WAN 2.7ファースト&ラストフレームコントロール:ビルダーガイド
WAN 2.7のファースト&ラストフレームコントロールを使って予測可能な動画生成を実現する方法 — 入力準備、APIパラメータ、本番ワークフローのヒントを解説。

みなさん、Doraがやってきます。多くのチームがファースト/ラストフレーム制御を「2枚の画像をアップロードするだけ」と説明しているのを見続けてきました。それは非同期ジョブキューを「ただ待つだけ」と説明するようなものです。仕組み自体は難しくありませんが、入力設計の意思決定こそが、多くの本番ワークフローが静かに崩壊していく場所です。
このガイドは、一度うまくいったデモではなく、再現性のある出力を必要とするビルダーのためのものです。
ファースト/ラストフレーム制御が実際に行うこと
標準I2Vとの比較で解決する問題
標準的なimage-to-video(I2V)は最初のフレームを固定し、その後モデルが即興で動きを作ります。結果としてコミュニティが「ドリフト」と呼ぶ現象が起きます——被写体、カメラ位置、または照明が、意図していたターゲット状態から徐々にずれていくのです。製品デモや明確なエンドポイントが必要なナラティブシーケンスでは、ポスト処理での修正に多大なコストがかかります。
WANのFLF2Vアプローチ は追加の制御調整メカニズムを使用しています。ファーストフレームとラストフレームが制御条件として扱われ、両方の画像のセマンティック特徴が生成プロセスに注入されます。これにより、モデルがそれらの間で動的に変換を行いながら、スタイル、コンテンツ、構造の一貫性を保ちます。
生成中に両フレームがどのように使われるか
モデルは単純にピクセル値を補間するわけではありません。CLIPのセマンティック特徴とクロスアテンション機構を使ってビデオを安定させます——この設計は、単一アンカーアプローチと比較してビデオのジッターを低減することが示されています。ファーストフレームが初期状態を定義し、ラストフレームが目的地を制約します。その間の動きのパスは推論されるものであり、指定されるものではありません。これが強みでもあり、主な失敗パターンでもあります。
モデルがパス間について推論すること
テキストプロンプトは、トランジションがどのように起きるかを導きます——単に起きるかどうかだけではありません。プロンプトに「製品がゆっくりと回転して正面を見せる」と書けば、そのモーションの説明が推論されるパスを形成します。プロンプトがなくても、モデルは妥当なトランジションを試みますが、方向転換、カメラの動き、ペーシングに対するコントロールはずっと少なくなります。
入力の準備
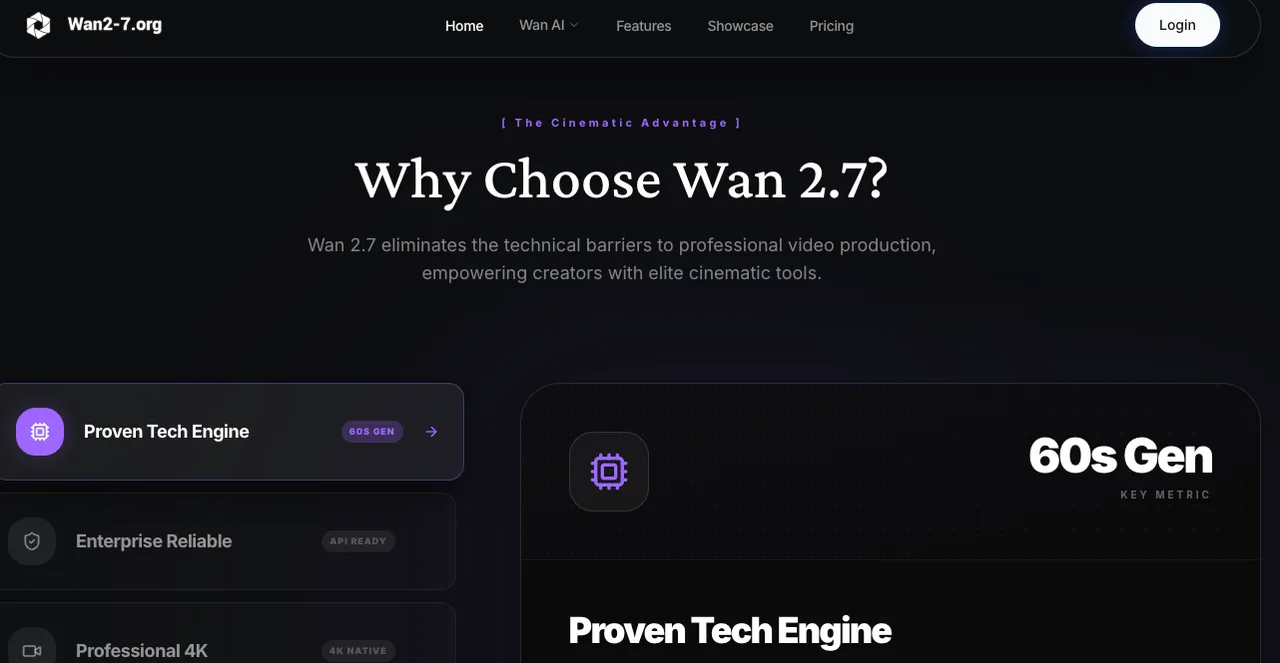
画像仕様の要件
モデルはファーストフレームのアスペクト比をターゲット出力にできる限り近づけて使用します。3:4の入力(750×1000)の場合、720P出力設定では816×1104程度のものが生成されます——正確に3:4にはなりません。正確な比率が必要な場合は、ポスト処理でのクロップやレターボックス加工を計画してください。WANシリーズ全般において、品質の高い出力には720p(1280×720またはポートレート相当)が推奨解像度です。小さな解像度での実行はテスト反復では有効な戦略ですが、最終的な制作物には適しません。
フォーマット:PNGまたは高品質JPEG。 圧縮されたサムネイルをファースト/ラストフレームとして使わないでください——圧縮アーティファクトは、モデルが意図的な視覚情報として解釈しなければならないノイズを導入します。
うまくいくフレームペアリング戦略
最も強力なペアは3つの特性を共有しています:一貫した光源の方向、マッチする被写界深度の特性、そして両方の位置で空間的に妥当な被写体。ディフューズなスタジオライトで撮影した製品写真を、同じ製品を少し違う角度で撮影したエンドフレームとペアにするとうまくいきます。パックショットからライフスタイルのヒーローショットも、ライティング設定が似ていればうまくいきます。
ナラティブシーケンスでは、ペアを動詞として定義することを考えてください:開く→閉じる、before→after、組み立て中→完成。セマンティックな関係が明確であればあるほど、推論されるパスはより一貫性を持ちます。
悪いフレームペアの特徴
よくある3つの原因:
一貫性のない照明方向。 ファーストフレームのキーライトが左45°で、ラストフレームがオーバーヘッドライトで撮影されていた場合、モデルは2つの異なる影の環境間でトランジションを試みます。結果として、クリップの途中で光源が飛ぶように見えるのが通常で、レンダリングエラーのように見えます。
空間的なミスマッチ。 ワイドなエスタブリッシングショットとタイトなクローズアップのペアは、モデルにカメラの動きを作り出させます。時にはそれが意図的なこともありますが、通常はそうではありません。ズームやプルを明示的にプロンプトしていない限り、焦点距離をおおよそ一定に保ってください。
相反する奥行きキュー。 ファーストフレームにボケがあり、ラストフレームですべてにフォーカスが合っている場合——モデルはこれを被写界深度の変化として解釈し、アニメートしようとします。それが常に間違っているわけではありませんが、意図していたことであることはほとんどありません。
API実装
以下はWANシリーズのドキュメント化されたFLF2Vパターンを反映しています。本番使用の前に、現在のパラメーター名とエンドポイントパスをAlibaba Cloud Model Studioのドキュメントで確認してください。WAN 2.7 APIの詳細はリリース時に確認が必要です。
ペイロード構造
コアパターンは2つの画像入力を含みます——パブリックURLまたはローカルファイルパス経由——first_frame_urlとlast_frame_urlとして渡され、テキストプロンプトと解像度設定が伴います。
Pythonリクエストパターン(疑似コード)
# リリース時にモデル名とエンドポイントを確認してください——バージョン間で名前が変わります
import os
from dashscope import VideoSynthesis
response = VideoSynthesis.async_call(
model="wan2.x-flf2v-<リリース時に確認>", # 正確なモデル文字列を確認
first_frame_url="https://your-cdn.com/start.png",
last_frame_url="https://your-cdn.com/end.png",
prompt="固定カメラ。最初の画像から始まり、最後の画像で終わる。[モーションを記述]",
negative_prompt="flicker, warping, blur",
resolution="720P", # 受け付ける値を確認
# seedパラメーター: 良い結果が出たらこれをロック
)
task_id = response.output.task_id長時間ジョブの非同期処理
image-to-video生成タスクは通常1〜5分かかります。APIは2ステップの非同期パターンを使用します:タスクを送信してタスクIDを取得し、その後結果をポーリングします。最初からポーリングをパイプラインに組み込んでください。テスト呼び出しでも同期的な動作を前提としないでください——素朴な実装では、タイムアウトが結果を静かに失わせます。
本番ワークフロー:ドラフトからファイナルへの手法
ステップ1 — リファレンスペアを作成して1回テスト実行する
単一のペアから始めてください。1つの出力をエンドツーエンドで見るまでバッチ処理はしないでください。プレースホルダーのストック画像ではなく、ターゲットコンテンツを使用してください——空間的・照明的特性が実際のアセットライブラリを代表している必要があるからです。
ステップ2 — バッチの前にモーションパスを検証する
0.5倍速で全クリップを1回見てください。 確認するもの:クリップ途中のジッター、クリップの50〜70%あたりでの被写体のアイデンティティドリフト(ここにほとんどのアーティファクトが集中します)、そして照明の不連続性。これらのいずれかが見られたら、プロンプトに触れる前に入力ペアを修正してください。
ステップ3 — 一貫性のためにベストなシードをロックする
クリーンな出力が得られたら、シード値を記録してください。FLF2Vモデルは、中間の動作と変換ロジックを導くオプションのプロンプトを受け付けます。ロックされたシードとロックされたプロンプトの組み合わせにより、同様の入力ペアに適用できる再現可能な生成ユニットが得られます。これがバッチ制作を確率的ではなく予測可能にするものです。
ステップ4 — バッチ生成にスケールする
バッチを次のように構成してください:品質のアンカーとなる1つの正規の「テストペア」、その後に同じコントロールされた撮影セットアップから生成されたバリアントペア。Hugging FaceのWAN FLF2Vモデルページには、API呼び出しと並行してローカル推論を実行するチーム向けのオープンウェイトバージョンがドキュメント化されています。
この機能が適している場面(と適していない場面)
最適: エンドポイントが重要な製品デモシーケンス(パックショット→機能リビール)、明確なbefore/afterが定義されたナラティブの連続ショット、シリーズ内の複数クリップにわたって空間的安定性が必要なコントロールされたカメラパス。
適していない: 急な方向転換を伴う非常にダイナミックなモーション(モデルはそれを滑らかにしてしまい、ドラマ性が失われることが多い)、ファーストとラストフレームが明確なセマンティック関係を持たないあいまいな空間的トランジション、またはフレーム精度のタイミングが必要なシナリオ——モデルがペーシングをコントロールするのであって、あなたではありません。
よくある失敗パターンと修正方法
クリップ途中のモーションアーティファクト。 通常、入力ペアの空間的ミスマッチが原因です。モデルは早い段階で補間パスに「コミット」し、非一貫性が中間点あたりで表面化します。修正:プロンプトを変更する前に、フレーム間の関係を締め直す。
フレームスタイルの不一致。 ファーストフレームがスタイライズされたレンダーで、ラストフレームが写真の場合、モデルはビジュアルスタイルをブレンドしようとします。これはクリーンな出力をほとんど生みません。画像の処理方法を合わせてください——両方ともレンダー、両方とも写真、両方ともイラストレーション。
モデルがラストフレームを無視する。 プロンプトが、ラストフレームで論理的に終わることができないモーションを記述している場合に起きます。モデルは競合する場合、フレームへの忠実性よりもプロンプトの一貫性を優先します。ファーストフレームを出発点とするだけでなく、ラストフレームに到達するようにプロンプトを書いてください。
FAQ
- ファースト/ラストフレームをtext-to-videoでも使えますか、それともI2Vのみですか? FLF2Vモードはシスなります2Vの拡張です。両方のフレーム入力が必須です。標準T2Vは設計上、エンドフレーム制約を受け付けません。
- フレーム入力に最適な画像フォーマットは何ですか? クリーンなエッジや透明度処理が必要なものにはPNG。高品質JPEG(>90品質)は写真には問題ありません。プラットフォームがサポートを確認していない場合はWebPを避けてください。
- 標準I2Vより費用がかかりますか? 価格は解像度依存——720pは生成あたり480pの約2倍のコストがかかります。FLF2V自体はドキュメント化された価格に別途プレミアムはありませんが、使用する特定のプラットフォームで確認してください。
- 急な方向転換が必要なモーションはどう扱いますか? シーケンスを複数のクリップに分割し、中間フレームをエンドポイントとして使用します。不連続なモーションを単一の生成で処理しようとするのではなく、ポスト処理でチェーンしてください。
- これを9グリッド入力モードと組み合わせることができますか? これらは別々の入力モードです。WAN 2.7はファースト/ラストフレーム制御と9グリッドimage-to-videoを独立した機能としてサポートしています。現在は単一の呼び出しで組み合わせることはできません——これが変わる場合はリリース時に確認してください。
まとめ
ファースト/ラストフレーム制御における興味深い設計空間はAPI呼び出しではありません——それは入力ペアです。そこに本当の本番的なレバレッジがあり、ほとんどのチームが投資を怠っている部分です。明確なセマンティック関係を持つ適切に設計されたフレームペアは、不一致な入力とペアになった完璧なプロンプトを常に上回ります。
バッチパイプラインを構築するチームへ:入力ペアライブラリを、後回しにするものではなく、ファーストクラスのアセットとして扱ってください。ロックされたシードと検証済みのペアフォーマットが揃えば、生成側はルーティンになります。ComfyUIコミュニティは、API呼び出しと並行してローカル推論も実行している場合に読む価値のあるWAN FLF2Vワークフロー設定を詳しくドキュメント化しています——フレームコンディショニングが実際にどのように機能するかのノードレベルの洞察として参考になります。
静かな気づきに何度も戻ってきます:制約こそが機能です。モデルに目的地を与えることで、自分が実際に何を望むかについて正確になることを強います。これは制限ではありません——オープンエンドな生成よりも優れた出力を生み出す傾向がある規律です。
AIビデオワークフローをさらに探求する:





