Muse Spark vs Llama 4: Meta's Strategic Shift
Meta moved from open-weight Llama to closed Muse Spark. What changed, why it matters for builders, and whether open-source future versions are realistic.

Meta just launched a new model series. If you’ve built anything on Llama 4 in the past year, you’re probably wondering whether to keep going or start planning a migration.
I’m Dora. I spent yesterday reading through every piece of documentation Meta published, cross-referencing third-party benchmarks, and trying to figure out what this actually means for people with Llama in their stack. This piece breaks down what changed, what didn’t, and where builders sit right now.
What Changed Between Llama 4 and Muse Spark
Architecture: Nine Months, Ground Up
Meta Superintelligence Labs — the unit formed after Alexandr Wang joined as chief AI officer in mid-2025 — rebuilt the entire AI stack from scratch. New infrastructure, new architecture, new data pipelines. That’s not marketing copy; it’s what Meta’s own technical blog states. Muse Spark is the first model out of that rebuild.
Llama 4 used a Mixture-of-Experts architecture with open weights. Muse Spark is a natively multimodal reasoning model — meaning vision wasn’t bolted on after the fact, it was integrated from the start. It supports tool-use, visual chain of thought, and multi-agent orchestration. Llama 4 had none of these as native capabilities.
The model also introduces tiered reasoning modes: Instant for casual queries, Thinking for step-by-step work, and a Contemplating mode that runs multiple sub-agents in parallel. That last one is Meta’s answer to Gemini Deep Think and GPT Pro’s extended reasoning.
Efficiency: Meta’s Claim, Not Independent Conclusion
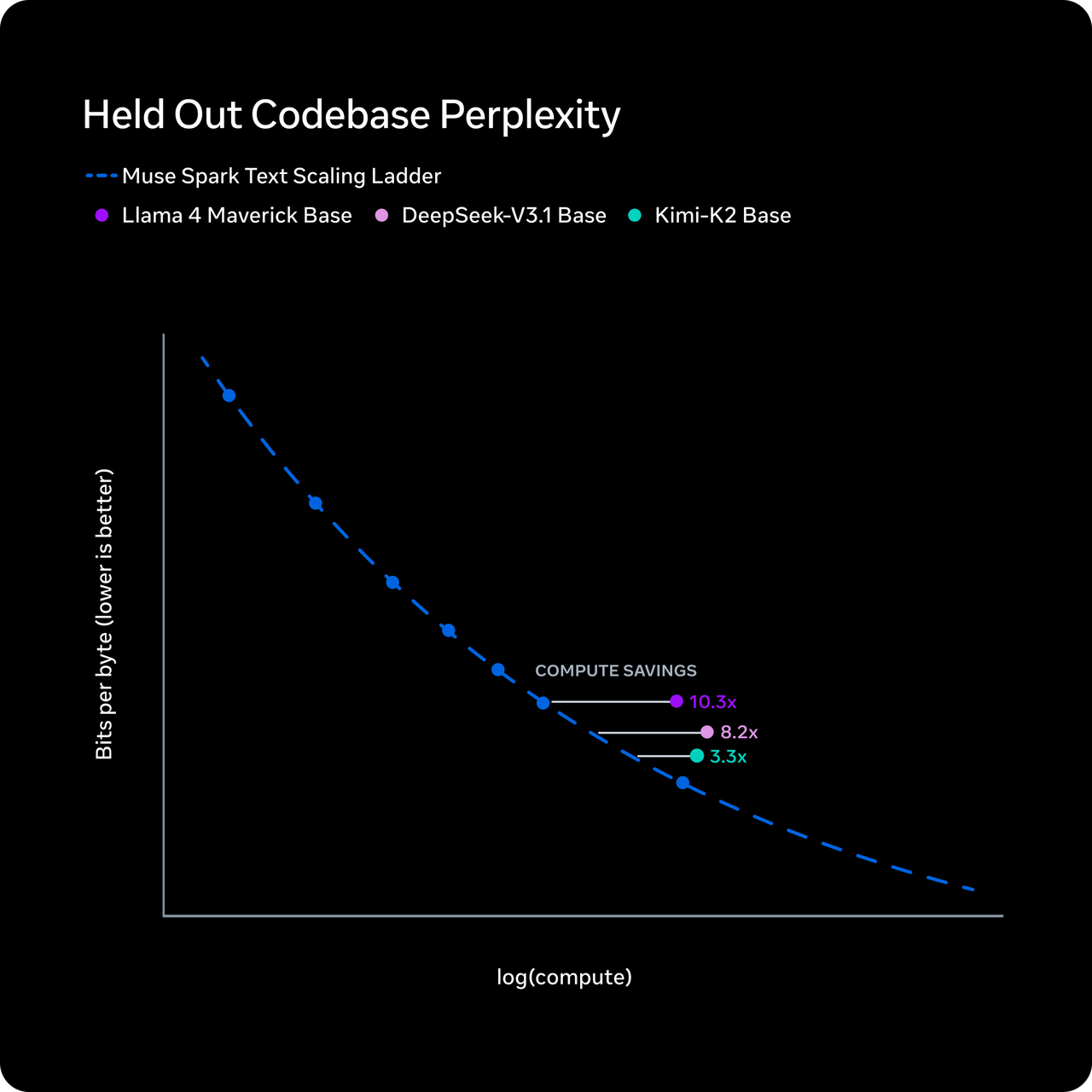
Meta says Muse Spark reaches Llama 4 Maverick-level capability using over ten times less compute. The mechanism they describe is “thought compression” — during reinforcement learning, the model gets penalized for excessive thinking time, forcing it to reason with fewer tokens without losing accuracy.
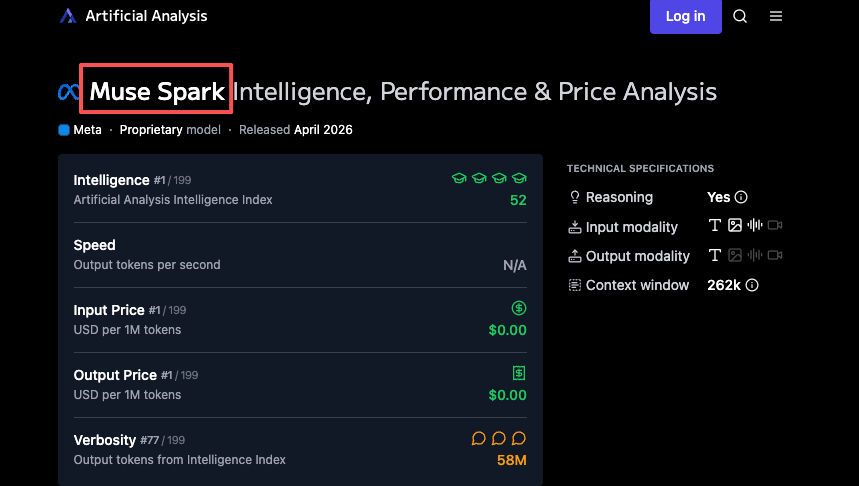
I want to be precise here: this is Meta’s claim. It hasn’t been independently replicated. The token efficiency numbers from Artificial Analysis do show Muse Spark used 58 million output tokens to run their full Intelligence Index — comparable to Gemini 3.1 Pro’s 57 million and far below Claude Opus 4.6’s 157 million or GPT-5.4’s 120 million. So the efficiency story has some independent support, at least on the output side.
Benchmark Gap: 18 to 52
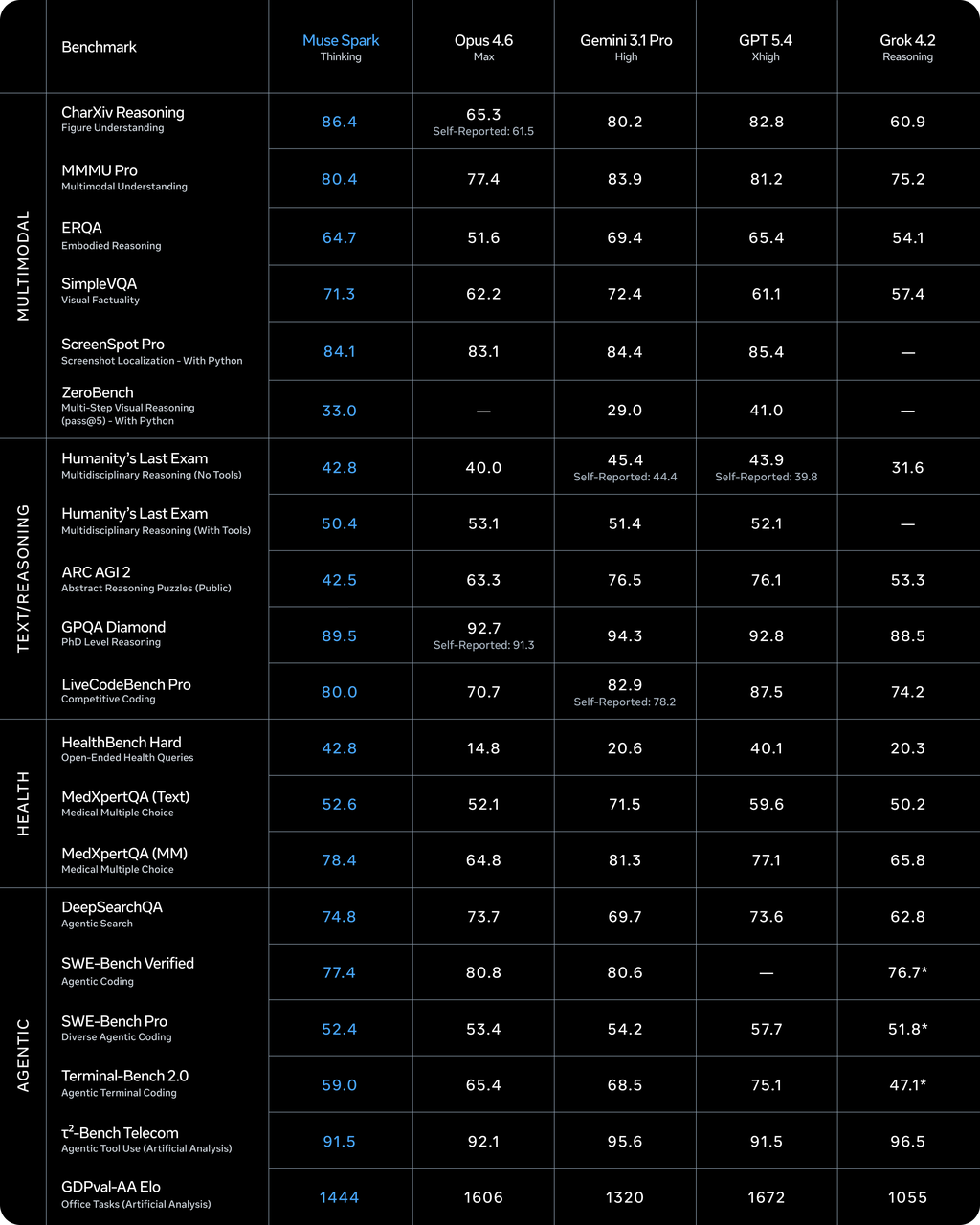
According to Artificial Analysis, Llama 4 Maverick scored 18 on the Intelligence Index at launch. Muse Spark scored 52. That puts it fourth overall — behind Gemini 3.1 Pro Preview and GPT-5.4 (both at 57) and Claude Opus 4.6 (53).
One important caveat: Artificial Analysis was given early access by Meta to benchmark the model. They ran their own evaluations independently, but the access itself came through Meta. These aren’t fully arms-length public benchmarks yet. The scores are directionally useful, not gospel.
Where Muse Spark leads: health benchmarks (42.8 on HealthBench Hard, ahead of GPT-5.4’s 40.1), visual reasoning (80.5% on MMMU-Pro, second only to Gemini 3.1 Pro), and chart understanding.
Where it trails: coding (Terminal-Bench Hard, behind Claude Sonnet 4.6 and GPT-5.4), agentic tasks (GDPval-AA 1,427 ELO vs. GPT-5.4’s 1,676), and abstract reasoning (ARC-AGI-2 at 42.5 vs. 76+ for top competitors). Meta acknowledged these gaps explicitly in their technical blog, stating they continue to invest in “long-horizon agentic systems and coding workflows.”
The Open vs. Closed Shift
Llama’s Model: Open Weights, Community Ecosystem
Llama’s value proposition was straightforward. Download the weights, run them on your own hardware, fine-tune for your use case, pay only for compute. The open-weight approach built an ecosystem — thousands of fine-tuned variants on Hugging Face, self-hosted deployments across startups and enterprises, an entire cottage industry of quantized models running on consumer GPUs. Llama 4 Scout fits on a single H100. Maverick runs on an RTX 5090 with quantization.
That ecosystem still exists. Those models haven’t been pulled.
Muse Spark’s Model: Closed, API Private Preview Only
Muse Spark is proprietary. No downloadable weights. No self-hosting. Right now it powers Meta AI across the company’s apps — the Meta AI website, and soon WhatsApp, Instagram, Facebook, Messenger, and Ray-Ban AI glasses. External developers can apply for a private API preview. That’s it.
This is more locked down than OpenAI or Anthropic’s models, which at least offer public API access. As Fortune noted in their coverage, Muse Spark is “even more proprietary than the paid proprietary models offered by Meta’s rivals.”

“We Hope to Open-Source Future Versions”
Meta’s blog post includes this phrase. Zuckerberg wrote on Threads about plans to release “increasingly advanced models that push the frontier of intelligence and capabilities, including new open source models.” Wang mentioned open-sourcing future versions on X.
No timeline. No specific commitment about which model or when. No indication whether “future versions” means Muse Spark itself eventually gets opened, or whether a separate open-weight branch continues in parallel.
Compare this to Zuckerberg’s 2024 manifesto titled “Open Source AI is the Path Forward,” where he argued that opening Llama doesn’t undermine Meta’s revenue. That was eighteen months ago. The strategic calculation has clearly shifted. As The Next Web’s analysis put it, the closure is a signal that Meta now considers itself in a race where giving away architectural innovations costs more than it gains.
This is where my data ends. Whether future Muse models actually get opened is speculation. I’ll update when there’s something concrete.
What This Means for Builders Currently Using Llama
Self-Hosted Llama: Still Viable, Not Deprecated
When VentureBeat asked Meta directly whether Llama development has ended, a spokesperson said: “Our current Llama models will continue to be available as open source.” That sentence is carefully worded. It confirms existing models remain available. It says nothing about future Llama development.
If you’re running Llama 4 Scout or Maverick in production today, nothing has changed operationally. The weights are still on Hugging Face. The community fine-tunes still work. Your infrastructure doesn’t need to move.
Operational Trade-offs: Today vs. Waiting
Here’s the practical situation. If you have a working Llama deployment — inference pipeline tuned, costs predictable, team familiar with the parameters — you have a known quantity. Muse Spark API pricing hasn’t been announced. Public API access hasn’t been announced. The private preview is invite-only.
Switching from a self-hosted open-weight model to a closed API means giving up control over latency, uptime, cost structure, and data handling. For some teams that trade-off makes sense. For others it doesn’t. The point is you can’t even evaluate the trade-off yet because Muse Spark’s API terms don’t exist publicly.
Coding Workflows: The Acknowledged Gap
If your Llama deployment handles code generation, code review, or any developer-facing task, there’s no reason to look at Muse Spark right now. Meta said it themselves — coding is a current weakness. On Terminal-Bench Hard, Muse Spark trails both Claude Sonnet 4.6 and GPT-5.4. On GDPval-AA, which measures real-world work tasks, it scores 1,427 ELO against Claude Sonnet 4.6’s 1,648.
Works for my frequency. Yours might differ. But the data is clear on this one.
Why Meta Made This Move
Llama 4: The Acknowledged Stumble
Llama 4 launched in April 2025 to mixed reception. The benchmark controversy — Meta used a specialized, unreleased “experimental chat version” to boost scores on LMArena — damaged credibility. The models themselves were solid for their weight class but didn’t move the frontier. By mid-2025, the narrative was that Meta had fallen behind OpenAI, Anthropic, and Google.
Wang’s Mandate
In June 2025, Meta spent $14.3 billion to acquire a 49% non-voting stake in Scale AI and brought in co-founder Alexandr Wang as chief AI officer. The mandate was explicit: catch up. Meta Superintelligence Labs was formed. Researchers were recruited from OpenAI, Anthropic, and Google with pay packages reportedly reaching hundreds of millions when equity was included.
Nine months later, Muse Spark is the first output. Whether it justifies the investment depends on what comes next — this model is deliberately small and fast, with larger versions already in development.
Competitive Pressure
The math is simple. OpenAI and Anthropic are collectively valued over $1 trillion. Google’s Gemini has gained traction in both consumer and developer markets. Meta was spending $72 billion on AI infrastructure in 2025, rising to a guided $115–135 billion in 2026, and had no frontier-competitive model to show for it. Something had to change.
Decision Framework for Builders
Stay With Llama If:
You need open weights — for self-hosting, fine-tuning, on-premises compliance, or cost control. You’re running coding-heavy workflows where Muse Spark has acknowledged gaps. You need predictable, self-managed infrastructure that doesn’t depend on a private API waitlist. You’ve already invested in Llama-specific tooling (quantization pipelines, LoRA adapters, custom evaluations).
Watch Muse Spark If:
You’re building within Meta’s product ecosystem — anything that integrates with Instagram, WhatsApp, Facebook, or Messenger. You need strong multimodal understanding, particularly visual reasoning or health-related tasks. You’re willing to wait for public API access and can evaluate once pricing and terms are available.
Neither Covers:
Image generation. Video generation. These are separate model categories. Muse Spark is text-output only, and Llama 4 is text-output only. If you need generation capabilities, you’re looking at entirely different tools.
FAQ

Can I still use Llama 4 after Muse Spark launched?
Yes. Llama 4 Scout and Maverick remain available on Hugging Face and through Meta’s API partners. Nothing has been deprecated or pulled.
Will Meta release Muse Spark weights?
Meta said it “hopes to open-source future versions of the model.” There’s no timeline, no specific commitment about Muse Spark itself, and no indication of what “future versions” means in practice. Treat this as aspiration, not plan.
Is Muse Spark better than Llama 4 for coding?
No. Meta explicitly acknowledges coding as a current gap. On coding-specific benchmarks, Muse Spark trails Claude Sonnet 4.6 and GPT-5.4. If coding is your primary use case, Llama 4 Maverick with fine-tuning or a purpose-built coding model is a better fit today.
When is the next Muse model coming?
Meta described Muse Spark as “the first step” with “larger models already in development.” No dates. No names. No specs beyond confirming they exist.
Does this affect the broader open-source AI ecosystem?
It’s a signal, not a death blow. Meta’s open-weight Llama models remain available. Other organizations — Mistral, DeepSeek, Alibaba’s Qwen — continue releasing open models. But Meta was the single largest corporate backer of open-weight frontier models. If their frontier investment shifts permanently toward closed models, the ecosystem loses its most well-funded contributor. That matters over years, not weeks.
That’s it. More to come when the API goes public.
Previous posts:
Related Articles

Introducing MiniMax Music 2.6 on WaveSpeedAI

Introducing WaveSpeedAI AI Breast Xpansion on WaveSpeedAI

Introducing WaveSpeedAI AI Instagram Model on WaveSpeedAI
Introducing WaveSpeedAI AI Parkour Video on WaveSpeedAI
Introducing WaveSpeedAI AI Talking Photos on WaveSpeedAI
