Nano Banana Pro API no WaveSpeed: Como Chamar + Notas de Preços

Você já ficou olhando para a documentação da Nano Banana Pro API no WaveSpeed e pensou “O que exatamente devo fazer agora?” Você não está sozinho. Eu sou Dora, testei pessoalmente dezenas de APIs, e tive minha boa dose de endpoints não documentados e surpresas desagradáveis nas faturas. Neste guia, vou orientá-lo passo a passo sobre como chamar a Nano Banana Pro API de forma limpa e evitar armadilhas de preços que podem prejudicar seu orçamento de projeto.
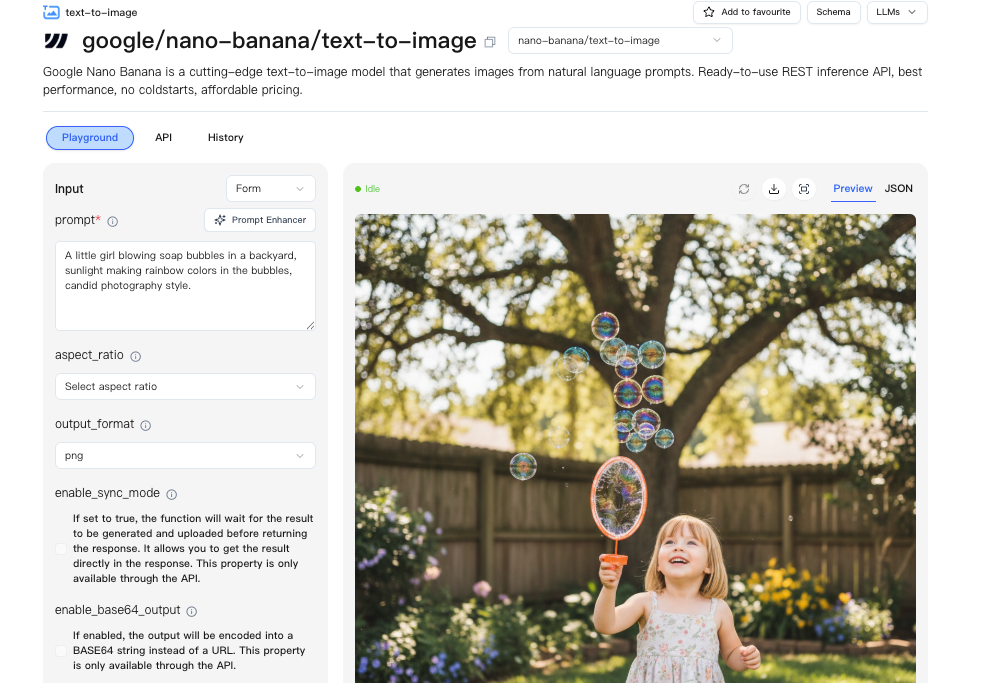
Endpoint / fluxo
Não mudei minha pilha inteira. Coloquei a Nano Banana Pro atrás de um pequeno serviço adaptador, para que pudesse alternar entre provedores sem remover código. O painel do WaveSpeed tornou isso mais fácil do que esperava. Um endpoint, autenticação consistente e uma visualização de cota simples que não me obrigava a procurar.
Meu fluxo foi assim:
- Um pequeno pré-processador limpava as entradas (convertendo jargão em minúsculas, removendo espaços em branco extras, unificando carimbos de hora).
- Eu enviava solicitações para o endpoint da Nano Banana Pro com uma instrução de sistema estável e um pequeno conjunto de exemplos.
- Eu armazenava em cache prompts estáveis e respostas comuns. Nada elaborado, apenas um cache TTL local e o próprio cache de resposta do WaveSpeed para payloads idênticos.
- Eu armazenava rastreamentos: hash de prompt, parâmetros, latência, contagem de tokens e códigos de erro quando apareciam.
O que mais ajudou foi a previsibilidade. O endpoint não tentava fazer roteamento inteligente em meu nome. Se eu pedisse Nano Banana Pro, era isso que recebia. Durante minhas execuções, a latência mediana pairava em torno de um intervalo estável, e a variância não disparava durante o horário comercial dos EUA tanto quanto esperava. Não perfeito, mas mais calmo que meu cenário base.
 Se você se importa mais com roteamento estável e uso transparente do que perseguir a linha de item mais barata, experimente nosso Wavespeed. Focamos em endpoints previsíveis, autenticação limpa e visibilidade de uso que não requer adivinhação.
Se você se importa mais com roteamento estável e uso transparente do que perseguir a linha de item mais barata, experimente nosso Wavespeed. Focamos em endpoints previsíveis, autenticação limpa e visibilidade de uso que não requer adivinhação.
Uma pequena complicação: a opção de streaming funcionou, mas em meu uso não reduziu a latência percebida o suficiente para importar. Para textos curtos, o streaming parecia cerimônia extra. Para resumos mais longos, foi agradável mas não necessário. Deixei desativado para tudo exceto sessões de revisão manual.
Parâmetros-chave
Tento não mexer em controles a menos que haja uma razão. Alguns realmente importaram aqui.
- Seleção de modelo: Nano Banana Pro permaneceu consistente durante meu período de teste (a partir de janeiro de 2026). Sem trocas surpresa. Esta estabilidade é a razão principal pela qual continuei.
- Temperatura: Para marcação e classificação, coloquei-a perto de zero. Isso reduziu inconsistência. Para resumir com um pouco de síntese, 0,3–0,4 me deu redação mais suave sem desviar da breve.
- Tokens máximos: Defini limites fechados para tarefas curtas para evitar saídas inchadas. Para resumos longos, dei limites generosos e confiei em uma contagem de caracteres rígida no pós-processamento.
- Instrução de sistema: Uma instrução curta e simples superou blocos de política longos. Usei uma frase para definir a função, mais uma pequena rubrica para “não inferir, mostrar evidência quando incerto.” Quanto mais adicionava, mais havia.
- Top-p vs. temperatura: Mantive top-p fixo em 1,0 enquanto ajustava temperatura. Misturar ambos tornava as diferenças mais difíceis de rastrear.
O que me surpreendeu foi o quão sensível o modelo era ao posicionamento de exemplos. Dois exemplos concretos logo após a instrução funcionaram melhor que cinco espalhados. Quando movi exemplos para o final, a qualidade caiu nos casos extremos. A API não impôs formato, mas consistência compensou: mesmos nomes de campos, mesma ordem, mesma pontuação.
Controles de qualidade
Além de temperatura e limites de tokens, alguns ajustes mudaram a sensação das saídas:
- Primers curtos superam políticas longas. Intenção em uma linha + dois exemplos produziram menos sobre-explicações que uma página de orientação.
- Prompts de evidência ajudaram. Pedir “cite a frase que acionou esta marcação” reduziu significativamente a marcação imaginativa. Também tornou a QA mais calma porque conseguia identificar alucinações rapidamente.
- Restrições suaves > restrições rígidas. Dizer “procure por 3–5 bullets” funcionou melhor que “exatamente 4 bullets.” O modelo respeitava limites sem ficar nervoso.
- Enquadramento determinístico: Adicionei um pouco de estrutura no final, “Retornar: rótulo, confiança (0–1), evidência (texto).” Mantinha as saídas arrumadas sem parecer uma prisão de esquema.
A qualidade caiu em dois casos: entradas OCR confusas e jargão de domínio. A solução não era mais prompting inteligente. Era apenas um pequeno pré-passo: remover caracteres inúteis, unificar hífens e listar termos desconhecidos no topo como “termos vistos.” Uma vez que fiz isso, o modelo parou de adivinhar rótulos estranhos. Isso não me economizou tempo no primeiro dia, mas na quarta execução notei que não estava relendo tanto. Menos esforço mental conta.
Considerações de preços
 Não persegui a linha de item mais barata. Queria gastos previsíveis para saída previsível.
Não persegui a linha de item mais barata. Queria gastos previsíveis para saída previsível.
Em meus testes, Nano Banana Pro ficou na faixa média de custo por mil tokens no WaveSpeed. O benefício silencioso era uso de token mais consistente. Porque o modelo não divagava com a forma de prompt correta, vi menos picos surpresa. Meu comprimento de saída médio para resumos se estabilizou depois que adicionei a restrição de bullet suave.
Dois pequenos hábitos reduziram custos sem prejudicar a qualidade:
- Cache de prompt para instruções e exemplos recorrentes (WaveSpeed fez parte disso: meu adaptador fez o resto para que solicitações idênticas fossem interrompidas).
- Saídas antecipadas para casos sem operação. Se a entrada é muito curta ou obviamente irrelevante, pule a chamada e retorne um padrão. Isso soa óbvio, mas eu tendo a esquecer até ver a fatura.
Se você está lidando com cargas de trabalho irregulares, o modelo de pagamento conforme o uso fazia sentido para mim. Se seu uso é estável e pesado, você pode considerar créditos comprometidos, mas apenas após um mês de números reais. Não me comprometeria antes com base em um palpite.
Dicas de lote
Executei dois lotes semanais durante o teste. Alguns padrões ajudaram:
- Tamanho de lote pequeno e estável. Estabeleci chunks de 50 itens. Concorrência era modesta (10–12). Throughput foi bom e o tratamento de erros permaneceu sano.
- Orçamento de retry com backoff. Uma retry rápida para problemas transitórios, depois um backoff mais longo, depois estacione o item. Sem loops infinitos.
- Tokens de idempotência. Mesma entrada, mesmo hash, mesma chave de solicitação. Se uma retry chegasse, eu não pagava duas vezes ou registrava duas vezes.
- Pré-validação. Rejeitei entradas sem campos obrigatórios antes de enviar qualquer coisa para a API. Chato, mas economizou tempo.
O atrito foi transparência de limite de taxa. O painel do WaveSpeed mostrava uso claramente, mas limites por minuto pareciam um pouco opacos durante pico. Resolvi isso adicionando um protetor de média móvel no meu adaptador e tratando 429s como sinais, não erros. Depois disso, os lotes rodaram sem drama.
Tratamento de erros
Mantive o tratamento de erros simples e observável, seguindo as melhores práticas de tratamento de erros da API REST.
- Timeouts: Defini um timeout conservador do cliente. Se uma solicitação durasse muito, marcava-a para uma pista de retry mais lenta. Solicitações longas frequentemente se completavam em retry: a chave era não entupir a pista rápida.
- 4xx vs 5xx: 4xx foi estacionado para revisão manual a menos que fosse um limite de taxa. 5xx recebeu uma breve rajada de retry. Isso evitava desperdiçar ciclos em entradas ruins.
- Guardrails em saídas: Pedi ao modelo para sempre incluir uma pontuação de confiança. Quando a pontuação caía abaixo de 0,6, enviava o item para uma fila de revisão humana. Triagem simples, menos arrependimentos.
- Logging: Registrei o prompt bruto e a resposta apenas para casos sinalizados, não tudo. Privacidade permanecia mais limpa e meus registros eram menores.
Houve alguns erros genuínos do modelo, rótulos confiantes mas errados em sarcasmo. Não tentei contornar isso com prompt. Adicionei uma verificação de sarcasmo como um passe separado leve e apenas então apliquei o tagger principal. Dois passos, menos confusão.
Lógica de payload de exemplo (explicação sem código)
Aqui está a forma do que enviei, em linguagem simples.
- Função de sistema: uma frase sobre o trabalho. Por exemplo, “Você é um classificador cuidadoso que marca cópia de marketing com um pequeno conjunto de rótulos e aponta as palavras que impulsionaram a decisão.”
- Contexto: um pequeno glossário para termos estranhos, mais dois exemplos claros, um limpo, um complicado.
- Instrução: o que retornar e em que ordem (rótulo, confiança, evidência), e a restrição de tom (breve, sem linguagem hesitante).
- Entrada: o texto bruto, intocado exceto por limpeza de espaço em branco.
- Limites: um comprimento máximo solicitado para a evidência e um limite no número de rótulos.
No lado do adaptador, gerei um hash estável a partir do papel de sistema + exemplos + instrução. Se aquele hash correspondesse a uma solicitação anterior com a mesma entrada, verificava o cache. Se não, chamava o endpoint Nano Banana Pro do WaveSpeed com temperatura e limites de token definidos para a carga de trabalho. Analisava a saída por chaves, não por posição, então pequenas mudanças de frase não quebram nada.
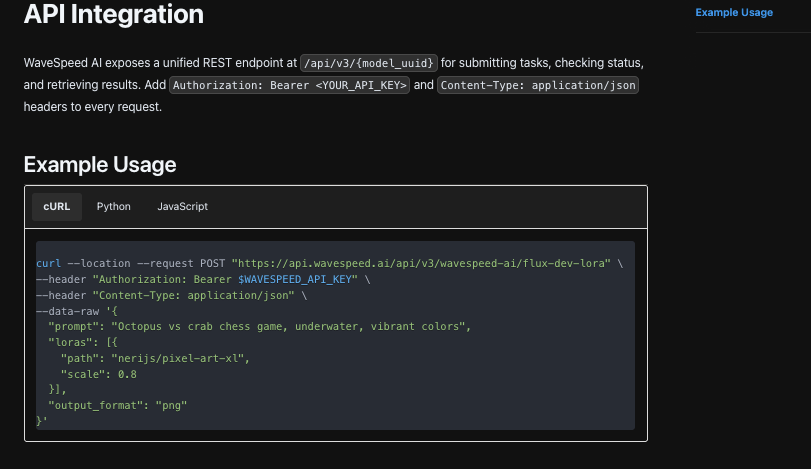 Se a resposta carecia de qualquer chave obrigatória, eu não pedia ao modelo para corrigir a si mesmo no lugar. Reemitia o prompt com um lembrete breve: “Retornar apenas as três chaves.” No máximo uma retry. Depois disso, ia para a fila de revisão. Isso mantinha o sistema de se enterrar em absurdos.
Se a resposta carecia de qualquer chave obrigatória, eu não pedia ao modelo para corrigir a si mesmo no lugar. Reemitia o prompt com um lembrete breve: “Retornar apenas as três chaves.” No máximo uma retry. Depois disso, ia para a fila de revisão. Isso mantinha o sistema de se enterrar em absurdos.
Artigos relacionados

Seedance 2.0 em Breve: Modelo de Vídeo de Próxima Geração do ByteDance com Áudio Nativo

Guia Completo do Seedance 2.0: Criação de Vídeo Multimodal

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: A Comparação Definitiva de Geração de Vídeos

Guia Completo do Seedream 5.0-Preview: Geração Inteligente de Imagens

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Comparação Completa
