HappyHorse-1.0 vs Seedance 2.0: Which Wins Right Now?
HappyHorse-1.0 leads Seedance 2.0 on T2V and I2V without audio — but trails on audio and has no stable API. Here's what that means for builders.

I spent many of my time refreshing the Artificial Analysis Video Arena leaderboard. Hey, it’s Dora here! A model I’d never heard of — HappyHorse-1.0 — had quietly appeared over the weekend and pushed Seedance 2.0 out of the top spot on two of the four main rankings. Nobody seemed to know who built it. Artificial Analysis itself called it a “pseudonymous” entry. And my timeline was half excitement, half confusion.
So I pulled the numbers, tracked the access paths, and tried to figure out the only question that actually matters for anyone building with these models right now: which one can you ship with today?
The answer isn’t as clean as the leaderboard makes it look.
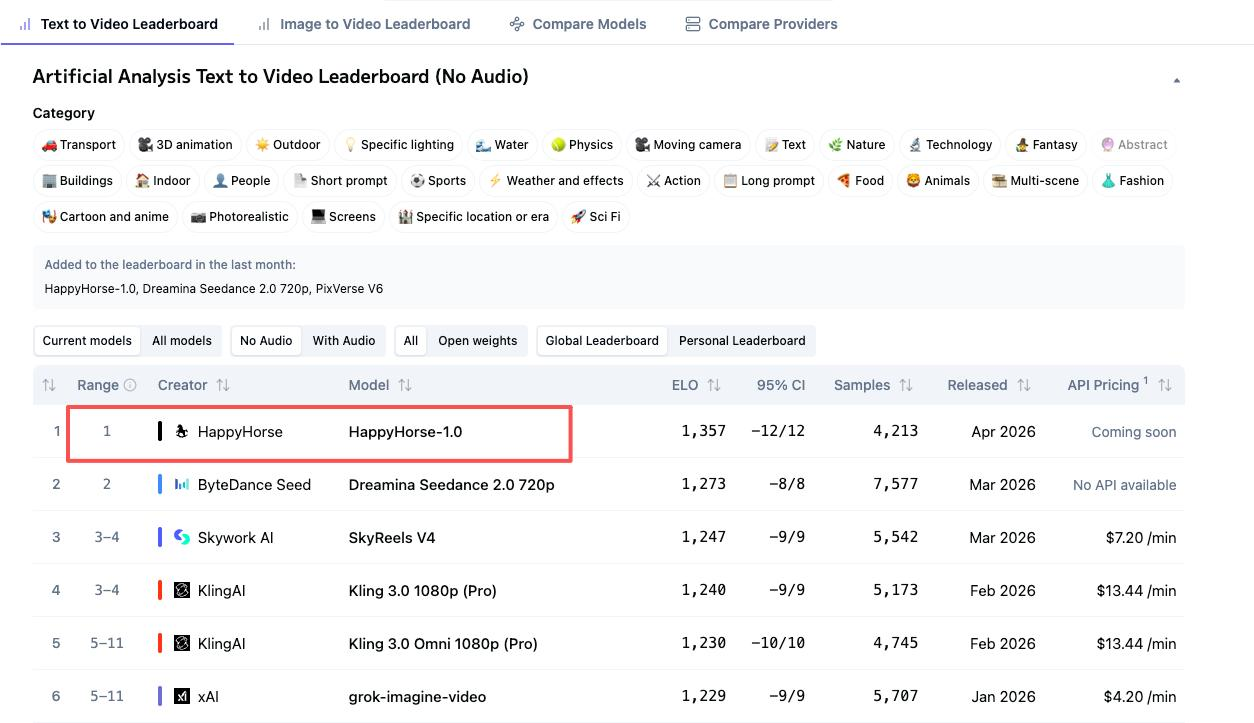
The Four Leaderboard Numbers That Matter
HappyHorse and Seedance 2.0 sit at the top of four separate Artificial Analysis rankings. But their positions flip depending on whether audio is part of the evaluation. That distinction matters more than most comparisons acknowledge.
T2V Without Audio: HappyHorse #1 (Elo 1333) vs Seedance 2.0 #2 (Elo 1273)
This is HappyHorse’s strongest showing. A 60-point Elo gap in a blind voting arena is meaningful — it roughly translates to users preferring HappyHorse’s output around 59% of the time in head-to-head matchups. The votes here are capturing visual motion quality, prompt adherence, and scene coherence without any audio to influence perception.
T2V With Audio: Seedance 2.0 #1 (Elo 1219) vs HappyHorse #2 (Elo 1205)
Once audio enters the frame, Seedance takes the lead by 14 points. ByteDance’s Dual-Branch Diffusion Transformer generates video and audio simultaneously in a single pass — one branch for video frames, one for audio waveforms, connected by cross-attention. That architectural choice pays off when synchronized sound effects and dialogue become part of the judgment.
I2V Without Audio: HappyHorse #1 (Elo 1392) vs Seedance 2.0 #2 (Elo 1355)
HappyHorse’s highest Elo across all four categories. A 37-point lead on image-to-video without audio suggests the model is particularly strong at following reference image composition — keeping subject identity, framing, and visual style consistent as it generates motion. For teams doing product animation or concept-to-motion work, this is the number that matters.
I2V With Audio: Seedance 2.0 #1 (Elo 1162) vs HappyHorse #2 (Elo 1161) — Near-Tied
One point. That’s within any reasonable margin of error. Neither model has a real advantage here. Treat this category as a draw until significantly more votes accumulate.
What Elo Actually Measures — and Its Limits for Production Decisions
These Elo scores come from blind user votes in side-by-side comparisons, using a Bradley-Terry model adapted from chess rankings. Users see two anonymously generated videos from the same prompt and pick the one they prefer. It’s the closest thing we have to a “vibe check” at scale.
But Elo doesn’t measure API reliability, generation speed, cost per clip, access stability, or whether you can actually call the model programmatically. A leaderboard rank is a quality signal, not a shipping decision.
Core Comparison Table
| Dimension | HappyHorse-1.0 | Seedance 2.0 |
|---|---|---|
| T2V Elo (no audio) | 1333 (#1) | 1273 (#2) |
| T2V Elo (with audio) | 1205 (#2) | 1219 (#1) |
| I2V Elo (no audio) | 1392 (#1) | 1355 (#2) |
| I2V Elo (with audio) | 1161 (#2) | 1162 (#1) |
| Audio generation | Present, trails Seedance | Stronger — native dual-branch sync |
| Known provider | No — pseudonymous | Yes — ByteDance |
| Architecture (claimed) | Single-stream 40-layer Transformer | Dual-Branch Diffusion Transformer |
| Open weights | Claimed “coming soon” | No |
| Stable API | No public API available | Consumer access via Dreamina; official API paused |
| Access today | Demo sites only | Dreamina, CapCut Pro, Chinese apps |
Where HappyHorse Pulls Ahead
Visual motion quality without audio: what blind votes are capturing
The Elo gaps on no-audio rankings — 60 points on T2V, 37 on I2V — aren’t trivial. Users in blind comparisons are consistently choosing HappyHorse for what people describe as more natural camera drift, smoother body movement, and stronger scene atmosphere. If your use case is silent product loops, social clips edited with separate music, or B-roll that gets scored in post, this is relevant.
Single-stream Transformer architecture (claimed) vs multi-stream pipelines
HappyHorse’s marketing materials describe a unified 40-layer self-attention Transformer that processes text, video, and audio tokens in a single sequence — no cross-attention between separate branches. If accurate, this is architecturally distinct from Seedance’s dual-branch approach. The first and last 4 layers reportedly use modality-specific projections while the middle 32 layers share parameters across all modalities. I can’t verify these claims independently yet. The GitHub and model hub are listed as “coming soon”.
Multilingual audio claims
HappyHorse claims native support for seven languages — English, Mandarin, Cantonese, Japanese, Korean, German, and French — with low word-error-rate lip sync. Seedance 2.0 supports 8+ languages for phoneme-level lip sync. On paper, they’re competitive. In practice, I haven’t been able to stress-test HappyHorse’s multilingual output enough to confirm parity.
Where Seedance 2.0 Maintains the Edge
Audio generation: still leads on both with-audio leaderboards
Seedance holds #1 on both T2V and I2V with audio. Its dual-branch architecture — one branch generating video frames, the other generating audio waveforms, connected via cross-attention for millisecond-level sync — was purpose-built for this. When your output needs dialogue, ambient sound, or frame-accurate foley, Seedance’s architectural decision to treat audio as a first-class citizen during generation (not a post-processing step) gives it a structural advantage.
Known provider: ByteDance, stable identity, established ecosystem
You know who made Seedance 2.0. ByteDance’s Seed research team, led by Wu Yonghui (former Google Fellow, 17 years at Google including Google Brain), has a documented lineage from Pixeldance through Seedance 1.0, 1.5 Pro, and now 2.0. HappyHorse? As of publication, nobody has publicly confirmed who built it. Artificial Analysis added it as a pseudonymous entry. Multiple third-party wrapper sites appeared within hours of its arena debut, but none claim to be the original developer.
For production decisions, provenance matters. You need to know who you’re depending on for model updates, compliance, and continuity.
Access path: Dreamina has public entry points
Seedance 2.0 is accessible today through ByteDance’s Dreamina platform internationally, with paid plans starting around $18/month. CapCut Pro integration rolled out in select markets in late March 2026. Chinese users can access it through Jimeng with plans from approximately 69 RMB/month (~$9.60 USD).
That said — the official Seedance 2.0 API remains paused since mid-March 2026 due to reported copyright disputes. Consumer access works. Programmatic API access at production scale requires verification before you commit to a pipeline around it. Third-party providers offer Seedance v1.5 via API; Seedance 2.0 API availability through official channels needs pre-production confirmation.
The Access Gap Is the Real Decision Factor
HappyHorse: no stable API, no public weights, demo-only as of publication
Despite claims of open-source release, HappyHorse’s GitHub and model hub are both listed as “coming soon.” Multiple demo and wrapper sites exist, but none offer documented API endpoints with SLAs, rate limits, or pricing you could build a product around. I couldn’t find a single third-party API provider currently serving HappyHorse-1.0 through a stable, documented endpoint.
If you’re evaluating for production, this is the single biggest factor. A model you can’t reliably call isn’t a model you can ship.
Seedance 2.0: accessible via Dreamina — details need verification
Consumer access through Dreamina is functional. The platform supports the full feature set including the @ reference system, multi-shot editing, and audio-visual generation. But if your workflow requires API-level integration, the landscape is less settled. The official BytePlus API for Seedance 2.0 has been paused since March. Third-party providers like fal.ai and PiAPI have offered Seedance 1.5; Seedance 2.0 programmatic access and its associated pricing structure should be confirmed directly before building a production dependency.
Why “leaderboard #1” and “production-ready” are different questions
I keep coming back to this. Elo tells you which model users prefer in a controlled comparison. It doesn’t tell you whether you can get 10,000 generations through it next Tuesday without a 503 error. HappyHorse might genuinely produce better silent video. But if you can’t call it reliably, that quality advantage lives in the arena, not in your pipeline.
Decision Framework
Audio quality is non-negotiable → Seedance 2.0. It leads on both with-audio leaderboards and its dual-branch architecture generates synchronized sound natively. If your clips need dialogue, ambient audio, or frame-accurate sound effects, Seedance is the stronger choice today.
Visual motion fidelity is your priority and you’re willing to wait → Monitor HappyHorse. The no-audio Elo leads are real. If open weights and API access materialize as promised, HappyHorse could become compelling for silent-first workflows. But “coming soon” isn’t an SLA.
You need a production API today → Seedance 2.0 is the safer bet. Not because it’s perfect — the official API pause is a real constraint — but because Dreamina provides a functional access path with documented pricing, and third-party providers are actively preparing Seedance 2.0 endpoints. HappyHorse has no equivalent infrastructure yet.
FAQ
Is HappyHorse-1.0 actually better than Seedance 2.0?
Depends on what you’re measuring. HappyHorse leads on visual quality in no-audio comparisons (Elo 1333 vs 1273 for T2V, 1392 vs 1355 for I2V). Seedance leads when audio is part of the evaluation. Neither dominates all four categories. “Better” only makes sense relative to your specific use case and whether audio matters.
Why does HappyHorse lead without audio but trail with audio?
Likely architecture. HappyHorse claims a single unified Transformer processing all modalities in one sequence. Seedance 2.0 uses a purpose-built dual-branch design where separate video and audio branches are connected by cross-attention. That specialized audio branch appears to give Seedance an edge when sound quality and sync are being judged alongside visuals.
Can I access HappyHorse-1.0 via API today?
Not through any stable, documented endpoint I could verify as of April 8, 2026. Multiple wrapper sites offer browser-based demo access, but none publish API documentation, rate limits, or production-grade SLAs. The official GitHub and model hub are both listed as “coming soon.”
How reliable is the Artificial Analysis leaderboard for production decisions?
It’s the most credible crowdsourced signal for perceived video quality — blind votes, Elo-based ranking, real human preferences. But it measures one thing: which output do users prefer side-by-side. It doesn’t account for generation speed, cost, reliability, API uptime, or access stability. Use it as a quality input, not as a complete procurement decision.
Will HappyHorse-1.0 get audio improvements in future versions?
No public roadmap exists. The model appeared on the arena less than a week ago under a pseudonym. If the “coming soon” open-source release happens, community contributions could improve audio quality. But there’s no timeline, no confirmed development team, and no announced v2 plans. Anything beyond what’s currently on the leaderboard is speculation.
There’s something interesting happening in the gap between what a leaderboard says and what a builder can actually use. HappyHorse’s numbers are genuinely impressive — but numbers without access are just numbers. I’ll keep watching for that GitHub repo to go live. Until then, the comparison isn’t really about which model is better. It’s about which model is available.
Previous posts:
Related Articles

Is HappyHorse-1.0 Open Source? What We Can Verify

What Is HappyHorse-1.0? The Mystery #1 AI Video Model

Where to Try HappyHorse-1.0: Access and Availability

Claude Code Hidden Features Found in the Leaked Source: Full List (2026)

Claude Mythos Coding Performance: What It Means for AI Dev Workflows
