WAN 2.7 첫 번째 & 마지막 프레임 제어: 빌더 가이드
WAN 2.7의 첫 번째 및 마지막 프레임 제어를 사용하여 예측 가능한 동영상 생성을 구현하는 방법 — 입력 준비, API 파라미터, 프로덕션 워크플로우 팁.

안녕하세요, 여러분. Dora가 찾아왔습니다. 저는 수많은 팀들이 첫 번째/마지막 프레임 제어를 “이미지 두 장만 업로드하면 돼요”라고 설명하는 걸 계속 봐왔습니다. 이건 비동기 작업 큐를 “그냥 기다리면 됩니다”라고 설명하는 것과 같습니다. 메커니즘 자체는 어렵지 않습니다 — 하지만 입력 설계 결정이야말로 대부분의 프로덕션 워크플로우가 조용히 무너지는 지점입니다.
이 가이드는 한 번 작동한 데모가 아닌, 반복 가능한 결과물이 필요한 빌더를 위한 것입니다.
첫 번째/마지막 프레임 제어가 실제로 하는 일
표준 I2V 대비 해결하는 문제
표준 이미지-투-비디오(I2V)는 시작 프레임을 고정하고 이후 모델이 즉흥적으로 생성합니다. 그 결과가 커뮤니티에서 흔히 “드리프트”라고 부르는 현상입니다 — 피사체, 카메라 위치, 또는 조명이 점점 원하는 목표 상태에서 벗어납니다. 필수 엔드포인트가 있는 제품 데모나 내러티브 시퀀스의 경우, 이를 후반 작업에서 수정하는 데 상당한 비용이 듭니다.
WAN의 FLF2V 방식은 추가적인 제어 조정 메커니즘을 사용합니다: 첫 번째와 마지막 프레임이 제어 조건으로 처리되며, 두 이미지의 시맨틱 특성이 생성 과정에 주입됩니다. 이를 통해 모델이 두 이미지 사이를 동적으로 변환하는 동안 스타일, 콘텐츠, 구조의 일관성을 유지합니다.
생성 중 두 프레임이 사용되는 방식
모델은 단순히 픽셀 값을 보간하지 않습니다. CLIP 시맨틱 특성과 크로스 어텐션 메커니즘을 사용하여 비디오를 안정적으로 유지합니다 — 이 설계는 단일 앵커 방식에 비해 비디오 지터를 줄이는 것으로 나타났습니다. 첫 번째 프레임이 초기 상태를 정의하고, 마지막 프레임이 목적지를 제한합니다. 그 사이의 모션 경로는 추론되는 것이지 지정되는 것이 아니며, 이것이 강점이자 주요 실패 원인입니다.
모델이 두 프레임 사이 경로에 대해 추론하는 것
텍스트 프롬프트는 전환이 어떻게 일어나는지를 안내합니다 — 단순히 전환이 일어난다는 사실만이 아닙니다. 프롬프트에 “제품이 천천히 회전하며 앞면을 드러냅니다”라고 쓰여 있으면, 그 모션 설명이 추론된 경로를 형성합니다. 프롬프트 없이도 모델은 여전히 그럴듯한 전환을 시도하지만, 방향 변화, 카메라 움직임, 또는 페이싱에 대한 제어력이 훨씬 줄어듭니다.
입력 준비
이미지 사양 요건
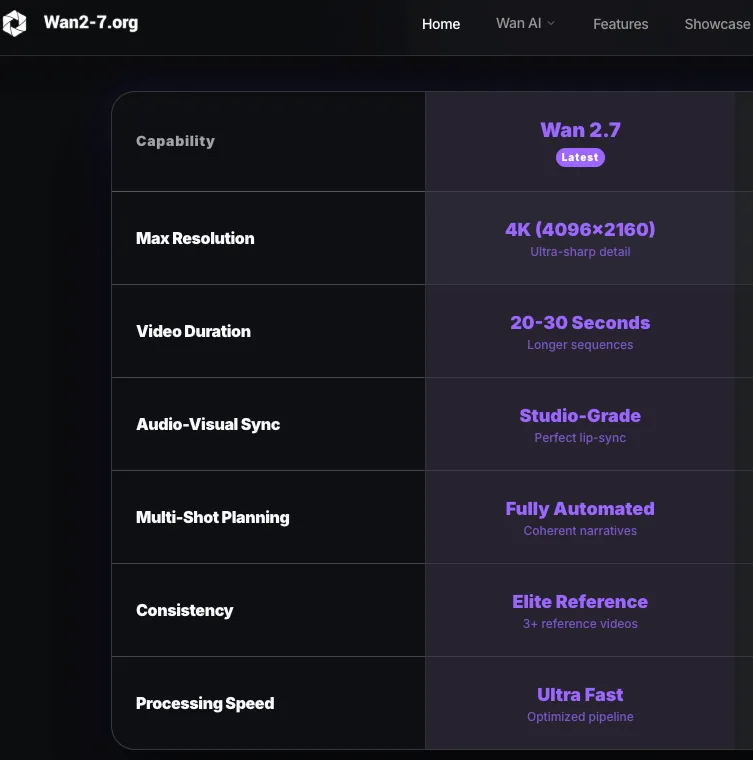
모델은 첫 번째 프레임의 종횡비를 목표 출력에 최대한 가깝게 사용합니다. 3:4 입력(750×1000)의 경우, 720P 출력 설정은 816×1104 정도를 생성합니다 — 정확히 3:4가 아닙니다. 정확한 비율이 필요하다면 후반 작업에서 크롭하거나 레터박스 처리를 계획하세요. WAN 시리즈 전반적으로, 720p(1280×720 또는 세로 방향 동등값)가 고품질 출력을 위한 권장 해상도입니다; 더 낮은 해상도로 실행하는 것은 테스트 반복에는 유효한 전략이지만 최종 결과물에는 적합하지 않습니다.
형식: PNG 또는 고품질 JPEG. 압축된 썸네일을 첫 번째/마지막 프레임으로 사용하지 마세요 — 압축 아티팩트는 모델이 의도적인 시각 정보로 해석해야 하는 노이즈를 도입합니다.
효과적인 프레임 페어링 전략
가장 강력한 쌍은 세 가지를 공유합니다: 일관된 광원 방향, 일치하는 피사계심도 특성, 그리고 두 위치 모두에서 공간적으로 타당한 피사체. 부드러운 스튜디오 조명에서 촬영한 제품 샷과 약간 다른 각도에서 같은 제품을 보여주는 마지막 프레임은 잘 작동합니다. 조명 설정이 비슷하다면 팩샷에서 라이프스타일 히어로 샷으로의 전환도 효과적입니다.
내러티브 시퀀스의 경우, 쌍을 동사를 정의하는 것으로 생각하세요: 열림 → 닫힘, 이전 → 이후, 조립 중 → 완성. 시맨틱 관계가 명확할수록 추론된 경로가 더 일관됩니다.
나쁜 프레임 쌍을 만드는 요소
세 가지 일반적인 원인:
일관되지 않은 조명 방향. 첫 번째 프레임의 키 라이트가 왼쪽 45°에 있고 마지막 프레임이 오버헤드 조명으로 촬영된 경우, 모델은 두 개의 다른 그림자 환경 사이를 전환하려 시도합니다. 결과는 보통 렌더링 오류처럼 보이는 클립 중간의 광원 점프입니다.
공간적 불일치. 와이드 설정 샷과 타이트 클로즈업을 페어링하면 모델이 카메라 무브먼트를 창안해야 합니다. 때로는 의도적이지만 보통은 그렇지 않습니다. 줌이나 풀을 명시적으로 프롬프트하지 않는 한 초점 거리를 대략 일관되게 유지하세요.
충돌하는 심도 단서. 첫 번째 프레임에는 보케, 마지막 프레임에는 모든 것이 초점 — 모델은 이를 피사계심도 변화로 해석하고 애니메이션화하려 시도합니다. 항상 잘못된 것은 아니지만, 의도한 바인 경우는 드뭅니다.
API 구현
다음은 WAN 시리즈의 문서화된 FLF2V 패턴을 반영합니다. 프로덕션 사용 전에 Alibaba Cloud Model Studio 문서에서 현재 파라미터 이름과 엔드포인트 경로를 확인하세요. WAN 2.7 API 세부 사항은 출시 시 확인해야 합니다.
페이로드 구조
핵심 패턴은 두 개의 이미지 입력을 포함합니다 — 공개 URL 또는 로컬 파일 경로를 통해 — first_frame_url과 last_frame_url로 전달되며, 텍스트 프롬프트 및 해상도 설정과 함께 사용됩니다.
Python 요청 패턴 (의사 코드)
# 출시 시 모델 이름과 엔드포인트 확인 — 버전마다 이름이 변경됩니다
import os
from dashscope import VideoSynthesis
response = VideoSynthesis.async_call(
model="wan2.x-flf2v-<출시-시-확인>", # 정확한 모델 문자열 확인
first_frame_url="https://your-cdn.com/start.png",
last_frame_url="https://your-cdn.com/end.png",
prompt="고정 카메라. 첫 번째 이미지에서 시작하여 마지막 이미지에서 끝납니다. [모션 설명]",
negative_prompt="flicker, warping, blur",
resolution="720P", # 허용되는 값 확인
# seed 파라미터: 좋은 결과를 얻으면 이 값을 고정하세요
)
task_id = response.output.task_id장시간 작업을 위한 비동기 처리
이미지-투-비디오 생성 작업은 일반적으로 1~5분 걸립니다. API는 두 단계 비동기 패턴을 사용합니다: 작업 제출, 작업 ID 획득, 그런 다음 결과 폴링. 처음부터 파이프라인에 폴링을 구축하세요. 테스트 호출에서도 동기식 동작을 가정하지 마세요 — 타임아웃은 naive한 구현에서 결과를 조용히 삭제합니다.
프로덕션 워크플로우: 초안-최종본 방법
1단계 — 참조 쌍 구축 및 테스트 실행
단일 쌍으로 시작하세요. 하나의 출력을 엔드-투-엔드로 확인하기 전까지는 배치 처리하지 마세요. 대상 콘텐츠를 사용하세요 — 플레이스홀더 스톡 이미지가 아닌 — 공간적 및 조명 특성이 실제 에셋 라이브러리를 대표해야 하기 때문입니다.
2단계 — 배치 전 모션 경로 검증
전체 클립을 0.5배 속도로 한 번 시청하세요. 다음을 확인하세요: 클립 중간 지터, 클립의 50~70% 지점 주변에서의 피사체 정체성 드리프트(대부분의 아티팩트가 집중되는 곳), 그리고 조명 불연속. 이 중 하나라도 발견되면, 프롬프트에 손대기 전에 입력 쌍을 수정하세요.
3단계 — 일관성을 위한 최적 시드 고정
깨끗한 출력을 얻었다면, 시드 값을 기록하세요. FLF2V 모델은 중간 동작과 변환 로직을 안내하는 선택적 프롬프트를 허용합니다. 고정된 시드와 고정된 프롬프트는 유사한 입력 쌍에 적용할 수 있는 재현 가능한 생성 단위를 제공합니다. 이것이 배치 프로덕션을 확률적이 아닌 예측 가능하게 만드는 요소입니다.
4단계 — 배치 생성으로 확장
배치를 다음과 같이 구성하세요: 품질 기준점 역할을 하는 하나의 정규 “테스트 쌍”, 그런 다음 동일한 통제된 촬영 셋업에서 생성된 변형 쌍. WAN FLF2V의 Hugging Face 모델 페이지는 API 호출과 함께 로컬 추론을 실행하는 팀을 위한 오픈 웨이트 버전을 문서화합니다.
이 기능이 적합한 경우 (그리고 적합하지 않은 경우)
최적 용도: 엔드포인트가 중요한 제품 데모 시퀀스(팩샷 → 기능 공개), 정의된 이전/이후가 있는 내러티브 연속 샷, 시리즈의 여러 클립에서 공간적 안정성이 필요한 제어된 카메라 경로.
적합하지 않은 경우: 급격한 방향 변화가 있는 고도로 역동적인 모션(모델이 이를 부드럽게 처리하여 종종 드라마를 잃음), 첫 번째와 마지막 프레임이 명확한 시맨틱 관계를 공유하지 않는 모호한 공간적 전환, 또는 프레임 정확한 타이밍이 필요한 시나리오 — 페이싱은 당신이 아닌 모델이 제어합니다.
일반적인 실패 패턴 및 수정
클립 중간 모션 아티팩트. 보통 입력 쌍의 공간적 불일치로 인해 발생합니다. 모델이 초기에 보간 경로에 “커밋”하고, 불일치가 중간 지점 주변에 나타납니다. 수정: 프롬프트를 변경하기 전에 프레임 간의 관계를 좁히세요.
프레임 스타일 불일치. 첫 번째 프레임이 스타일화된 렌더이고 마지막이 사진이라면, 모델은 시각적 스타일을 혼합하려 시도합니다. 이는 깨끗한 출력을 거의 생성하지 않습니다. 이미지 처리를 일치시키세요 — 둘 다 렌더, 둘 다 사진, 둘 다 일러스트레이션.
모델이 마지막 프레임을 무시함. 프롬프트가 마지막 프레임에서 논리적으로 끝날 수 없는 모션을 설명할 때 발생합니다. 모델은 충돌이 있을 때 프레임 준수보다 프롬프트 일관성을 우선시합니다. 프롬프트를 첫 번째 프레임에서 출발하는 것만이 아니라 마지막 프레임에 도착하도록 작성하세요.
FAQ
- 첫 번째/마지막 프레임을 텍스트-투-비디오와 함께 사용할 수 있나요, 아니면 I2V만 가능한가요? FLF2V 모드는 I2V의 확장입니다. 두 프레임 입력이 모두 필요합니다. 표준 T2V는 설계상 마지막 프레임 제약을 허용하지 않습니다.
- 프레임 입력에 가장 잘 맞는 이미지 형식은 무엇인가요? 깨끗한 가장자리나 투명도 처리가 필요한 경우 PNG. 고품질 JPEG(>90 품질)은 사진에 적합합니다. 플랫폼에서 지원을 확인하지 않은 경우 WebP는 피하세요.
- 표준 I2V보다 비용이 더 드나요? 가격은 해상도에 따라 다릅니다 — 720p는 생성당 480p보다 약 두 배 비용이 듭니다. FLF2V 자체는 문서화된 가격에서 별도의 추가 비용을 부과하지 않지만, 특정 플랫폼에서 확인하세요.
- 급격한 방향 변화가 필요한 모션은 어떻게 처리하나요? 시퀀스를 중간 프레임을 엔드포인트로 하는 여러 클립으로 분리하세요. 불연속적인 모션을 단일 생성으로 처리하려 하기보다 후반 작업에서 연결하세요.
- 9-그리드 입력 모드와 결합할 수 있나요? 이들은 별도의 입력 모드입니다. WAN 2.7은 첫 번째/마지막 프레임 제어와 9-그리드 이미지-투-비디오를 별개의 기능으로 지원합니다. 현재 단일 호출에서 결합되지 않습니다 — 이것이 변경되면 출시 시 확인하세요.
결론
첫 번째/마지막 프레임 제어의 흥미로운 설계 공간은 API 호출이 아닙니다 — 바로 입력 쌍입니다. 그것이 실제 프로덕션 레버리지가 있는 곳이며, 대부분의 팀이 투자를 소홀히 하는 곳입니다. 명확한 시맨틱 관계를 가진 잘 설계된 프레임 쌍은 일치하지 않는 입력과 페어링된 완벽한 프롬프트를 지속적으로 능가합니다.
배치 파이프라인을 구축하는 팀을 위해: 입력 쌍 라이브러리를 사후 고려사항이 아닌 일급 에셋으로 취급하세요. 고정된 시드와 검증된 쌍 형식을 갖추면, 생성 측면이 일상적인 작업이 됩니다. ComfyUI 커뮤니티는 API 호출과 함께 로컬 추론을 실행하는 경우 참고할 WAN FLF2V 워크플로우 구성을 상세히 문서화했습니다 — 프레임 컨디셔닝이 실제로 어떻게 작동하는지에 대한 노드 수준의 인사이트를 위해 읽어볼 가치가 있습니다.
여기서 계속 떠오르는 조용한 생각이 있습니다: 제약 자체가 기능입니다. 모델에게 목적지를 제공하면 실제로 원하는 것에 대해 정확해야 합니다. 이는 한계가 아닙니다 — 개방형 생성보다 더 나은 결과물을 만들어내는 경향이 있는 규율입니다.
AI 비디오 워크플로우를 계속 탐구하세요:





