Z-Image LoRA: что это значит и когда это нужно (для начинающих)

Привет, друзья. Это Дора. На прошлой неделе я не планировала ничего тренировать. Я просто хотела получить небольшого помощника, иллюстрированного персонажа, который сидел бы в углу моих скриншотов. Промпты постоянно приближали меня к результату, а потом уходили в сторону. Брови менялись. Цвета смещались. Во вторник (13 января 2026 г.), после нескольких почти удачных попыток, я попробовала Z-Image LoRA. Я ожидала запутанного процесса. Это оказалось скорее коротким коридором.
Это не победный круг. Это не было мгновенным. Но настройка убрала достаточно препятствий, чтобы я перестала думать о параметрах и начала думать о своих изображениях. Вот что сработало, что не сработало и когда вам, вероятно, вообще не нужна LoRA.
Z-Image LoRA за одну минуту
LoRA (Low-Rank Adaptation) — это небольшое дополнение, которое вы обучаете поверх базовой модели изображений, чтобы подтолкнуть её к определённому стилю или объекту без переобучения всей модели.
 Что Z-Image LoRA (для начинающих) делает хорошо:
Что Z-Image LoRA (для начинающих) делает хорошо:
- Скрывает пугающие кнопки. Вы всё ещё выбираете несколько основных параметров (изображения, подписи, цель), но стандартные значения разумны.
- Тренируется достаточно быстро, чтобы итерировать. Мой первый проход (10 изображений) занял около 12–18 минут на GPU среднего уровня.
- Загружается как слой. Вы включаете его в своём инструменте генерации и промптируете как обычно, плюс опциональное слово-триггер.
Что вы получаете: крошечный файл, который подталкивает модель, когда вам нужна согласованность, логотипы, персонаж или размытый вид акварели, без блокировки. Если вы не включаете его, базовая модель ведёт себя как обычно.
Когда вам НЕ нужна LoRA
Говорю это с любовью: многие из нас обращаются к обучению слишком быстро. Несколько случаев, когда я не беспокоюсь:
- Базовая модель уже близка. Если короткий промпт с образцом изображения даёт вам результаты 8/10, которые можно использовать, вы готовы. IP-Adapter или промпт с изображением может быть достаточно.
- Вам нужна вариативность, а не согласованность. Если каждый выход должен блуждать, LoRA может переправить в неправильную сторону.
- Одноразовые визуальные элементы. Для одного баннера я потрачу пять дополнительных минут на промптирование, а не на настройку обучения.
- Ограничение находится в композиции, а не в идентичности. Инструменты типа ControlNet или направления позы формируют макет без обучения модели новой концепции.
Быстрый тест, который я использую: если простой перебор seed и 2–3 изменения промпта не могут удержать интересующий меня элемент (тот же персонаж, те же пропорции логотипа) на пяти изображениях, это когда я рассматриваю LoRA. В противном случае я остаюсь с простотой.
Когда LoRA помогает
Я почувствовала разницу больше всего в двух ситуациях на этой неделе (январь 2026):
- Маленький талисман, который я хотела переиспользовать в документах. Промпты постоянно смещали глаза и цвет рубашки. После короткой LoRA они стабилизировались, и я смогла сосредоточиться на позах и фонах.
- Мягкая карандашная текстура для диаграмм. Я могла промптировать “карандашный набросок”, но штриховка менялась каждый раз. 15-изображенческая стиль-LoRA дала мне стабильное качество линий без привязки контента.
Признаки того, что LoRA, вероятно, поможет:
- Вам нужен тот же объект в разных сценах.
- Определённая художественная текстура важна (перекрёстная штриховка, точки ризографа, толстые края гуаши) и постоянно смещается.
- Вы хотите сократить гимнастику с промптами. После обучения мои промпты упали с 80–100 токенов до 30–40. Умственное напряжение упало больше, чем время.
Что меня удивило, так это то, насколько тихим был результат. Никаких драматичных “до/после”. Просто меньше повторов, меньше “почти”.
Требования к данным
 Я держала это просто, и это сработало лучше, чем я ожидала. Несколько заметок из двух коротких запусков на прошлой неделе:
Я держала это просто, и это сработало лучше, чем я ожидала. Несколько заметок из двух коротких запусков на прошлой неделе:
Количество
- Персонаж/объект: 8–20 изображений могут быть достаточно, если они разнообразны (углы, освещение, лёгкие изменения одежды). Я использовала 12.
- Стиль/текстура: 10–30 изображений, которые имеют один стиль, но разный контент. Я использовала 15.
Качество
- Разрешение: предоставляйте изображения, которые примерно совпадают с размером вашей генерации. Если вы планируете генерировать в 1024, не тренируйте на крошечных обрезках 256.
- Вариативность перевешивает объём: пять копий одной позы мало учат модель и подталкивают её к переобучению.
- Чистые фоны помогают для персонажей: занятые сцены размывают сигнал.
Подписи
- Короткие и буквальные: “маленький синий талисман с круглыми глазами, красная рубашка”, “карандашный набросок, перекрёстная штриховка, мягкая тень”.
- Будьте последовательны с именованием. Если вы придумали уникальное имя для персонажа (например, “mori-kiko”), используйте его в каждой подписи, чтобы вы могли активировать его позже.
- Вы можете начать с автоподписей, затем слегка их очистить. Я убрала прилагательные, которые не отражали главную идею.
Процесс, который я использовала
- 12 снимков объекта (спереди/три-четверти/сбоку), нейтральные фоны.
- 15 кадров стиля из моих собственных диаграмм, одна текстура бумаги.
- Один проход, рейтинг по умолчанию, лёгкая регуляризация. Время обучения: ~16 минут на рентованном A10G. Настройка: ~10 минут. Второй запуск использовал на 20% меньше шагов и хорошо держался.
Если вы помните только одно: меньше, чётче изображения лучше, чем большие, шумные папки.
LoRA стиля и персонажа
Я привыкла смешивать их вместе. Они ведут себя по-разному.
LoRA персонажа/объекта
- Цель: научить определённую идентичность (человека, талисмана, продукт).
- Данные: последовательный объект, разные контексты: крупные планы лица, если идентичность лица имеет значение.
- Промпты: держите слово-триггер плюс краткое описание. Позвольте LoRA справиться с идентичностью: вы управляете позой/сценой.
- Риски: переобучение на одежду или фоны. Смешивайте их.
LoRA стиля/текстуры
- Цель: научить качество поверхности (линия, палитра, мазок кисти, зёрнистость).
- Данные: много разных объектов, один стиль.
- Промпты: слово-триггер не требуется, но простой маркер помогает (“стиль sketchline”).
- Риски: стиль поглощает контент. Если всё становится одной размытой картиной, снизьте интенсивность.
Интенсивность и смешивание
- Большинство инструментов имеют вес LoRA. Я редко иду выше 0.8 для персонажей или 0.6 для стилей. Маленькие толчки важны.
- Вы можете наложить две LoRA (одна стиль, одна персонаж). У меня были лучшие результаты, когда одна была доминирующей, а другая оставалась ниже 0.4.
Я научилась думать о персонаж-LoRA как о “кто” и о стиль-LoRA как о “как”. Просто, но это удерживает меня от обвинения неправильной вещи.
Распространённые мифы
Несколько утверждений, которые я часто слышу, и то, что я на самом деле видела:
- “Вам нужны сотни изображений.” Я обучила используемого персонажа с 12. Больше помогает, но только если они разнообразны и чисты.
- “Это занимает часы.” С модестным GPU и пресетом для начинающих мои запуски уложились менее чем в 20 минут. Тяжёлые, пользовательские конфигурации могут быть дольше.
- “LoRA заменяет инженерию промптов.” Это сокращает возню, но не устраняет её. Я всё ещё промптирую композицию, освещение и настроение.
- “Одна LoRA подходит для всех моделей.” Не всегда. LoRA, обученная на одной базе, может нормально передаться к родственной модели, но результаты смещаются. Я рассматриваю их как связанные, а не взаимозаменяемые.
- “Более высокая интенсивность = лучше.” После определённого момента изображения схлопываются в однообразие. Если детали размазываются, уменьшите вес.
- “Автоподписи в порядке без редактирования.” Они хорошее начало. Я всё ещё обрезала странные прилагательные (“зловещий”, “кинематографический”), которые не были частью концепции.
Ничего из этого не магическое. Это маленькие, повторяемые изменения, которые складываются.
Краткий словарь
- LoRA: Компактный набор выученных обновлений веса, который адаптирует большую модель к целевой концепции без переобучения всего. Согласно документации LoRA IBM, она может сократить обучаемые параметры до 10 000 раз по сравнению с полной тонкой настройкой.
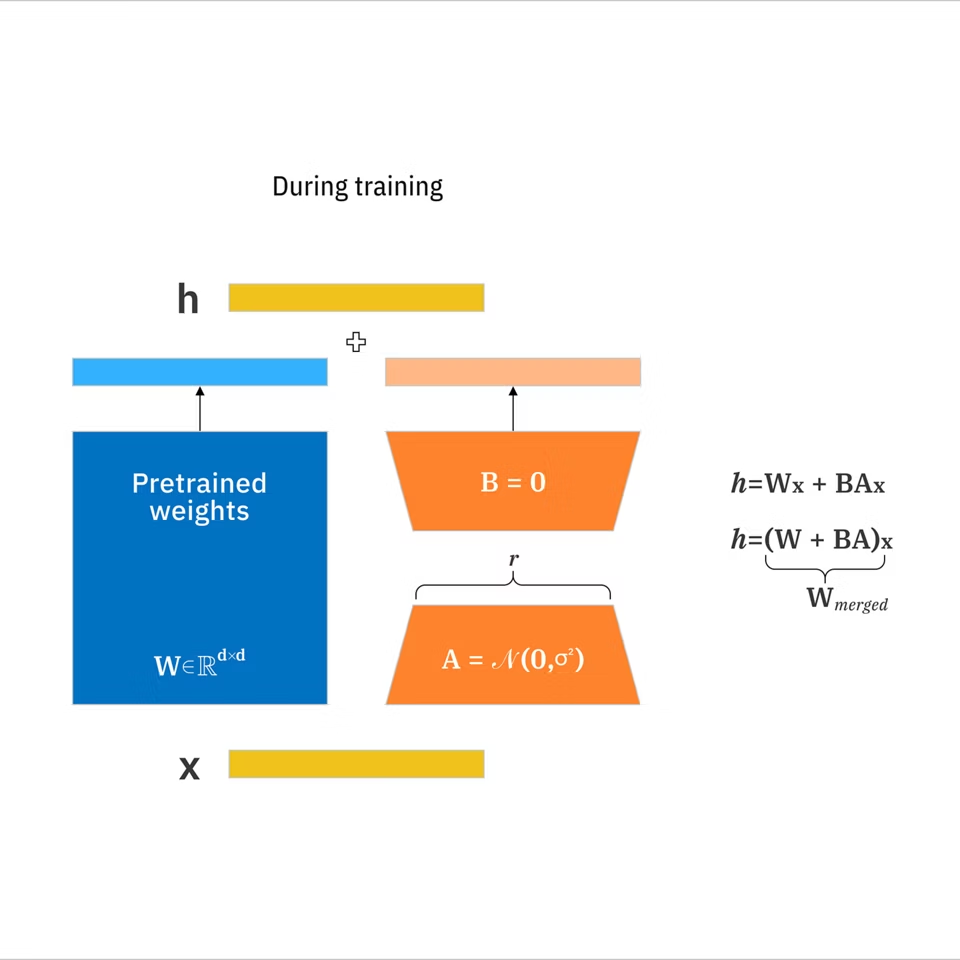
- Базовая модель: Основание, из которого вы генерируете (то, что вы загружаете перед любыми LoRA).
- Rank (r): параметр, который контролирует, насколько выразительна LoRA. Более высокий рейтинг может захватить больше нюансов, но может переобучиться и увеличить размер.
- Вес/Интенсивность: насколько сильно LoRA влияет на генерацию во время вывода.
- Слово-триггер: уникальный токен, который вы используете в промптах для вызова объекта LoRA (например, придуманное имя, которое вы использовали в подписях).
- Переобучение: когда модель запоминает тренировочные изображения и перестаёт обобщать. Проявляется как почти дубликаты.
- Регуляризация: методы или дополнительные данные для предотвращения переобучения.
- UNet/кодировщик текста: части модели, которые обрабатывают изображения и текст. Некоторые тренировки обновляют оба: пресеты для начинающих часто больше касаются стороны изображения.
- Подпись: текст, связанный с каждым тренировочным изображением.
- Контрольная точка: сохранённое состояние модели или LoRA.
Если что-либо из этого кажется нечётким, вы всё ещё можете тренировать. Пресет для начинающих разработан, чтобы держать вас в безопасности.
Следующие шаги на WaveSpeed
Я использовала дружественный путь для начинающих на WaveSpeed для запуска Z-Image LoRA без погони за параметрами. Процесс был спокойным:
- Выберите базовую модель.
- Перетащите 8–20 изображений и короткие подписи.
- Выберите “стиль” или “персонаж”.
- Начните обучение и заварите чай.
- Загрузите LoRA для генерации и попробуйте два веса (0.4 и 0.8), чтобы почувствовать диапазон.
Что помогло больше всего, так это рассмотрение первого запуска как наброска. Я искала две вещи: держалась ли идентичность на пяти промптах и сохранял ли стиль свою текстуру без поглощения контента? Если один не удался, я отрегулировала набор данных, а не только слайдеры.
Если вы имеете дело с одинаковыми ограничениями, дрейфующими персонажами, блуждающими текстурами, это стоит посмотреть. Это сработало для меня: ваши результаты могут отличаться.
Это именно то, почему мы построили WaveSpeed. Когда персонажи дрейфуют, стили шатаются и промпты превращаются в гимнастику, мы хотели более спокойный способ получить согласованность без переинженерии. На WaveSpeed мы запускаем Z-Image LoRA с дружественным потоком для начинающих — чёткие стандартные значения, быстрая итерация и достаточно контроля, чтобы держать идентичности и текстуры стабильными, чтобы вы могли потратить меньше времени на повторные попытки и больше времени на создание изображений.
→ Обучите простую LoRA на WaveSpeed
 Маленькую заметку я оставляю себе: чем меньше слов я борюсь в промпте, тем больше внимания я уделяю изображению перед собой. Это часть, которую я не хочу автоматизировать.
Маленькую заметку я оставляю себе: чем меньше слов я борюсь в промпте, тем больше внимания я уделяю изображению перед собой. Это часть, которую я не хочу автоматизировать.
Похожие статьи

Seedance 2.0 Полное руководство: Создание видео с несколькими модальностями

Seedance 2.0 уже скоро: видеомодель нового поколения от ByteDance с встроенным аудио

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: Полное сравнение генерации видео

Seedream 5.0-Preview Полное руководство: Интеллектуальная генерация изображений

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Полное сравнение
