DeepSeek V4 vs Claude Opus 4.5 для кодирования: Сравнение бенчмарков

Привет, ребята! Я Дора. В прошлое воскресенье утром я прыгал между редактором и окном чата, чтобы исправить нестабильный тест, и модель постоянно изобретала импорты, которых не существовали. Ничего страшного, просто одна из тех мелких проблем, которые замедляют работу. Я хотел посмотреть, поможет ли переключение моделей облегчить нагрузку, и не только на реальное время, но и на умственные усилия, необходимые, чтобы доверять тому, что попадает в мой репозиторий.
Поэтому я потратил последнюю неделю (27 января – 1 февраля 2026 г.) на простой, повторяемый цикл: те же задачи, те же снимки репозитория, чередуя DeepSeek V4 и Claude Opus 4.5. Это не лабораторное исследование. Это то, что я бы проверил перед подключением модели в CI. Если вы также взвешиваете DeepSeek V4 vs Claude Opus 4.5 для кодирования, это именно те заметки, которые я бы хотел прочитать перед переходом.

Лидеры текущего бенчмарка
Рейтинги SWE-bench Verified
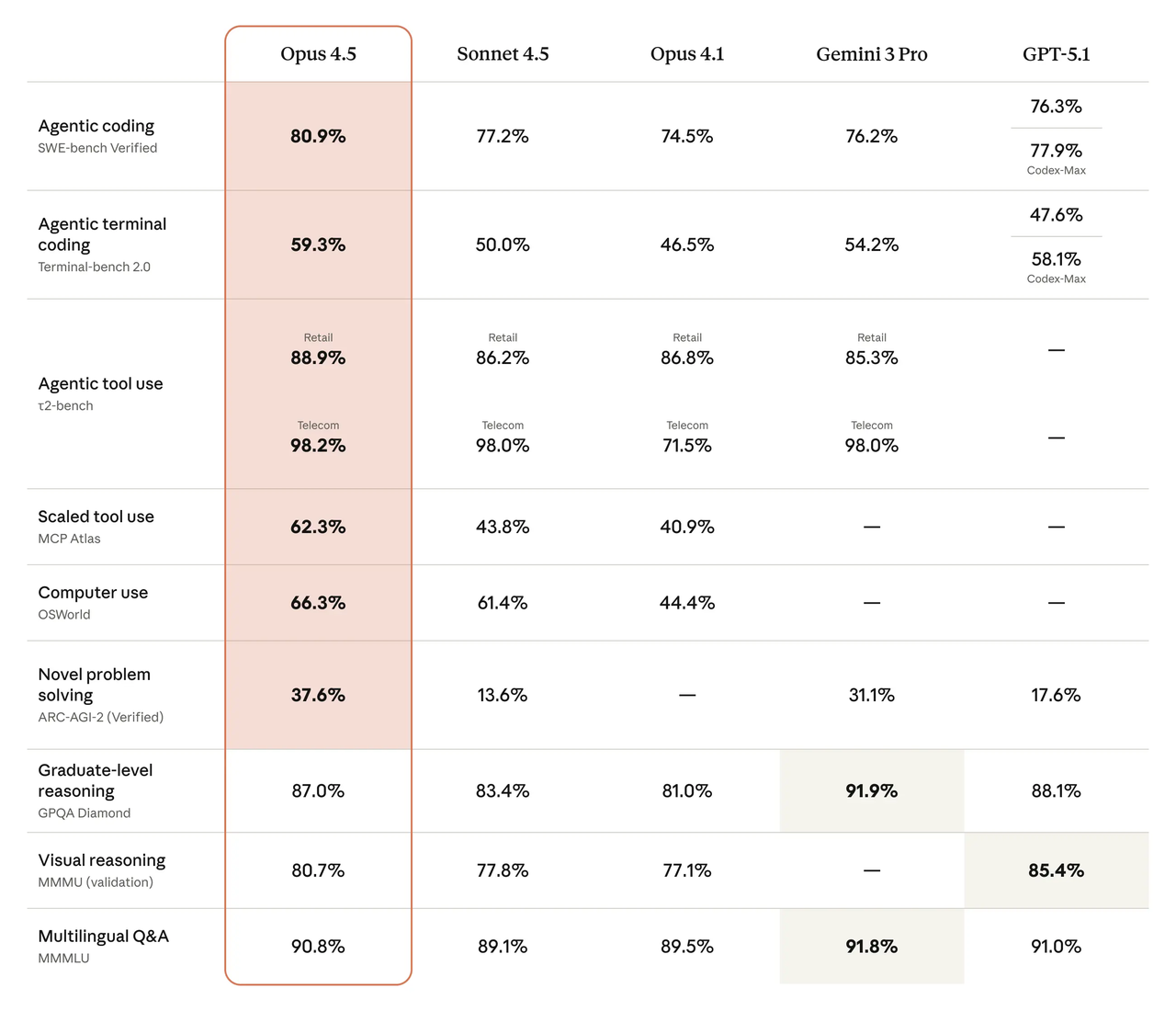
Когда мне нужно быстро понять, куда дует ветер, я начинаю с открытых лидербордов. В лидерборде SWE-bench Verified недавние модели DeepSeek и новое семейство Claude от Anthropic находятся рядом с вершиной, с небольшими разрывами, которые меняются неделя за неделей по мере изменения подсказок, инструментов и оценочных наборов. Для меня важно не одно число, а закономерность: какие модели последовательно решают сквозные проблемы без помощи инструментов и насколько они чувствительны к изменениям подсказок.
Мое быстрое прочтение, на начало февраля 2026 г.:
- DeepSeek V4 показывает сильное движение на многофайловых, задачах масштаба репозитория, когда вы даете ему весь контекст, который он просит. Это выигрывает от длинных подсказок и явных карт файлов.
- Claude Opus 4.5 выдает стабильные результаты и имеет тенденцию регрессировать меньше, когда я сокращаю контекст или удаляю системные сообщения. Это не впечатляющее, но нижний уровень кажется высоким.
Оценки HumanEval
HumanEval более узок, это короткие задачи кодирования с модульными тестами, но это полезная проверка здоровья для встроенной генерации кода. Текущие сводки на репозитории OpenAI HumanEval и трекерах сообщества, таких как лидерборд EvalPlus, помещают обе модели в верхний уровень. Я не привязываюсь к точным оценкам pass@1 здесь: я смотрю на стабильность между семенами и то, как часто модель полагается на языковые трюки вместо написания прямого, идиоматического кода.
 В моих запусках DeepSeek V4 иногда выдавал более длинные, более “объяснительные” решения, хорошо, но не всегда то, что я хочу в плотном диффе. Claude Opus 4.5 чаще возвращал компактные функции, которые без усилий проходили тесты без дополнительных комментариев. Бенчмарки намекают на эту разницу: практическая работа сделала это очевидным.
В моих запусках DeepSeek V4 иногда выдавал более длинные, более “объяснительные” решения, хорошо, но не всегда то, что я хочу в плотном диффе. Claude Opus 4.5 чаще возвращал компактные функции, которые без усилий проходили тесты без дополнительных комментариев. Бенчмарки намекают на эту разницу: практическая работа сделала это очевидным.
Где каждая модель превосходит
Долгий контекст (DeepSeek)
Если вы хотите воспроизвести эту настройку от начала до конца, я составил краткое руководство быстрого старта DeepSeek V4, которое рассказывает о основах чата и API, на которые я здесь полагаюсь.
Я дал обеим моделям реальную задачу: рефакторить небольшой сервис FastAPI, который тихо превратился в беспорядок. Мало файлов имело значение, плюс README, который был… оптимистичен. Я запаковал снимок репозитория и передал резюме файлов вместе с графиком вызовов, который я создал с помощью простого скрипта. DeepSeek V4 был спокоен с беспорядком. Он отслеживал кросс-файловые эффекты и не паниковал, когда я попросил поэтапный план: сначала интерфейсы, затем тесты, в последнюю очередь обработчики. Удивительной частью была то, как хорошо он использовал структурные подсказки, когда я дал ему простую “карту” имен файлов и ответственности, он перестал предлагать изменения файлам, которые не существовали.
Два практических замечания:
- Ему нужно было место для дыхания. Когда я слишком агрессивно обрезал контекст, он становился осторожным и начинал просить увидеть файлы, которые я уже предоставил. Когда я дал ему полную картину, он движется чисто.
- Он хорошо справлялся с подсказками “Что я упускаю?”. Я просил граничные случаи на основе набора тестов, и он выявил три, которые я забыл: пустые заголовки аутентификации, неправильный параметр пагинации и медленный путь в логировании ошибок.
Это не сэкономило время сначала. Первоначальная настройка, упаковка контекста, написание короткой карты файлов заняло около 20 минут. Но после нескольких запусков умственная нагрузка упала. Я не жонглировал столькими “а я ему это рассказал?” беспокойствами. Если ваш день кодирования выглядит как большие диффы, распределенные по нескольким модулям, DeepSeek V4 имеет твердую руку, когда контекст становится широким.
Надежность кода (Claude)
 Claude Opus 4.5 завоевал меня по-другому: меньше острых углов. Когда я просил минимальный патч, он дал мне его. Когда я просил трехступенчатый план с пробным запуском, он не галлюцинировал команды. И он сопротивлялся искушению “улучшить” вещи, которые я не просил.
Claude Opus 4.5 завоевал меня по-другому: меньше острых углов. Когда я просил минимальный патч, он дал мне его. Когда я просил трехступенчатый план с пробным запуском, он не галлюцинировал команды. И он сопротивлялся искушению “улучшить” вещи, которые я не просил.
Небольшой пример: у меня был нестабильный тест по математике часовых поясов. Моя подсказка была резкой: “Исправь тест без изменения рабочего кода и объясни основную причину в одном предложении.” Claude предложил параметризировать фиксатор tz и отрегулировать одно утверждение, чтобы использовать осведомленный datetime. Это прошло с первой попытки. DeepSeek также исправил это, но он попытался рефакторить помощника в той же дыхании. Не неправильно, просто тяжелее, чем мне хотелось.
На пяти задачах диффы Claude были неизменно меньше. Меньше импортов появлялось из ниоткуда. И когда он угадывал, он оставлял аккуратную записку: “Предполагается, что pytz доступен: если нет, замените на zoneinfo.” Этот вид защищенного предложения легко проверить.
Два ограничения проявились:
- Claude был осторожен по поводу производительности. В одном случае он выбрал ясность вместо простого улучшения O(n), которое DeepSeek указал немедленно. Мне пришлось его подтолкнуть: “Оптимизируй при тех же ограничениях.” Он сделал, но не совершил прыжок первым.
- С очень длинными подсказками я быстрее достиг потолка. Резюме помогли, но DeepSeek казался менее тесным, когда я хотел, чтобы модель “держала всё приложение в голове”.
Если ваш день - это в основном хирургические патчи, ремонт тестов и код-клей вокруг API, Claude Opus 4.5 держит изменения стройными и предсказуемыми. Это, на практике, надежность, которую я могу почувствовать.
Как провести собственное сравнение
 Если вы на заборе относительно DeepSeek V4 vs Claude Opus 4.5 для кодирования, короткий, скучный эксперимент рассказывает вам больше, чем любой лидерборд. Вот цикл, который я использовал, свободно делайте изменения.
Если вы на заборе относительно DeepSeek V4 vs Claude Opus 4.5 для кодирования, короткий, скучный эксперимент рассказывает вам больше, чем любой лидерборд. Вот цикл, который я использовал, свободно делайте изменения.
1. Выберите задачи, которые отражают вашу неделю
- Одна работа репозитория (рефакторинг или извлечение модуля)
- Один нестабильный тест
- Одно изменение интеграции API
- Одна небольшая настройка алгоритма
Держите каждое под 45 минут. Ограничьте взаимодействие по времени, не только генерацию модели.
2. Зафиксируйте входные данные
- Закрепите определенный коммит. Не перемещайте цель во время тестирования.
- Решите, что может видеть модель: полные файлы или отрывки. Напишите короткую карту файлов, если вы передаете отрывки.
- Используйте один и тот же стиль системной подсказки для обеих моделей. Я держу это просто: “Вы полезный помощник по кодированию. Предпочитайте минимальные диффы и исполняемый код.”
3. Напишите подсказки, которые вы можете повторно использовать
- Задача: “Вот цель, ограничения и тесты.”
- Контекст: список файлов или резюме, плюс известные подводные камни.
- Формат вывода: “Предложи план (пули), затем диф, затем одно предложение с примечанием о риске.”
4. Захватите одинаковые сигналы для обеих
- Попытки пройти тесты (1–N)
- Строк изменено в диффе (приблизительно хорошо)
- Заметки, которые вы пришлось написать для модели (“Остановись редактировать X”, “Используй существующий помощник Y”)
- Время до первого зеленого теста
5. Защищайте от утечки
- Отключите инструменты, если только вы не планируете сравнивать использование инструментов. Если одна модель вызывает оболочку и другая не вызывает, вы не тестируете одно и то же.
- Если вы разрешаете поиск, указывайте обе на один и тот же снимок документов.
6. Проверьте здравомыслием с бенчмарками, не поклоняйтесь им
- Взгляните на SWE-bench Verified, чтобы увидеть, если ваши результаты выглядят дико неправильно. Если так, проверьте ваши подсказки, прежде чем обвинять модель.
- Для небольших проблем, просмотрите примеры HumanEval на официальном репозитории или запустите несколько локально. Согласованность на горстке семян более показательна, чем один запуск.
7. Опционально: добавьте крошечную рубрику
Оценка 1–5 по:
- Минимализм диффа (он коснулся только того, что требовалось?)
- Дисциплина фиксатуры (тесты, окружение, зависимости)
- Поведение восстановления (он самостоятельно исправляется, когда вы указываете на промах?)
- Качество объяснений (одно или два четких предложения, не в блоге)
На что я обращаю внимание на практике
- Соблюдает ли модель ограничения с первого раза?
- Когда она неправильна, неправильна ли она таким образом, который легко обнаружить?
- Я чувствую себя в безопасности, позволяя ей предложить патч, пока я переключаю контекст?
Это сработало для меня, ваш километраж может отличаться. Суть не в том, чтобы объявить победителя: это чтобы увидеть, какой из них снижает вашу когнитивную нагрузку с вашим кодом, по вашему расписанию.
Похожие статьи

Seedance 2.0 уже скоро: видеомодель нового поколения от ByteDance с встроенным аудио

Seedance 2.0 Полное руководство: Создание видео с несколькими модальностями

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: Полное сравнение генерации видео

Seedream 5.0-Preview Полное руководство: Интеллектуальная генерация изображений

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Полное сравнение
