Z-Image LoRA: 그 의미와 필요한 시점 (초보자 친화적)

안녕하세요, 친구들. 도라입니다. 지난주에 뭔가를 학습시킬 계획이 없었습니다. 단지 스크린샷 모서리에 앉을 수 있는 일관된 작은 도우미, 삽화 캐릭터가 필요했을 뿐입니다. 프롬프트는 계속 거의 도달하다가 흘러내렸습니다. 눈썹이 변했습니다. 색상이 변했습니다. 화요일(2026년 1월 13일) 몇 번의 실패 후, Z-Image LoRA를 시도했습니다. 복잡한 과정이 될 것으로 예상했습니다. 하지만 그것은 짧은 복도 같은 것이었습니다.
이것은 승리의 순간이 아닙니다. 즉시 되지는 않았습니다. 하지만 설정 과정에서 충분한 마찰을 제거해서 설정에 대해 생각하는 것을 멈추고 이미지에 대해 생각하기 시작했습니다. 여기 작동한 것, 작동하지 않은 것, 그리고 LoRA가 전혀 필요하지 않을 때를 설명합니다.
1분 만에 이해하는 Z-Image LoRA
LoRA(Low-Rank Adaptation)는 기본 이미지 모델 위에 학습시키는 작은 추가 기능으로, 전체 모델을 재학습시키지 않고 특정 스타일이나 주제로 모델을 유도합니다.
 Z-Image LoRA (초보자 친화적)가 잘하는 것:
Z-Image LoRA (초보자 친화적)가 잘하는 것:
- 복잡한 설정을 숨깁니다. 여전히 몇 가지 기본 사항(이미지, 캡션, 대상)을 선택하지만, 기본값은 합리적입니다.
- 충분히 빠르게 반복할 수 있습니다. 첫 번째 시도(10개 이미지)는 중급 GPU에서 약 12~18분이 걸렸습니다.
- 레이어처럼 로드됩니다. 생성 도구에서 켜고 평소처럼 프롬프트를 작성하면 되고, 선택적으로 트리거 단어를 사용할 수 있습니다.
결과: 일관성, 로고, 캐릭터, 붓질로 그린 수채화 스타일이 필요할 때 모델을 살짝 밀어주는 작은 파일을 얻습니다. 잠그지 않습니다. 켜지 않으면 기본 모델이 평소처럼 작동합니다.
LoRA가 필요하지 않은 경우
사랑을 담아 말합니다: 우리 많은 사람들이 너무 빨리 학습에 손을 댑니다. LoRA를 신경 쓰지 않는 경우가 몇 가지 있습니다:
- 기본 모델이 이미 충분합니다. 짧은 프롬프트와 참조 이미지가 사용할 수 있는 8/10 결과를 얻는다면, 완료입니다. IP-Adapter나 이미지 프롬프트로 충분할 수 있습니다.
- 일관성이 아니라 다양성이 필요합니다. 각 출력이 변해야 한다면, LoRA는 과도할 수 있습니다.
- 일회성 시각 자료. 단일 배너의 경우, 학습 설정보다는 5분 더 프롬프트를 작성하겠습니다.
- 제약이 정체성이 아니라 구성에 있습니다. ControlNet이나 포즈 안내와 같은 도구는 모델에 새로운 개념을 가르치지 않고 레이아웃을 형성합니다.
제가 사용하는 빠른 테스트: 간단한 시드 스윕과 2~3개의 프롬프트 수정만으로 5개 이미지에서 제가 관심 있는 요소(같은 캐릭터, 같은 로고 비율)를 유지할 수 없다면, 그때 LoRA를 고려합니다. 그 외에는 단순하게 유지합니다.
LoRA가 도움이 되는 경우
이번주(2026년 1월) 두 가지 상황에서 차이를 가장 많이 느꼈습니다:
- 문서 전체에서 재사용하고 싶은 작은 마스코트. 프롬프트는 눈과 셔츠 색상을 계속 흔들었습니다. 짧은 LoRA 후, 안정화되어 포즈와 배경에 집중할 수 있었습니다.
- 다이어그램용 부드러운 연필 질감. “연필 스케치”를 프롬프트할 수 있지만, 음영이 매번 변했습니다. 15개 이미지 스타일 LoRA는 내용을 고정하지 않고 안정적인 라인 품질을 제공했습니다.
LoRA가 도움이 될 가능성이 높은 신호:
- 많은 장면에서 같은 주제가 필요합니다.
- 특정 미술 질감이 중요하고(크로스해치, 리소그래프 점, 두꺼운 과슈 가장자리) 계속 변합니다.
- 프롬프트 체조를 줄이고 싶습니다. 학습 후, 제 프롬프트는 80
100 토큰에서 3040으로 떨어졌습니다. 정신적 노력이 시간보다 더 많이 떨어졌습니다.
제가 놀란 것은 영향이 얼마나 조용했는지였습니다. 극적인 전후가 없습니다. 단지 재시도가 적고, “거의 다 왔어”가 적었습니다.
데이터 요구 사항
 간단하게 유지했고 예상보다 훨씬 잘 작동했습니다. 지난주 두 번의 짧은 실행에 대한 몇 가지 참고 사항:
간단하게 유지했고 예상보다 훨씬 잘 작동했습니다. 지난주 두 번의 짧은 실행에 대한 몇 가지 참고 사항:
수량
- 캐릭터/주제: 8~20개 이미지는 다양하면(각도, 조명, 가벼운 의상 변화) 충분할 수 있습니다. 저는 12개를 사용했습니다.
- 스타일/질감: 같은 모습을 공유하지만 다른 내용의 10~30개 이미지. 저는 15개를 사용했습니다.
품질
- 해상도: 생성 크기와 대략 일치하는 이미지를 제공합니다. 1024에서 생성할 계획이라면, 작은 256 자르기로 학습하지 마세요.
- 다양성이 양보다 우수합니다: 같은 포즈의 5개 사본은 모델에 거의 가르치지 못하고 과적합으로 밀어줍니다.
- 캐릭터를 위해서는 깨끗한 배경이 도움이 됩니다: 복잡한 장면은 신호를 흐립니다.
캡션
- 짧고 문자 그대로: “파란색 작은 마스코트, 동그란 눈, 빨간 셔츠”, “연필 스케치, 크로스해치, 부드러운 그림자”.
- 명명에 일관성을 유지합니다. 캐릭터를 위해 고유한 이름을 만들면(“mori-kiko” 같은), 나중에 트리거할 수 있도록 모든 캡션에 사용합니다.
- 자동 캡션으로 시작한 다음 가볍게 정리할 수 있습니다. 핵심 아이디어를 반영하지 않는 형용사를 제거했습니다.
사용한 프로세스
- 12개의 주제 사진(정면/3분의 1각도/측면), 중립 배경.
- 제 다이어그램의 15개 스타일 프레임, 같은 용지 질감.
- 한 번의 시도, 기본 순위, 가벼운 정규화. 학습 시간: 임차한 A10G에서 약 16분. 설정: 약 10분. 두 번째 실행은 20% 적은 스텝을 사용하고 잘 작동했습니다.
기억할 한 가지가 있다면: 크고 시끄러운 폴더보다 적고 명확한 이미지가 낫습니다.
스타일 대 캐릭터 LoRA
저는 이전에 이것들을 함께 묶곤 했습니다. 다르게 작동합니다.
캐릭터/주제 LoRA
- 목표: 특정 정체성(사람, 마스코트, 제품)을 가르칩니다.
- 데이터: 일관된 주제, 다양한 맥락: 얼굴 정체성이 중요하면 얼굴 클로즈업.
- 프롬프트: 트리거 이름과 짧은 설명을 유지합니다. LoRA가 정체성을 처리하게 하세요: 포즈/장면을 조종합니다.
- 위험: 의상이나 배경으로의 과적합. 섞으세요.
스타일/질감 LoRA
- 목표: 표면 품질(선 작업, 팔레트, 붓놀림, 입자)을 가르칩니다.
- 데이터: 많은 다양한 주제, 한 가지 스타일.
- 프롬프트: 트리거 이름이 필요하지 않지만, 간단한 표시가 도움이 됩니다(“스케치라인 스타일”).
- 위험: 스타일이 내용을 삼킬 수 있습니다. 모든 것이 같은 뭉개진 그림이 되면, 강도를 줄이세요.
강도 및 혼합
- 대부분의 도구는 LoRA 무게를 드러냅니다. 캐릭터는 0.8 이상, 스타일은 0.6 이상으로 거의 가지 않습니다. 작은 밀어주기가 중요합니다.
- 두 개의 LoRA(하나는 스타일, 하나는 캐릭터)를 쌓을 수 있습니다. 하나가 지배적이고 다른 하나가 0.4 미만으로 유지될 때 최고의 결과를 얻었습니다.
캐릭터 LoRA를 “누가”로, 스타일 LoRA를 “어떻게”로 생각하는 법을 배웠습니다. 단순하지만 잘못된 것을 비난하지 않도록 합니다.
흔한 오류
제가 자주 듣는 주장과 실제로 본 것:
- “수백 개의 이미지가 필요합니다.” 12개로 사용 가능한 캐릭터를 학습시켰습니다. 더 많으면 도움이 되지만, 다양하고 깨끗할 때만입니다.
- “몇 시간이 걸립니다.” 적당한 GPU와 초보자 프리셋으로, 제 실행은 20분 이내입니다. 무겁고 사용자 정의된 설정은 더 오래 걸릴 수 있습니다.
- “LoRA는 프롬프트 엔지니어링을 대체합니다.” 소란을 줄이지만 제거하지 않습니다. 여전히 구성, 조명, 분위기에 대해 프롬프트합니다.
- “하나의 LoRA는 모든 모델에 적합합니다.” 항상 그렇지는 않습니다. 하나의 기준으로 학습한 LoRA는 형제 모델로 그럭저럭 전송될 수 있지만, 결과가 변합니다. 바꿀 수 없는 것이 아니라 관련된 것으로 취급합니다.
- “더 높은 강도 = 더 좋습니다.” 어느 시점을 지나면, 이미지는 같음으로 붕괴됩니다. 세부 사항이 번질러지면 무게를 내립니다.
- “자동 캡션은 편집 없이 괜찮습니다.” 좋은 시작입니다. 여전히 이상한 형용사(“불길한”, “영화 같은”)를 잘라냈습니다.
이것 중 아무것도 마술이 아닙니다. 것들이 합쳐지는 작고 반복 가능한 조정입니다.
빠른 용어 사전
- LoRA: 모든 것을 재학습시키지 않고 대규모 모델을 대상 개념으로 적응시키는 컴팩트한 학습된 무게 업데이트 집합입니다. IBM의 LoRA 문서에 따르면, 전체 미세 조정에 비해 학습 가능한 매개변수를 최대 10,000배 줄일 수 있습니다.
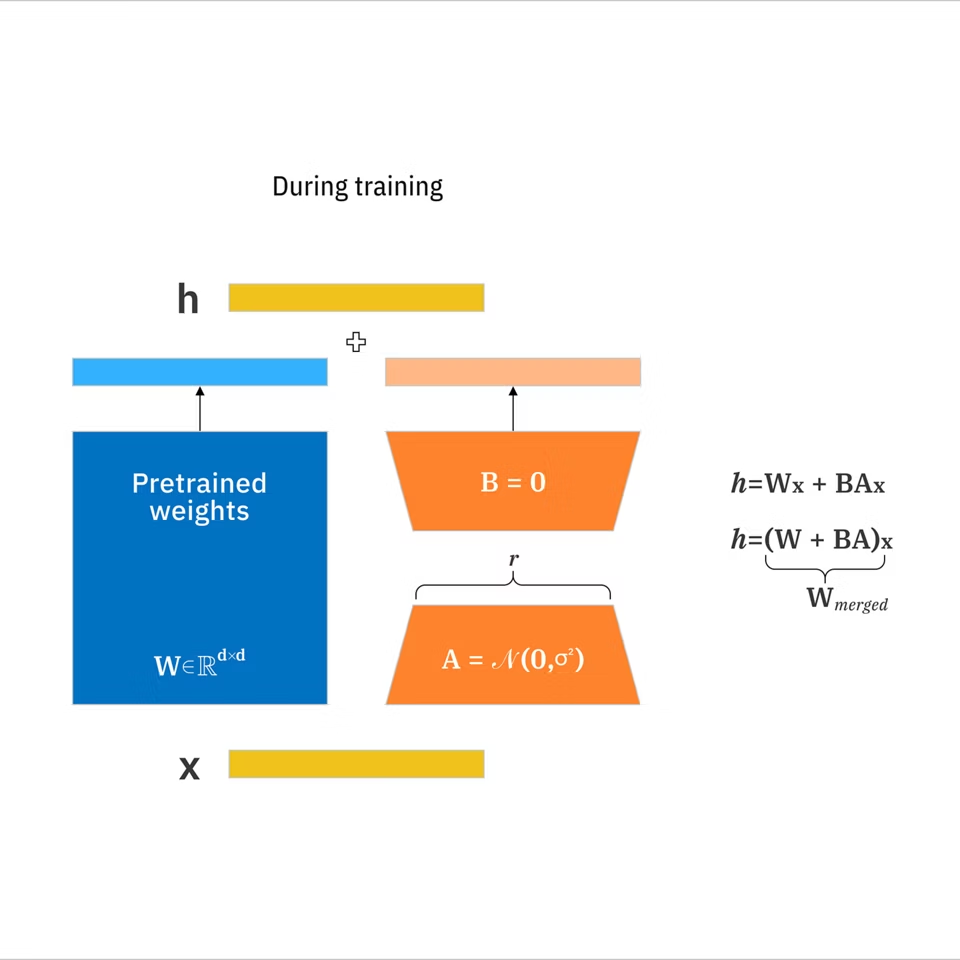
- 기본 모델: 생성하는 기반(LoRA를 사용하기 전에 로드하는 것).
- 순위(r): LoRA의 표현력을 제어하는 설정입니다. 더 높은 순위는 더 많은 뉘앙스를 캡처할 수 있지만 과적합 및 크기 증가할 수 있습니다.
- 무게/강도: LoRA가 생성 시간에 생성에 영향을 주는 정도입니다.
- 트리거 단어: 주제 LoRA를 호출하기 위해 프롬프트에서 사용하는 고유한 토큰입니다(예: 캡션에서 사용한 만들어낸 이름).
- 과적합: 모델이 학습 이미지를 암기하고 일반화를 멈춥니다. 거의 동일한 이미지로 나타납니다.
- 정규화: 과적합을 방지하는 기술 또는 추가 데이터입니다.
- UNet/텍스트 인코더: 이미지와 텍스트를 처리하는 모델의 부분입니다. 일부 학습은 둘 다 업데이트합니다: 초보자 프리셋은 종종 이미지 측을 더 많이 터치합니다.
- 캡션: 각 학습 이미지와 쌍을 이루는 텍스트입니다.
- 체크포인트: 모델이나 LoRA의 저장된 상태입니다.
이 중 어떤 것이 불확실하더라도 학습할 수 있습니다. 초보자 프리셋은 당신을 문제로부터 벗어나게 합니다.
WaveSpeed의 다음 단계
Z-Image LoRA를 설정 없이 실행하기 위해 WaveSpeed에서 초보자 친화적인 경로를 사용했습니다. 흐름이 차분했습니다:
- 기본 모델을 선택합니다.
- 8~20개 이미지와 짧은 캡션을 떨어뜨립니다.
- “스타일” 또는 “캐릭터”를 선택합니다.
- 학습을 시작하고 차를 만듭니다.
- 생성을 위해 LoRA를 로드하고 두 개의 무게(0.4 및 0.8)를 시도하여 범위를 느낍니다.
가장 도움이 된 것은 첫 번째 실행을 스케치로 취급하는 것이었습니다. 두 가지를 찾았습니다: 정체성이 5개 프롬프트에서 유지되었는지, 스타일이 내용을 삼키지 않고 질감을 유지했는지? 하나가 실패하면, 슬라이더가 아니라 데이터 세트를 조정했습니다.
같은 제약에 대처하고 있다면, 떠내려가는 캐릭터, 흔들리는 질감, 프롬프트가 체조가 되는 것, 살펴볼 가치가 있습니다. 이것은 제 경우였습니다: 당신의 경험은 다를 수 있습니다.
이것은 정확히 우리가 WaveSpeed를 만든 이유입니다. 캐릭터가 떠내려가고, 스타일이 흔들리고, 프롬프트가 체조가 될 때, 우리는 과도한 엔지니어링 없이 일관성을 원했습니다. WaveSpeed에서 우리는 초보자 친화적인 흐름으로 Z-Image LoRA를 실행합니다—명확한 기본값, 빠른 반복, 정체성과 질감을 안정적으로 유지하기에 충분한 제어로, 재시도에 덜 시간을 쓰고 실제로 이미지를 만드는 데 더 많은 시간을 쓸 수 있습니다.
→ WaveSpeed에서 간단한 LoRA 학습
 나 자신을 위해 기억할 작은 참고 사항: 프롬프트에서 싸우는 단어가 적을수록, 앞에 있는 이미지에 더 많은 주의를 기울입니다. 그것이 자동화하고 싶지 않은 부분입니다.
나 자신을 위해 기억할 작은 참고 사항: 프롬프트에서 싸우는 단어가 적을수록, 앞에 있는 이미지에 더 많은 주의를 기울입니다. 그것이 자동화하고 싶지 않은 부분입니다.
관련 기사

Seedance 2.0, WaveSpeedAI에 출시 예정: 네이티브 오디오가 포함된 ByteDance의 차세대 비디오 모델

Seedance 2.0 완벽 가이드: 멀티모달 비디오 생성

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: 최고의 비디오 생성 비교

Seedream 5.0-Preview 완벽 가이드: 지능형 이미지 생성

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: 완벽한 비교
