DeepSeek V4 vs Claude Opus 4.5 para Programação: Comparação de Desempenho

Ei pessoal! Sou a Dora aqui. No último domingo de manhã, eu estava pulando entre meu editor e uma janela de chat para corrigir um teste instável, e o modelo continuava inventando uma importação que não existia. Não é nada de especial, apenas um daqueles pequenos incômodos que desaceleram seu trabalho. Eu queria ver se trocar de modelo aliviaria a carga, não apenas no tempo total, mas no esforço mental necessário para confiar no que chega no meu repositório.
Então passei a última semana (27 de janeiro - 1º de fevereiro de 2026) executando um loop simples e repetível: mesmas tarefas, mesmas versões do repositório, alternando DeepSeek V4 e Claude Opus 4.5. Isso não é um estudo de laboratório. É o tipo de verificação que eu faria antes de integrar um modelo na CI. Se você também está avaliando DeepSeek V4 versus Claude Opus 4.5 para codificação, essas são as anotações que eu gostaria de ler antes de fazer a mudança.

Líderes de Benchmark Atuais
Ranking do SWE-bench Verified
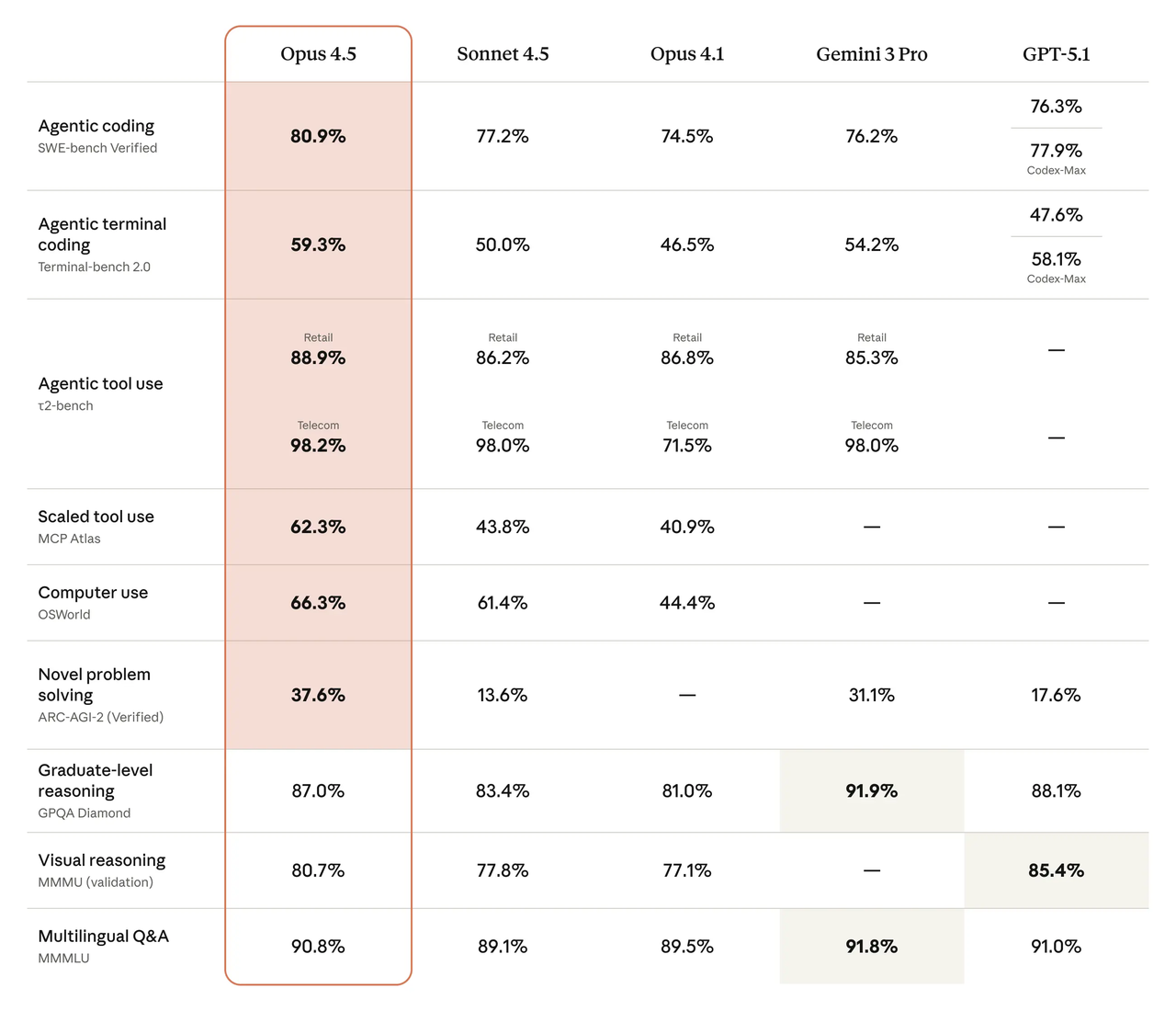
Quando preciso de uma avaliação rápida de para onde o vento está soprando, começo com os leaderboards públicos. No leaderboard do SWE-bench Verified, os modelos recentes do DeepSeek e a família Claude mais recente da Anthropic ficam perto do topo, com pequenas diferenças que mudam semana a semana conforme os prompts, ferramentas e harnesses de avaliação mudam. O que importa para mim não é o número único, mas o padrão: quais modelos resolvem problemas de ponta a ponta consistentemente sem depender de ferramentas, e quão sensíveis eles são a ajustes de prompt.
Minha leitura rápida, em princípios de fevereiro de 2026:
- DeepSeek V4 mostra forte movimento em tarefas multi-arquivo e em escala de repositório quando você oferece todo o contexto que ele pede. Ele se beneficia de prompts longos e mapas de arquivo explícitos.
- Claude Opus 4.5 apresenta resultados consistentes e tende a regredir menos quando eu corto o contexto ou removo mensagens de sistema. Não é chamativo, mas o piso parece alto.
Pontuações HumanEval
HumanEval é mais restrito, problemas de codificação curtos com testes unitários, mas é um teste útil para geração de código fora da caixa. Resumos atuais no repositório OpenAI HumanEval e rastreadores comunitários como o leaderboard EvalPlus colocam ambos os modelos no topo. Eu não me fixo no valor exato de pass@1 aqui: eu observo a estabilidade entre diferentes seeds e com que frequência um modelo depende de truques de linguagem em vez de escrever código direto e idiomático.
 Nas minhas execuções, DeepSeek V4 às vezes produzia soluções mais longas e “explicativas”, tudo bem, mas nem sempre o que eu quero em um diff apertado. Claude Opus 4.5 mais frequentemente retornava funções compactas que passavam nos testes sem comentário extra. Os benchmarks sugerem essa diferença: o trabalho prático deixou isso óbvio.
Nas minhas execuções, DeepSeek V4 às vezes produzia soluções mais longas e “explicativas”, tudo bem, mas nem sempre o que eu quero em um diff apertado. Claude Opus 4.5 mais frequentemente retornava funções compactas que passavam nos testes sem comentário extra. Os benchmarks sugerem essa diferença: o trabalho prático deixou isso óbvio.
Onde Cada Modelo se Destaca
Contexto Longo (DeepSeek)
Se você quer reproduzir essa configuração de ponta a ponta, preparei um breve guia de início rápido do DeepSeek V4 que explica o chat e os fundamentos da API que estou usando aqui.
Dei a ambos os modelos uma tarefa real: refatorar um pequeno serviço FastAPI que havia crescido silenciosamente em um emaranhado. Cerca de 14 arquivos importavam, mais um README que era… otimista. Compactei a versão do repositório e passei resumos de arquivo junto com um gráfico de chamadas que gerei com um script rápido. DeepSeek V4 pareceu calmo com a dispersão. Acompanhava os efeitos entre arquivos e não entrava em pânico quando eu pedia um plano em etapas: interfaces primeiro, testes segundo, handlers por último. A parte surpreendente foi como ele usou bem as dicas estruturais; quando passei um simples “mapa” de nomes de arquivo e responsabilidades, ele parou de sugerir edições para arquivos que não existiam.
Duas anotações práticas:
- Ele precisava de espaço para respirar. Quando eu comprimia o contexto agressivamente, ele ficava cauteloso e começava a pedir para ver arquivos que já havia fornecido. Uma vez que dei a ele o quadro completo, ele se moveu limpo.
- Ele lidava bem com prompts “O que estou perdendo?”. Eu perguntava por casos extremos com base no conjunto de testes e ele apresentava três que eu havia esquecido: headers de autenticação vazios, um parâmetro de paginação quebrado e um caminho lento no logging de erro.
Isso não economizou tempo no início. A configuração inicial, empacotamento de contexto, escrita de um mapa de arquivo curto, levou cerca de 20 minutos. Mas depois de algumas execuções, a carga mental diminuiu. Eu não estava malabarando tantas preocupações “eu contei para ele sobre X?”. Se seu dia de codificação parece diffs grandes espalhados por múltiplos módulos, DeepSeek V4 tem uma mão firme quando o contexto fica amplo.
Confiabilidade do Código (Claude)
 Claude Opus 4.5 me conquistou de uma maneira diferente: menos arestas afiadas. Quando pedi um patch mínimo, recebi um. Quando pedi um plano de três etapas com uma execução seca, ele não alucinoou comandos. E ele resistiu ao impulso de “melhorar” coisas que não pedi.
Claude Opus 4.5 me conquistou de uma maneira diferente: menos arestas afiadas. Quando pedi um patch mínimo, recebi um. Quando pedi um plano de três etapas com uma execução seca, ele não alucinoou comandos. E ele resistiu ao impulso de “melhorar” coisas que não pedi.
Um pequeno exemplo: eu tinha um teste instável em volta de matemática de fusos horários. Meu prompt era blunt: “Corrija o teste sem alterar o código de produção, e explique a causa raiz em uma frase.” Claude sugeriu parametrizar o fixture tz e ajustar uma única asserção para usar um datetime consciente. Passou na primeira tentativa. DeepSeek também corrigiu, mas tentou refatorar o helper ao mesmo tempo. Não errado, apenas mais pesado do que eu queria.
Ao longo de cinco tarefas, os diffs do Claude foram consistentemente menores. Menos importações apareceram do nada. E quando ele adivinhou, deixou uma anotação arrumada: “Assumindo que pytz está disponível: caso contrário, substitua por zoneinfo.” Esse tipo de sugestão hedged é fácil de auditar.
Dois limites apareceram:
- Claude foi conservador em performance. Em um caso, escolheu clareza sobre uma simples melhoria O(n) que DeepSeek apontou imediatamente. Eu tive que empurrá-lo: “Otimize sob as mesmas restrições.” Ele fez, mas não saltaria primeiro.
- Com prompts muito longos, atingi o teto mais rápido. Resumos ajudaram, mas DeepSeek pareceu menos apertado quando eu queria que o modelo “mantivesse o aplicativo inteiro em sua mente.”
Se seu dia é principalmente patches cirúrgicos, reparos de teste e código cola em volta de APIs, Claude Opus 4.5 mantém mudanças enxutas e previsíveis. Isso, na prática, é confiabilidade que consigo sentir.
Como Executar Sua Própria Comparação
 Se você está em dúvida sobre DeepSeek V4 versus Claude Opus 4.5 para codificação, um experimento curto e entediante diz mais do que qualquer leaderboard. Aqui está o loop que usei, ajuste livremente.
Se você está em dúvida sobre DeepSeek V4 versus Claude Opus 4.5 para codificação, um experimento curto e entediante diz mais do que qualquer leaderboard. Aqui está o loop que usei, ajuste livremente.
1. Escolha tarefas que ecoem sua semana
- Uma tarefa do repositório (refatoração ou extração de módulo)
- Um teste instável
- Uma mudança de integração de API
- Um pequeno ajuste de algoritmo
Mantenha cada um sob 45 minutos. Defina um prazo para a interação, não apenas para a geração do modelo.
2. Congele as entradas
- Fixe um commit específico. Não mude o alvo enquanto testa.
- Decida o que o modelo pode ver: arquivos completos versus trechos. Escreva um mapa de arquivo curto se estiver passando trechos.
- Use o mesmo estilo de prompt do sistema para ambos os modelos. Eu mantenho simples: “Você é um assistente de codificação útil. Prefira diffs mínimos e código executável.”
3. Escreva prompts que você pode reutilizar
- Tarefa: “Aqui está o objetivo, restrições e testes.”
- Contexto: lista de arquivo ou resumos, mais armadilhas conhecidas.
- Formato de saída: “Proponha um plano (bullets), depois o diff, depois uma anotação de risco de uma frase.”
4. Capture os mesmos sinais para ambos
- Tentativas para passar nos testes (1–N)
- Linhas alteradas no diff (aproximado está bem)
- Anotações que você tivera que escrever para o modelo (“Pare de editar X”, “Use o helper existente Y”)
- Tempo para o primeiro teste verde
5. Proteja contra vazamento
- Desabilite ferramentas a menos que você planeje comparar o uso de ferramentas. Se um modelo executa shell e o outro não, você não está testando a mesma coisa.
- Se você permitir recuperação, aponte ambos para o mesmo snapshot de documentação.
6. Verificação de sanidade com benchmarks, não os adore
- Dê uma olhada no SWE-bench Verified para ver se seus resultados parecem extremamente diferentes. Se forem, verifique seus prompts antes de culpar o modelo.
- Para problemas pequenos, dê uma olhada em amostras de HumanEval no repositório oficial ou execute algumas localmente. Consistência em alguns seeds é mais revelador do que uma única execução.
7. Opcional: adicione uma pequena rubrica
Pontuação 1–5 em:
- Minimalismo do diff (ele tocou apenas o que precisava?)
- Disciplina de fixture (testes, env, dependências)
- Comportamento de recuperação (ele se autocorrige quando você aponta uma falha?)
- Qualidade da explicação (uma ou duas frases claras, não um artigo de blog)
O que eu observo na prática
- O modelo respeita restrições na primeira vez?
- Quando está errado, está errado de uma forma que é fácil de detectar?
- Eu me sinto seguro deixando-o propor um patch enquanto estou alternando contexto?
Isso funcionou para mim, seus resultados podem variar. O ponto não é coroar um vencedor: é ver qual reduz seu atrito cognitivo com seu código, em seu cronograma.
Artigos relacionados

Seedance 2.0 em Breve: Modelo de Vídeo de Próxima Geração do ByteDance com Áudio Nativo

Guia Completo do Seedance 2.0: Criação de Vídeo Multimodal

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: A Comparação Definitiva de Geração de Vídeos

Guia Completo do Seedream 5.0-Preview: Geração Inteligente de Imagens

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Comparação Completa
