Claude Mythos vs Claude Opus 4.6: What the Leak Reveals for Developers
Claude Mythos vs Opus 4.6: what the leak suggests about the capability gap, and whether developers should wait or build now.

While being mid-sprint on a Claude Code integration last week, the Mythos leak hit my feed. Three Slack messages in ten minutes, all variations of the same question: “Should we pause the build?” This is Dora the AI enthusiast, who has been tracking the story closely since — and I think the answer is more nuanced than the hype suggests.
Let me walk through what the leak actually says, what Opus 4.6 currently gives you, and how to make a real decision about timing.
Baseline: What Claude Opus 4.6 Currently Delivers for Developers
Before getting into Mythos speculation, let’s anchor on what’s actually available and documented today.
Coding and Agentic Task Performance
Claude Opus 4.6 achieves 65.4% on Terminal-Bench 2.0 and 72.7% on OSWorld, making it Anthropic’s strongest publicly available model for coding and computer use tasks. That Terminal-Bench number isn’t just a benchmark trophy — it represents real agentic capability: multi-step debugging, large-scale refactoring, and autonomous tool chaining across extended workflows.
The model is built for agents that operate across entire workflows rather than single prompts, making it especially effective for large codebases, complex refactors, and multi-step debugging that unfolds over time. If you’re building coding agents or agentic pipelines, this is the model that actually closes issues and ships code at production quality.
What matters operationally: Opus 4.6 breaks complex tasks into independent subtasks, runs tools and subagents in parallel, and identifies blockers with real precision. That’s the behavior that makes the difference in real CI/CD-adjacent automations, not just demo environments.
API Availability, Pricing, and Documentation
Here’s the part that matters for your decision-making timeline. Claude Opus 4.6 delivers state-of-the-art reasoning at $5 input / $25 output per million tokens — a 67% reduction from the Opus 4.1 era at $15/$75. The full Claude API documentation is public, versioned, and stable. You can access it via claude-opus-4-6 today.
A standout feature of the 4.6 generation is that the full 1 million token context window is included at standard pricing, eliminating the premium long-context surcharges that applied to earlier models. For teams dealing with large codebase ingestion or long research workflows, that’s a meaningful cost reduction compared to previous generations.
Cost optimization levers that are fully documented and available right now:
What the Claude Mythos Leak Says About the Gap
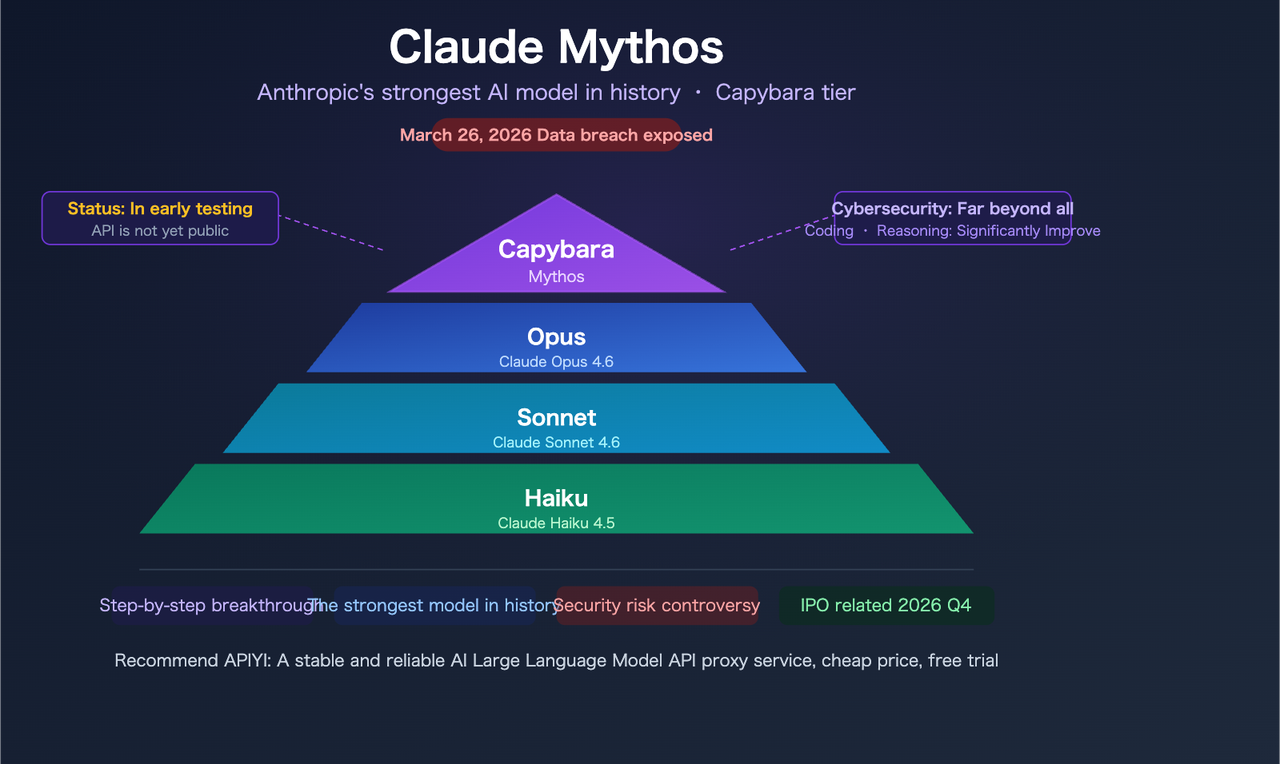
Earlier this month, Fortune reported that Anthropic had accidentally exposed nearly 3,000 internal files in a misconfigured, publicly searchable data store. Among them: a draft blog post about a model called Claude Mythos — internally also codenamed “Capybara.”
Important framing before diving in: everything below comes from an unverified draft document, not an official release. No public benchmarks, no API access, no pricing page. Anthropic has confirmed the model exists and is in limited testing. Everything else is still a draft.
Coding — “Dramatically Higher Scores” Unpacked
The leaked blog states: “Compared to our previous best model, Claude Opus 4.6, Capybara gets dramatically higher scores on tests of software coding, academic reasoning, and cybersecurity, among others.” That’s meaningful language from an internal document — “dramatically higher” isn’t hedged marketing copy, it’s a strong internal claim.
What we don’t have: specific numbers. No specific scores have been published beyond the qualitative language in the draft. Anyone citing exact Mythos benchmark figures right now is fabricating them. The honest read here is that Anthropic’s internal evaluation showed a gap large enough to warrant a new product tier — which is itself significant signal, but not the same as having verified data.

Academic Reasoning Improvements
The leaked draft groups academic reasoning alongside coding as a key differentiated capability. Anthropic describes Mythos as “a general purpose model with meaningful advances in reasoning, coding, and cybersecurity.” For developers building research assistants, document analysis pipelines, or legal/financial reasoning workflows, this is worth watching — Opus 4.6 already achieves 90.2% on BigLaw Bench, and if Mythos pushes that envelope further, the use case surface area expands considerably.
Cybersecurity Capabilities: New Territory
This is the capability dimension that’s getting the most coverage — and for good reason. The leaked draft describes the model as “currently far ahead of any other AI model in cyber capabilities” and warns it “presages an upcoming wave of models that can exploit vulnerabilities in ways that far outpace the efforts of defenders.”
Leaked internal documents warn the model could significantly heighten cybersecurity risks by rapidly finding and exploiting software vulnerabilities, potentially accelerating a cyber arms race. That’s why Anthropic’s initial rollout is restricted to organizations focused on cyber defense — an unusual move that signals genuine concern about misuse, not just standard safety theater.
The dual-use tension here is real. Anthropic’s current Opus 4.6 already demonstrated an ability to surface previously unknown vulnerabilities in production codebases, a capability the company acknowledged was dual-use — helping hackers and defenders alike. Mythos appears to push that capability significantly further, which explains the cautious rollout.
This Is a New Tier, Not a Version Bump — Why It Matters
Capybara Above Opus Structurally
The leaked draft states: “Capybara is a new name for a new tier of model: larger and more intelligent than our Opus models — which were, until now, our most powerful.” This is structurally different from Opus 4.5 → Opus 4.6. Anthropic currently has three tiers: Haiku, Sonnet, Opus. Capybara would add a fourth above all of them.
That matters how you architect your systems. If you’re building against the assumption that Opus is always the ceiling, a new tier above it means potential capability upgrades that aren’t just incremental fine-tune bumps — they represent a different class of task success rates.
Pricing: More Expensive by Design
No official pricing exists yet, but the structural signal is clear. The draft blog notes that the model is expensive to run and not yet ready for general release. Given that Capybara sits above Opus in a new tier, expect pricing above the current $5/$25 per million tokens for Opus 4.6. How much above is genuinely unknown — but plan for it to be meaningfully higher, not just a small increment.
This isn’t necessarily bad news. The 67% price reduction from Opus 4.1 to Opus 4.6 shows Anthropic has learned to bring flagship pricing down over generations. A Capybara launch at premium pricing today doesn’t mean it stays there in 12 months. The pattern suggests the real ROI question is whether the capability jump justifies the cost on your specific task distribution.

Should Your Team Wait for Claude Mythos?
This is the actual decision you’re here for. Here’s the honest framework.
If You’re Building Coding Agents or Agentic Workflows
Build now with Opus 4.6. The capability gap may be real, but waiting for an unreleased model with no public timeline is not a product strategy. Opus 4.6 is already the strongest publicly available model for agentic coding — Terminal-Bench 2.0 at 65.4% is a meaningful baseline that supports production use cases today.
The more important point: the architectural decisions you make now — prompt caching strategy, subagent orchestration, tool use patterns — will transfer directly to Mythos when it launches. Build on Opus 4.6, design for model-agnostic routing, and you’ll be in a much better position to migrate than teams who waited and started from scratch.
If Your Priority Is Cost Efficiency at Scale
Definitely build now. Mythos is expected to be more expensive than Opus 4.6, and there’s no indication of a budget tier equivalent at launch. If you’re running high-volume workloads where $5/$25 per million tokens already requires careful optimization with batch processing and prompt caching, Mythos is unlikely to be your default model — even after it’s publicly available. Use the time to optimize your Opus 4.6 workflows; those savings are real and available today.
The math worth doing: a team spending $2,500/month on standard Opus 4.6 can realistically get to ~$250/month with model mixing, batch processing, and caching. That 90% reduction compounds significantly over the months you’d spend waiting.
If Your Use Case Involves Vulnerability Research or Security
This is the one case where waiting makes sense — but you may not get to choose. The initial access group for Mythos is focused on security researchers and defenders — the goal is to prepare defenses before the model’s offensive capabilities become widely available. If your team works in offensive security research or defensive tooling, the right move is to apply for early access through Anthropic’s channels and continue building on Opus 4.6 in the meantime.
For general enterprise security tooling (code scanning, compliance, vulnerability triage), Opus 4.6 is already capable and fully available. Mythos likely extends the ceiling, not the floor.
What to Do While Mythos Is Not Publicly Available
Concretely, here’s how to avoid wasted effort while staying positioned to adopt Mythos efficiently:
Design for model-agnostic routing. Abstract your model calls behind a routing layer so swapping claude-opus-4-6 for a future claude-capybara-* model string is a configuration change, not an architectural rewrite. This is good practice regardless of Mythos — it also lets you route cost-sensitive tasks to Sonnet 4.6 today.
# Example: model-agnostic routing wrapper
import anthropic
MODEL_CONFIG = {
"flagship": "claude-opus-4-6", # swap here when Mythos launches
"balanced": "claude-sonnet-4-6",
"fast": "claude-haiku-4-5-20251001"
}
def call_claude(task_tier: str, messages: list, **kwargs):
client = anthropic.Anthropic()
return client.messages.create(
model=MODEL_CONFIG[task_tier],
max_tokens=1024,
messages=messages,
**kwargs
)Implement prompt caching now. According to Anthropic’s prompt caching documentation, cache writes incur a 25% surcharge on first hit, then read at 90% discount on subsequent hits. For agentic workflows with repeated system prompts or large context blocks, this is the single highest-leverage cost optimization available — and it’ll work the same way on Mythos.
Track the official release cadence. Anthropic has confirmed testing with early access customers. The staged rollout model Anthropic is using — security partners first, then broader access — suggests general API availability is likely weeks to months away, not days.
Evaluate your task distribution honestly. If 80% of your API calls are document summarization, Q&A, or structured extraction, Mythos’s coding and cybersecurity advances may not move your needle much. Opus 4.6 is already strong enough on those workloads. Save your Mythos evaluation for the tasks where you’re currently hitting Opus’s ceiling.
FAQ
Q: Can I use Claude Mythos today?
No. As of late March 2026, Claude Mythos (Capybara) is available only to a small group of early access customers, specifically those working on cyber defense applications. There is no public API, no documentation, and no announced launch date. Claude Opus 4.6, accessible via claude-opus-4-6 on the Anthropic API, remains the strongest publicly available model.
Q: Is Opus 4.6 still the best public Claude model?
Yes. Claude Opus 4.6 and Sonnet 4.6 remain the most capable publicly available Claude models — and they’re already remarkably powerful for coding, reasoning, and complex tasks. Opus 4.6 tops the public leaderboards for agentic coding and is fully documented with stable API access across Anthropic’s platform, AWS Bedrock, Google Vertex AI, and Microsoft Foundry.
Q: How much more expensive will Claude Mythos be?
Unknown. The leaked draft confirms the model is “expensive to run,” and the new Capybara tier sitting above Opus structurally implies a price premium above the current $5/$25 per million tokens for Opus 4.6. No official pricing has been published. Historical precedent shows Anthropic does reduce flagship pricing over model generations, so early launch pricing may not reflect long-term cost.
Previous Posts:
Related Articles

Claude Code architecture Deep Dive: What the Leaked Source Reveals

claw-code vs Claude Code: What's Actually Different?

Qwen3.5-Omni API Pricing, Limits, and Deployment Options (2026)

Qwen3.5-Omni vs GPT-4o vs Gemini 2.5 Pro: Omni Model Comparison

Claude Code Leaked Source: BUDDY, KAIROS & Every Hidden Feature Inside
