Seedance 1.5 Pro: A Major Step Toward Native Audio-Visual Generation

As generative video moves into real production, visuals alone are no longer sufficient. Modern workflows increasingly require video and audio to be generated together—natively and in sync.
Seedance 1.5 Pro, ByteDance’s next-generation model for native audio-visual co-generation, is now available on WaveSpeedAI. Built from the ground up for reliable, controllable, and production-ready synchronization, it marks an important step toward truly unified multimodal generation.
In an upcoming technical-leaning article, we’ll take a closer look at Seedance 1.5 Pro—exploring its model capabilities, practical use cases, benchmark insights, and the multimodal architecture behind it.
Core Model Capabilities (Features & Practical Use)
1. Native Audio‑Visual Generation with High‑Fidelity Sync
The most fundamental breakthrough in Seedance 1.5 Pro is its audio‑visual‑native generation paradigm. In a single inference pass, the model produces both the video frames and the corresponding audio track, keeping speech rhythm, lip movement, character motion, and camera dynamics aligned within the same temporal reference.
Across multiple evaluation rounds, Seedance 1.5 Pro consistently outperformed mainstream “video + TTS” stitching pipelines — especially in long dialogue, rapid lip movement, and action‑with‑sound scenarios where traditional approaches tend to drift.
Prompts: A handsome man stands atop a mist-shrouded mountain ridge. He wears sleek, practical outdoor gear — a dark charcoal windproof jacket, professional climbing pants, and a backpack over both shoulders. The mountain breeze lightly tousles his hair; his expression is calm and resolute. Behind him, surging clouds and mist swirl among jagged rocks, occasionally parting to reveal distant snow-capped peaks. The camera slowly pushes in from behind as he gazes into the abyss of rolling clouds below. In the frigid air, his breath condenses into white mist, adding natural atmospheric detail. He slightly turns toward the camera, his sharp eyes filled with unyielding determination, and says in a steady, powerful voice: “I like challenges.”
2. Multi‑Speaker, Multi‑Language, and Dialect‑Aware Generation
Seedance 1.5 Pro supports audio-visual generation across major global languages and regional dialects. It preserves language-specific timing, phonemes, and expressions, delivering precise lip-sync and natural emotional alignment—even across multiple speakers and rapid language switches.
Prompts: A highly cinematic Japanese anime–style short film depicting the grandeur of a summer fireworks festival. Emphasis is placed on high-detail textures (kimono fabric, hair, skin), subtle micro-expressions, natural and fluid movement, and delicate, emotionally rich storytelling. Fireworks resemble soft cinematic lighting, enhancing the emotional atmosphere. (prompt omitted…) She softly says in Japanese: “I like you very much”. The man bows slightly and resolves to speak: “Actually, I like you as well”. (prompt omitted…)
3. Expressive Motion & Emotional Performance
Seedance 1.5 Pro moves beyond conservative, low‑risk motion strategies. Character animation shows greater amplitude, richer tempo variation, and clearer emotional intent — while maintaining overall stability.
Facial expressions progress from merely recognizable to genuinely performative: micro‑expressions, emotional transitions, and body language align naturally with spoken dialogue. The result is motion that feels noticeably more alive.
Prompts: A young astronaut in a worn spacesuit sits in the dim cockpit of a spacecraft. The helmet visor is covered with fog and scratches, and the control panel flickers with orange-yellow lights, creating a tense and lonely atmosphere. The video begins with this static opening frame. The camera then rapidly zooms into the astronaut’s face before cutting to the exterior, revealing the spacecraft racing through a blizzard-like storm of cosmic debris. Sci-fi thriller style. Background music: low electronic synthesizers paired with rapidly swelling strings to build suspense. Sound effects: urgent engine hums and howling space-storm noise. Dialogue: “In the void of space, one wrong move…” followed by a brief silence, ending with: “Mayday… systems failing.”
4. Cinematic, Photoreal‑Oriented Visual Aesthetics
Visually, Seedance 1.5 Pro leans toward a natural, live‑action look rather than heavy stylization or over‑rendered effects.
Lighting, composition, color harmony, and depth‑of‑field are consistently stable, producing outputs that approach commercial‑grade cinematography rather than synthetic imagery.
Prompts: First-person POV from the front seat of a giant steel roller coaster. The coaster crests the peak and plunges straight down into a dark tunnel. Surrounding scenery (an amusement park at sunset) is slightly blurred, while the wind is represented as whistling air particles.
5. Automatic Video Duration Adaptation
By setting the video length parameter to -1, Seedance 1.5 Pro automatically selects the most appropriate duration within a 4–12 second range (integer seconds only).
The model evaluates narrative rhythm, motion completeness, and audio‑visual closure to choose a natural endpoint. This reduces wasted generations and manual tuning caused by poorly chosen fixed durations.
Prompts: 8-bit pixel art style, a hero running and jumping under the sunset, with scanline effects and retro video game music.
6. Built‑In Effects via Prompt Control
Seedance 1.5 Pro includes a range of built‑in effects directly within the base model. These can be triggered via prompt instructions instead of relying entirely on post‑production compositing.
This is particularly valuable for animation‑heavy or stylized content — such as motion comics — where effects density and timing are critical.
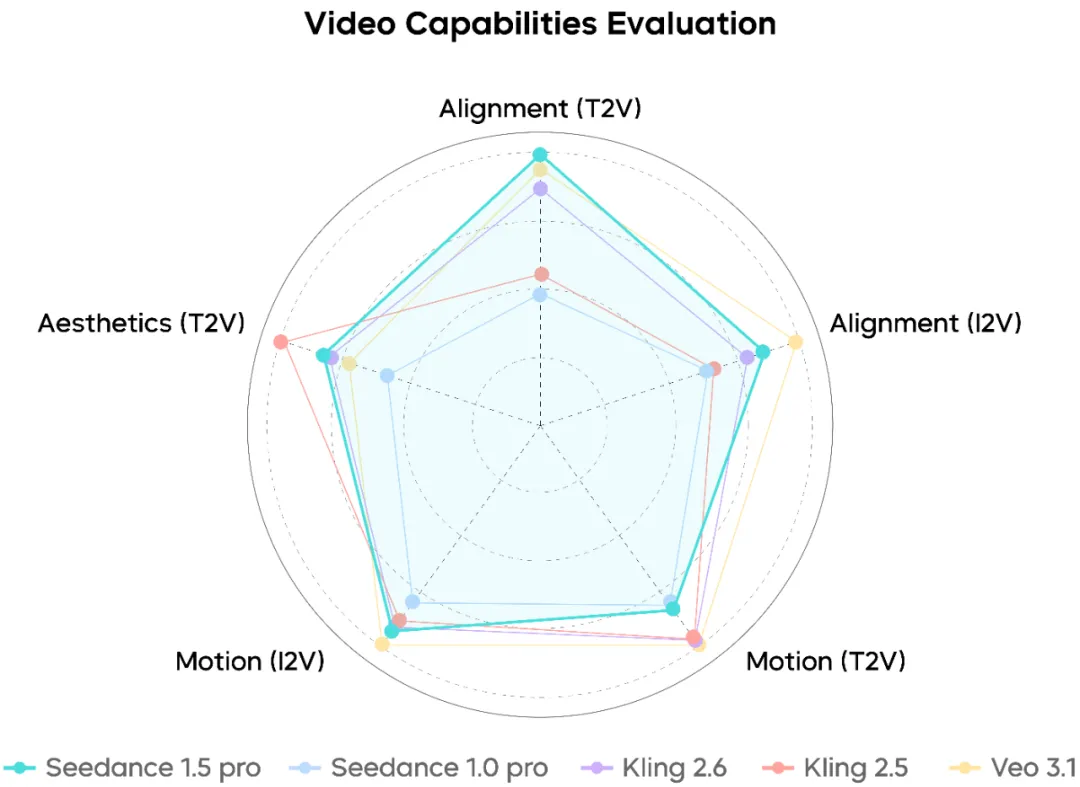
Video Generation Performance
Seedance 1.5 Pro demonstrates strong understanding of complex prompts involving camera choreography, action sequencing, and narrative pacing. Facial close‑ups appear natural, while long takes and compound camera moves remain relatively smooth and coherent.
That said, under extremely high-intensity motion scenarios, there remains room for further stability improvements.
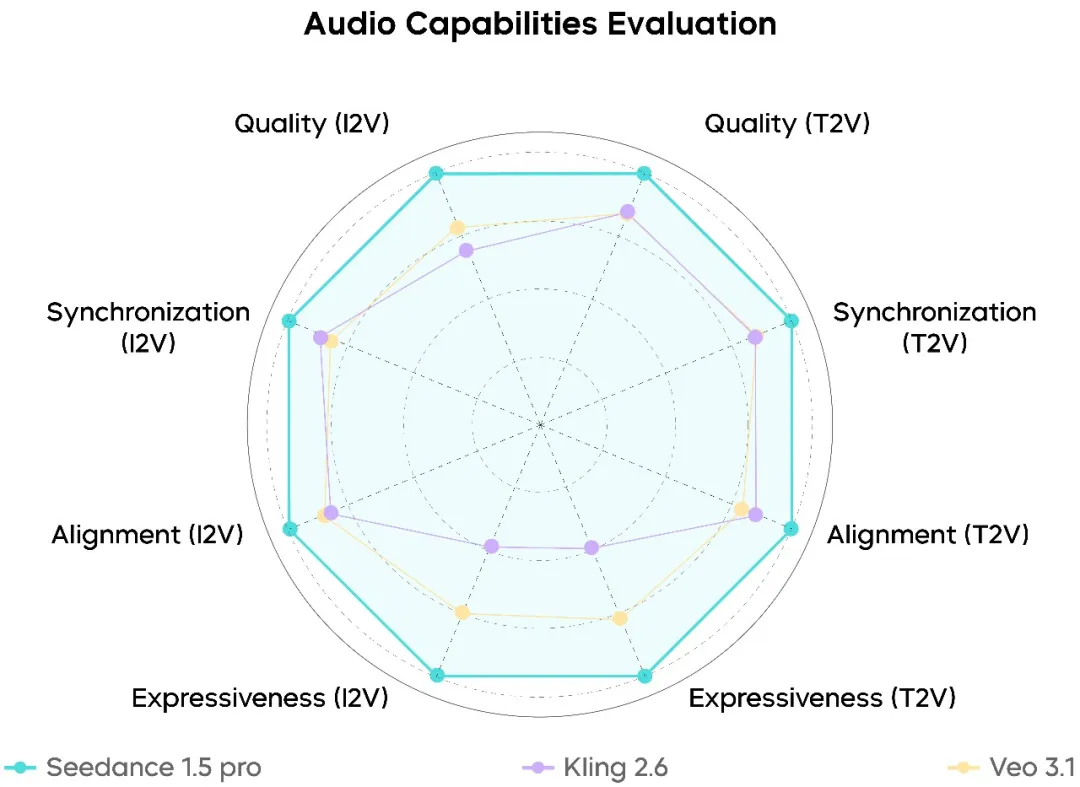
Audio Generation Performance
On the audio side, Seedance 1.5 Pro sits firmly in the top tier of current models:
- Highly natural human voices with reduced mechanical artifacts
- More realistic spatial audio and reverb characteristics
- Significantly fewer audio‑visual alignment errors
Performance is particularly strong in Chinese and dialect‑heavy dialogue, where pronunciation completeness and clarity already meet real production requirements.
Multimodal Co‑Generation Architecture: How Vision and Audio Stay in Sync
Seedance 1.5 Pro is not a patchwork of independent modules — its training and inference pipeline was redesigned end‑to‑end.
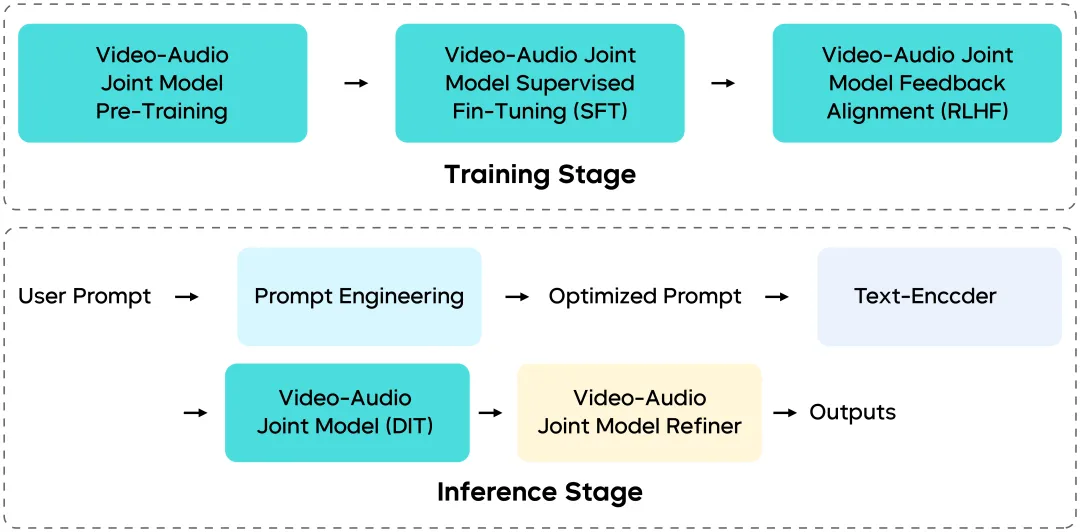
Unified Multimodal Architecture (MMDiT‑Based)
Built on an enhanced MMDiT‑style architecture, the model enables deep interaction between visual and audio streams within the same temporal space, ensuring:
- Temporal synchronization
- Semantic consistency
- Coordinated emotion and rhythm
Large‑scale mixed‑modal, multi‑task training further improves generalization across downstream tasks.
Multi‑Stage Data Pipeline
The data pipeline is designed to balance:
- Audio‑visual alignment
- Motion expressiveness
- Curriculum‑based training schedules
In addition to traditional video‑caption data, structured audio descriptions are systematically introduced, allowing the model to internalize a richer joint audio‑visual semantic space.
Fine‑Grained Post‑Training & RLHF
High‑quality audio‑visual datasets are used for supervised fine‑tuning, alongside RLHF models specifically designed for audio‑visual output, reinforcing:
- Motion quality
- Visual aesthetics
- Audio fidelity
Efficient Inference & Deployment Readiness
Through multi‑stage distillation, quantization, and parallel inference optimizations:
- The number of function evaluations (NFE) is significantly reduced
- End‑to‑end inference achieves 10×+ speedups while maintaining quality
This efficiency is a key reason Seedance 1.5 Pro can be deployed reliably on WaveSpeedAI.
Production‑Ready Use Cases
Seedance 1.5 Pro is particularly well‑suited for:
- Cross‑border e‑commerce and localized advertising
- Short‑form narrative and episodic content
- Motion comics and expressive animation
- Brand storytelling and cinematic marketing
- Film pre‑visualization and concept validation
Final Thoughts
The value of Seedance 1.5 Pro isn’t about proving that models can generate sound—it’s about setting the stage for audio-visual coordination to become a dependable default.
For teams pursuing scalable content production, this unified, from-the-ground-up approach promises fewer post-production fixes, greater creative freedom, and a generative video workflow designed to hold up in real production environments.
Related Articles

daVinci-MagiHuman: The Open-Source Model That Just Crushed Every Digital Human Generator

Introducing Google Lyria 3 Clip on WaveSpeedAI

Introducing Google Lyria 3 Pro on WaveSpeedAI

Best Free AI Image Generator Online in 2026: 10+ Models, One Click, Zero Hassle

Best Free AI Video Generator Online in 2026: Sora, Kling, Veo, Seedance — All in One Place
