Claude Code architecture Deep Dive: What the Leaked Source Reveals
The Claude Code leaked source exposed 512K lines of production TypeScript. Here's the full architecture breakdown — tool system, query engine, multi-agent patterns, and context compression.

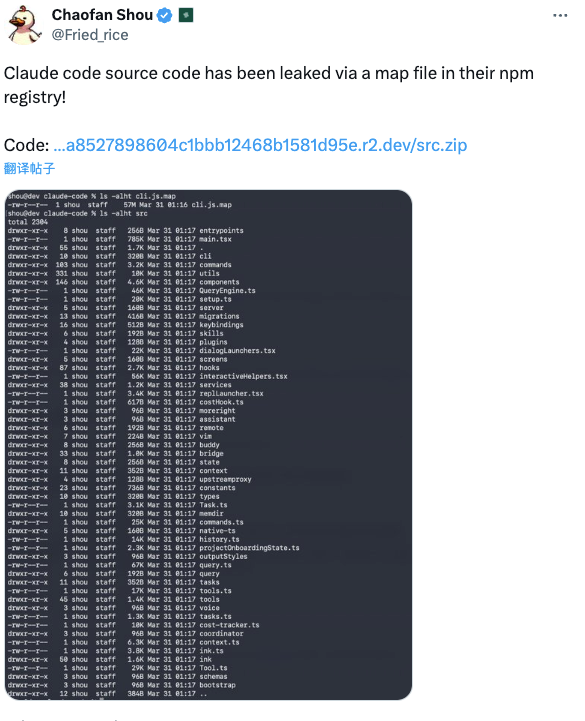
Hello, everyone, I’m Dora. I wasn’t looking for a rabbit hole in March, 2026. A message hit my feed: “Claude Code source code has been leaked via a map file in their npm registry.”
I closed the tab I was in and didn’t look back.
What followed was one of the more genuinely interesting afternoons I’ve spent studying how a production AI tool is actually built. Not because of the leak drama — that gets old fast — but because the code is a rare thing: a real, shipped, commercially dominant agentic CLI examined at 512,000 lines of detail.
Here’s what I noticed.
Why the Leaked Source Is a Rare Architecture Study Opportunity
After the Claude Code leaked, the source surfaced — exposed through a misconfigured .map file in Anthropic’s own npm package — developers quickly realized this wasn’t a wrapper around a chat API. According to cybersecuritynews.com’s breakdown of the incident, the exposure included approximately 1,900 files and over 512,000 lines of strict TypeScript, with the primary entry point alone weighing in at 785KB.
The stack itself is already interesting: Bun as the runtime (not Node.js), React with Ink for terminal UI rendering, and Zod v4 for schema validation throughout. Using React component patterns in a CLI means state management, re-renders, and composable UI components inside your terminal. It’s a deliberate, bold choice.
What makes this worth studying beyond memes: the Claude Code architecture patterns here apply to any team building serious agentic systems.

The Tool System — 40+ Self-Contained Permission-Gated Modules
The first thing that stood out to me was how cleanly the tool system is isolated. Every tool defines its own input schema, permission level, and execution logic — independently. There’s no shared mutable state sneaking between tools.
BashTool and FileReadTool sit in the same registry but have fundamentally different risk profiles. Bash execution can alter system state; file reading is read-only. The architecture treats them accordingly, gating each behind its own permission level rather than applying a blanket policy. That separation matters enormously in production agentic systems, where a permission model that leaks across tools is a security and reliability problem waiting to happen.
AgentTool is the clever one. It lets the system spawn sub-agents as just another tool call — no special orchestration layer required, no separate process model. Sub-agents are first-class citizens of the same tool registry. That design decision keeps the architecture flat and predictable.
The base tool definition alone spans around 29,000 lines of TypeScript. That’s not bloat — that’s what rigorous schema validation, permission enforcement, and error handling actually look like at this scale. Anthropic’s official Claude Code documentation confirms this tool-centric philosophy: tools are what make the system agentic at all.
The 46K-Line Query Engine — The Real Brain of Claude Code
QueryEngine.ts is 46,000 lines. Let that sit for a moment.
This is the module that handles all LLM API calls, streaming, caching, and orchestration. In a single file. That might sound like a red flag — and depending on your codebase conventions, you’d be right to question it — but the reasoning is coherent: everything that touches the model API is in one place, which means retry logic, rate limit handling, context budget management, and streaming errors are all reasoned about together.
The self-healing query loop is the part that caught me off guard. When the context budget approaches its limit, the engine doesn’t crash or ask for help. It triggers compression automatically, carving out a buffer before the ceiling and generating a structured summary of what’s been discussed. That’s not a hack — it’s designed behavior. For anyone building long-running agent sessions, this pattern is directly worth studying.
Multi-Agent Orchestration — Coordinator, Workers, and the Mailbox Pattern
The multi-agent system uses what the leaked source calls a mailbox pattern for dangerous operations. Here’s what that means in practice: a worker agent executing a task can’t independently approve a high-risk operation. Instead, it sends a request to the coordinator’s mailbox and waits. The coordinator evaluates and either approves or rejects.
The atomic claim mechanism prevents two workers from handling the same approval simultaneously — a subtle but critical detail in any system with parallel execution. Shared memory space across all agents means the team maintains coherent context without redundant re-fetching.
This is a meaningful departure from naive multi-agent designs where every agent operates with full autonomy. The coordinator/worker split with approval gates is how you get parallelism without chaos. Teams building orchestration layers for their own agentic systems would do well to read through Anthropic’s agentic patterns documentation before designing their own.
Three-Layer Context Compression — Engineering for Long Sessions
This is probably the most directly useful piece of engineering in the entire codebase for anyone building production AI applications.
Claude Code uses three distinct compression strategies, each triggered at a different point:
MicroCompact edits cached content locally, with zero API calls. Old tool outputs get trimmed directly. Fast, cheap, transparent.
AutoCompact fires when the conversation approaches the context window ceiling. It reserves a 13,000-token buffer, then generates up to a 20,000-token structured summary of the session. There’s a built-in circuit breaker — after three consecutive compression failures, it stops retrying. No infinite loops.
Full Compact compresses the entire conversation, then re-injects recently accessed files (capped at 5,000 tokens per file), active plans, and relevant skill schemas. Post-compression, the working budget resets to 50,000 tokens.
What’s notable is what this architecture implies for tools that skip compression entirely. Agentic tools that don’t manage context budget will simply fail at scale — silently degrading or hitting hard errors. The three-layer approach is a rare example of designing for session longevity from the start, not bolting it on later.
Feature Flags as Architecture — 108 Modules That Don’t Exist in Production
One of the less-discussed findings from the leaked source: 108 feature-gated modules, stripped from external builds via Bun’s compile-time dead code elimination.
KAIROS, VOICE_MODE, DAEMON — these don’t exist in the version you install. The code is there in the source, but Bun eliminates it at compile time based on feature flag configuration. The production bundle ships clean. This is how you iterate on new capabilities without touching what’s already in users’ hands.
The irony is well-documented: Undercover Mode, a subsystem specifically designed to prevent internal codenames from appearing in git commits or outputs, was present in the leaked source. The system built to prevent leaks couldn’t prevent the leak itself. Not a catastrophic security failure, but an instructive one about where risk actually accumulates in software delivery pipelines.
Telemetry Built Into the Core Loop
Two telemetry signals in the leaked source that I keep thinking about:
A frustration metric tracks swearing frequency as a UX signal. If users are cursing at the tool, something is breaking down — a leading indicator, not lagging.
A “continue” counter tracks how often users type the word “continue” mid-session. For an agentic CLI, this is a proxy for stalls — moments where the agent lost momentum and the human had to nudge it forward.
Neither is a vanity metric. Both surface specific failure modes that standard analytics would miss. If you’re building any AI product with extended interaction sessions, instrumenting agent behavior this way is worth the engineering time.
What This Tells Builders About Stack Decisions
The honest takeaway from studying this claude code architecture: building a production agentic CLI from scratch is a substantial engineering commitment. The tool system, query engine, multi-agent orchestration, context compression, and telemetry together represent years of iteration, not months.
That’s not an argument against building. It’s an argument for being clear about what you’re taking on. Patterns like the mailbox approval system and three-layer compression are exportable — you don’t need 512,000 lines to implement the core ideas.
Where the build-vs-buy calculus shifts is in model access and aggregation. The architecture assumes direct access to a single model provider. Teams working across multiple model providers, or building products that need to stay model-agnostic, face a different set of tradeoffs entirely.
The patterns here are worth borrowing. The complexity is worth understanding before committing to replicating it.

FAQ
How does Claude Code’s tool system differ from standard function calling?
Standard function calling treats tools as a flat list. Claude Code adds per-tool permission gates, isolated execution contexts, and schema validation at every boundary — preventing cross-tool state leakage and enforcing least-privilege access, which matters when BashTool can modify system state.
What is the mailbox pattern and when should builders use it?
It routes dangerous operations from worker agents to a coordinator for approval, rather than executing autonomously. Use it any time you have parallel agent execution and need a human-in-the-loop or hierarchical approval mechanism for high-risk actions. Throughput cost, safety gain.
How does Claude Code handle context window limits at scale?
Three-layer compression: MicroCompact (local edits, no API cost), AutoCompact (triggered near limits, generates a structured summary with reserved token buffer), and Full Compact (full conversation compression with selective file re-injection). Designed for long sessions without manual intervention.
What are compile-time feature flags and why do production AI tools use them?
They allow code for unreleased features to exist in source without appearing in production builds. Bun eliminates flagged-off code at compile time, so external users never encounter features that aren’t ready — separating shipping from readiness.
Is it legal to study and reference the leaked source for architecture inspiration?
Worth treating carefully. The leaked source is Anthropic’s intellectual property. Studying architectural patterns for educational purposes sits in different territory than copying code directly. Anthropic’s official documentation remains the appropriate reference for anything you’d build on top of their systems. When in doubt, consult your own legal counsel.

The thing I keep coming back to is how much of this architecture is about managing failure gracefully. The circuit breakers on compression, the mailbox pattern for dangerous operations, the permission isolation between tools — these aren’t optimistic designs. They’re built by people who have watched things go wrong and decided to engineer around them.
That’s a different kind of maturity than feature velocity.
OK, today’s sharing is over. See you next time.
Previous Posts:
- Compare GPT-5, DeepSeek, and other models in real-world performance and cost
- Understand DeepSeek V4 context caching and how it improves long-session efficiency
- Learn about DeepSeek V4 rate limits and scaling constraints for production systems
- Explore DeepSeek V4 pricing and cost per million tokens for large-scale applications
- See how much GPU VRAM DeepSeek V4 requires for real deployments
Related Articles

Claude Mythos vs Claude Opus 4.6: What the Leak Reveals for Developers

claw-code vs Claude Code: What's Actually Different?

Qwen3.5-Omni API Pricing, Limits, and Deployment Options (2026)

Qwen3.5-Omni vs GPT-4o vs Gemini 2.5 Pro: Omni Model Comparison

Claude Code Leaked Source: BUDDY, KAIROS & Every Hidden Feature Inside
