Z-Image LoRA: O Que Significa e Quando Você Precisa (Amigável para Iniciantes)

Oi, amigos. Dora por aqui. Não planejei treinar nada semana passada. Só queria um pequeno ajudante consistente, um personagem ilustrado para ficar no canto de minhas capturas de tela. Os prompts continuavam me deixando perto, depois desviavam. As sobrancelhas mudavam. As cores escorregavam. Na terça (13 de janeiro de 2026), depois de alguns quase acertos, tentei Z-Image LoRA. Esperava um buraco de coelho. Foi mais como um corredor curto.
Isso não é uma volta triunfal. Não foi instantâneo. Mas a configuração removeu atrito suficiente para parar de pensar sobre configurações e começar a pensar sobre minhas imagens. Aqui está o que funcionou, o que não funcionou, e quando você provavelmente não precisa de um LoRA.
Z-Image LoRA em um minuto
Um LoRA (Low-Rank Adaptation) é um pequeno complemento que você treina em cima de um modelo de imagem base para empurrá-lo em direção a um estilo ou assunto específico sem retreinar o modelo inteiro.
 O que Z-Image LoRA (Amigável para Iniciantes) faz bem:
O que Z-Image LoRA (Amigável para Iniciantes) faz bem:
- Esconde os controles assustadores. Você ainda escolhe alguns básicos (imagens, legendas, alvo), mas os padrões são sensatos.
- Treina rápido o suficiente para iterar. Meu primeiro passe (10 imagens) levou cerca de 12–18 minutos em uma GPU de gama média.
- Carrega como uma camada. Você a ativa em sua ferramenta de geração e prompta como normal, mais uma palavra de gatilho opcional.
O que você recebe: um arquivo minúsculo que ajusta o modelo quando você precisa de consistência, logotipos, um personagem, uma aparência de aquarela com pinceladas, sem ficar preso. Se você não ativar, o modelo base se comporta normalmente.
Quando você NÃO precisa de LoRA
Digo isso com carinho: muitos de nós recorremos ao treinamento muito rápido. Alguns casos em que não me incomodo:
- O modelo base já está próximo. Se um prompt curto com uma imagem de referência te oferece resultados 8/10 que você pode usar, pronto. Um IP-Adapter ou prompt de imagem pode ser o suficiente.
- Você precisa de variação, não consistência. Se cada saída deveria ser diferente, um LoRA pode sobrecontrolar.
- Visuais únicos. Para um único banner, vou gastar cinco minutos extras promptando em vez de configurar treinamento.
- A limitação está na composição, não na identidade. Ferramentas como ControlNet ou orientação de pose moldam o layout sem ensinar ao modelo um novo conceito.
Um teste rápido que uso: se uma varredura de seed simples e 2–3 ajustes de prompt não conseguem manter o elemento que me importa (mesmo personagem, mesmas proporções de logo) em cinco imagens, é quando considero um LoRA. Caso contrário, mantenho simples.
Quando LoRA ajuda
Senti a diferença principalmente em duas situações esta semana (janeiro de 2026):
- Um pequeno mascote que queria reutilizar em documentos. Os prompts continuavam tremendo os olhos e a cor da camiseta. Depois de um LoRA curto, esses se estabilizaram, e consegui focar em poses e fundos.
- Uma textura de lápis suave para diagramas. Poderia promptar “lápis esboço,” mas o sombreamento mudava toda vez. Um LoRA de estilo de 15 imagens me deu uma qualidade de linha consistente sem fixar conteúdo.
Sinais de que um LoRA provavelmente ajudará:
- Você precisa do mesmo assunto em muitas cenas.
- Uma textura de arte específica importa (hachura cruzada, pontos risógrafo, arestas de goma-laca espessas) e continua desviando.
- Você quer reduzir o esforço do prompt. Depois do treinamento, meus prompts caíram de 80–100 tokens para 30–40. O esforço mental caiu mais que o tempo.
O que me surpreendeu foi como o impacto pareceu silencioso. Nenhum antes/depois dramático. Só menos tentativas, menos “quase acertos.”
Requisitos de dados
 Mantive isso simples e funcionou melhor do que esperava. Algumas notas de dois curtos passos semana passada:
Mantive isso simples e funcionou melhor do que esperava. Algumas notas de dois curtos passos semana passada:
Quantidade
- Personagem/assunto: 8–20 imagens podem ser suficientes se forem variadas (ângulos, iluminação, mudanças leves de roupa). Usei 12.
- Estilo/textura: 10–30 imagens que compartilham o mesmo visual mas conteúdo diferente. Usei 15.
Qualidade
- Resolução: alimentar imagens que correspondam aproximadamente ao seu tamanho de geração. Se você planeja gerar em 1024, não treine em pequenos cortes de 256.
- Variedade bate volume: Cinco cópias da mesma pose ensinam muito pouco ao modelo e o empurram em direção ao sobreajuste.
- Fundos limpos ajudam para personagens: Cenas movimentadas borram o sinal.
Legendas
- Curtas e literais: “um pequeno mascote azul com olhos redondos, camiseta vermelha,” “esboço de lápis, hachura cruzada, sombra suave.”
- Seja consistente com nomes. Se você inventar um nome único para um personagem (como “mori-kiko”), use-o em toda legenda para poder acioná-lo depois.
- Você pode começar com legendas automáticas, depois limpá-las levemente. Cortei adjetivos que não refletiam a ideia central.
Processo que usei
- 12 fotos de assunto (frente/três-quartos/lado), fundos neutros.
- 15 frames de estilo de meus próprios diagramas, mesma textura de papel.
- Um passe, classificação padrão, regularização leve. Tempo de treinamento: ~16 minutos em uma A10G alugada. Configuração: ~10 minutos. A segunda execução usou 20% menos passos e manteve bem.
Se você apenas lembrar uma coisa: menos imagens claras batem grandes pastas barulhentas.
LoRA de Estilo vs Personagem
Costumava agrupar esses juntos. Eles se comportam diferentemente.
LoRA de Personagem/Assunto
- Objetivo: ensinar uma identidade específica (uma pessoa, mascote, produto).
- Dados: assunto consistente, contextos variados: close-ups de rosto se a identidade facial importa.
- Prompts: mantenha o nome do gatilho mais uma descrição curta. Deixe o LoRA lidar com identidade: você dirige pose/cena.
- Riscos: sobreajuste a roupas ou fundos. Misture.
LoRA de Estilo/Textura
- Objetivo: ensinar uma qualidade de superfície (trabalho de linha, paleta, acelerada de pincel, grão).
- Dados: muitos assuntos diferentes, um estilo.
- Prompts: nenhum nome de gatilho necessário, mas um marcador simples ajuda (“estilo esboço”).
- Riscos: estilo engolindo conteúdo. Se tudo se torna a mesma pintura mole, reduza força.
Força e mistura
- A maioria das ferramentas expõe um peso LoRA. Raramente vou acima de 0.8 para personagens ou 0.6 para estilos. Pequenos ajustes importam.
- Você pode empilhar dois LoRAs (um estilo, um personagem). Tive os melhores resultados quando um era dominante e o outro ficava abaixo de 0.4.
Aprendi a pensar em LoRA de personagem como “quem” e LoRA de estilo como “como.” Simples, mas mantém-me de culpar a coisa errada.
Mitos comuns
Alguns argumentos que encontro muito, e o que realmente vi:
- “Você precisa de centenas de imagens.” Treinei um personagem usável com 12. Mais ajuda, mas apenas se forem variadas e limpas.
- “Leva horas.” Com uma GPU modesta e uma predefinição para iniciantes, minhas execuções saíram em menos de 20 minutos. Configurações pesadas e personalizadas podem levar mais.
- “LoRA substitui engenharia de prompt.” Reduz ajustes mas não remove. Ainda prompto para composição, iluminação e humor.
- “Um LoRA serve para todos os modelos.” Nem sempre. Um LoRA treinado em uma base pode se transferir ok para um modelo irmão, mas resultados mudam. Trato como relacionado, não intercambiável.
- “Força maior = melhor.” Passado de um ponto, imagens desabam em igualdade. Se os detalhes se mancharem, baixe o peso.
- “Legendas automáticas ficam bem não editadas.” São um bom começo. Ainda cortei adjetivos estranhos (“ominoso,” “cinemático”) que não eram parte do conceito.
Nada disso é mágico. São pequenos ajustes repetíveis que se acumulam.
Glossário rápido
- LoRA: Um conjunto compacto de atualizações de peso aprendidas que adapta um modelo grande em direção a um conceito alvo sem retreinar tudo. De acordo com documentação LoRA da IBM, pode reduzir parâmetros treináveis em até 10.000 vezes comparado ao ajuste fino completo.
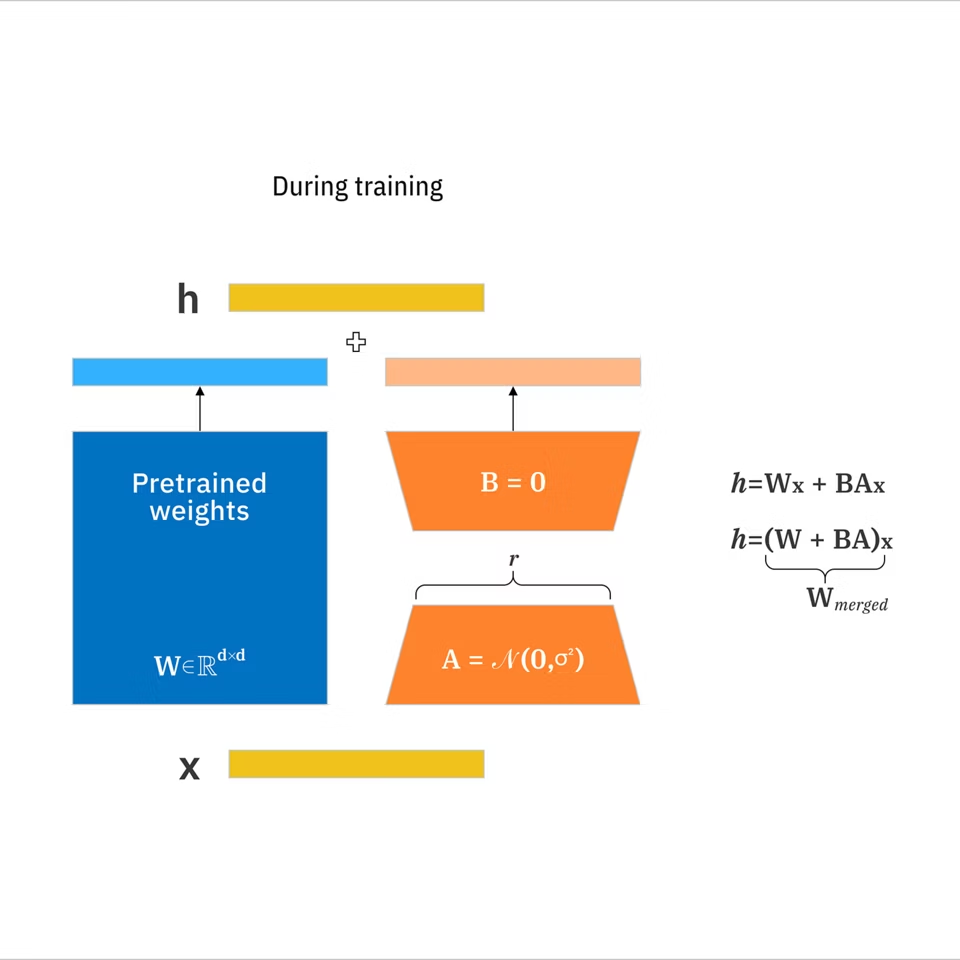
- Modelo base: A fundação de que você gera (o que você carrega antes de qualquer LoRA).
- Classificação (r): Uma configuração que controla quão expressivo é o LoRA. Classificação mais alta pode capturar mais nuance mas pode sobreajustar e aumentar tamanho.
- Peso/Força: O quão fortemente o LoRA influencia a geração no tempo de inferência.
- Palavra de gatilho: Um token único que você usa em prompts para chamar um LoRA de assunto (por exemplo, o nome inventado que você usou em legendas).
- Sobreajuste: Quando o modelo memoriza imagens de treinamento e para de generalizar. Aparece como quase-duplicatas.
- Regularização: Técnicas ou dados extras para prevenir sobreajuste.
- UNet/Codificador de texto: Partes do modelo que lidam com imagens e texto. Alguns treinamentos atualizam ambos: predefinições para iniciantes frequentemente tocam o lado da imagem mais.
- Legenda: O texto emparelhado com cada imagem de treinamento.
- Ponto de verificação: Um estado salvo de um modelo ou LoRA.
Se algum desses parecer nebuloso, você ainda pode treinar. A predefinição para iniciantes é projetada para mantê-lo fora de problemas.
Próximos passos em WaveSpeed
Usei o caminho amigável para iniciantes em WaveSpeed para executar Z-Image LoRA sem perseguir configurações. O fluxo foi calmo:
- Escolha um modelo base.
- Jogue em 8–20 imagens e legendas curtas.
- Escolha “estilo” ou “personagem.”
- Comece o treinamento e faça chá.
- Carregue o LoRA para geração e tente dois pesos (0.4 e 0.8) para sentir o intervalo.
O que mais ajudou foi tratar a primeira execução como um esboço. Procurei duas coisas: a identidade se mantinha em cinco prompts, e o estilo mantinha sua textura sem engolir conteúdo? Se uma falhava, eu ajustava o conjunto de dados, não só os controles.
Se você está lidando com as mesmas limitações, personagens à deriva, texturas desviando, vale a pena dar uma olhada. Isso funcionou para mim: seus resultados podem variar.
É exatamente por isso que construímos WaveSpeed. Quando personagens derivam, estilos oscilam, e prompts se tornam ginástica, queríamos um modo mais calmo para obter consistência sem superengineering. Em WaveSpeed, executamos Z-Image LoRA com um fluxo amigável para iniciantes—padrões claros, iteração rápida, e apenas controle suficiente para manter identidades e texturas estáveis, para você possa gastar menos tempo retentando e mais tempo realmente fazendo imagens.
→ Treine um LoRA simples em WaveSpeed
 Uma pequena nota que estou guardando para mim: quanto menos palavras eu combato no prompt, mais atenção tenho para a imagem na minha frente. É a parte que não quero automatizar.
Uma pequena nota que estou guardando para mim: quanto menos palavras eu combato no prompt, mais atenção tenho para a imagem na minha frente. É a parte que não quero automatizar.
Artigos relacionados

Seedance 2.0 em Breve: Modelo de Vídeo de Próxima Geração do ByteDance com Áudio Nativo

Guia Completo do Seedance 2.0: Criação de Vídeo Multimodal

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: A Comparação Definitiva de Geração de Vídeos

Guia Completo do Seedream 5.0-Preview: Geração Inteligente de Imagens

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Comparação Completa
