учётом прерываний (barge-in) и частичного воспроизведения аудио, а не ожидания полной звуковой волны.
- Если вам нужны функции выравнивания, такие как временные метки / разметка аудио, спланируйте клиентский слой воспроизведения для потребления этих сигналов (отлично подходит для подсветки в стиле karaoke, субтитров или синхронизации UI).
Частые вопросы
Поддерживается ли потоковая передача через WebSocket? Да — Inworld позиционирует TTS 1.5 для потоковой передачи в реальном времени через WebSocket, и это рекомендуемый путь для интерактивного голосового UX.
Сколько языков поддерживается? Inworld заявляет о многоязычной поддержке; WaveSpeedAI предоставляет доступ к моделям, чтобы вы могли строить многоязычный опыт с единой точки интеграции. (Конкретный набор поддерживаемых языков зависит от выбранной модели/версии.)
Доступно ли клонирование голоса? Inworld предоставляет возможности клонирования голоса (с разными уровнями и процессами в зависимости от типа клонирования).
