Nano Banana Pro API、WaveSpeedで使う方法 + 料金について

Nano Banana Pro APIのドキュメントを見て「次に何をすればいいんだ?」と思ったことはありませんか?あなただけではありません。私はDoraで、数十のAPIを実際にテストしてきました。ドキュメントにないエンドポイントやサプライズ課金メールを何度も経験しました。このガイドでは、Nano Banana Pro APIを効率的に呼び出す方法をステップバイステップで説明し、プロジェクト予算を圧迫する価格設定の落とし穴を避ける方法をお伝えします。
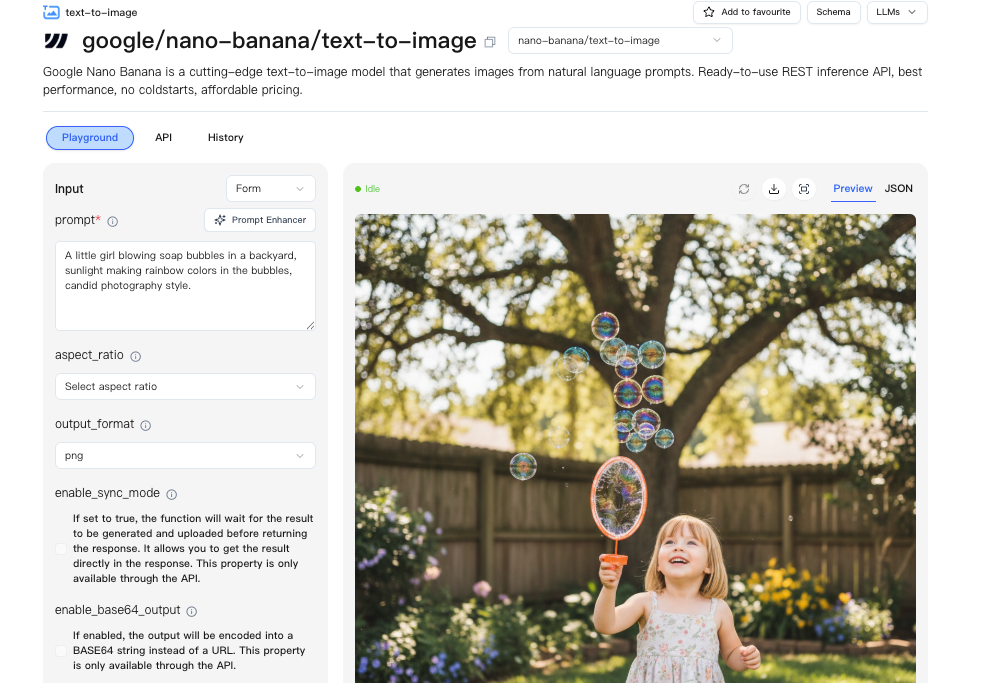
エンドポイント / フロー
私はスタック全体を切り替えませんでした。Nano Banana Proを小さなアダプタサービスでラップして、コードを引き裂くことなくプロバイダー間を切り替えられるようにしました。WaveSpeedのダッシュボードはそれを期待以上に簡単にしてくれました。1つのエンドポイント、一貫した認証、そして検索する必要のないシンプルなクォータビューです。
私のフローは次のようなものでした:
- 小さな前処理で入力をクリーンアップしました(用語を小文字化、余分なスペースを削除、タイムスタンプを統一)。
- リクエストをNano Banana Proエンドポイントに安定したシステム指示と少数の例を使って送信しました。
- 安定したプロンプトと一般的なレスポンスをキャッシュしました。凝ったものではなく、ローカルのTTLキャッシュとWaveSpeed自体の同一ペイロード用レスポンスキャッシュです。
- トレース(プロンプトハッシュ、パラメータ、レイテンシ、トークンカウント、エラーコード)を保存しました。
最も役に立ったのは予測可能性です。エンドポイントが私の代わりに賢いルーティングをしようとしませんでした。Nano Banana Proを要求すれば、それが得られました。実行中、中央値のレイテンシは安定した範囲の周りで推移し、米国の営業時間中の分散は予想ほどスパイクしませんでした。完璧ではありませんが、ベースラインよりも穏やかでした。

最も安い行を追い求めるよりも安定したルーティングと透明な使用状況を重視するなら、Wavespeedを試してみてください。私たちは予測可能なエンドポイント、クリーンな認証、推測を必要としない使用状況の可視性に焦点を当てています。
1つ小さな問題がありました。ストリーミングオプションは機能しましたが、実際の使用では知覚されるレイテンシを十分に削減しませんでした。短いテキストの場合、ストリーミングは余分な手続きに感じました。より長いサマリーの場合は快適でしたが必須ではありませんでした。手動レビューセッション以外は無効のままにしました。
重要なパラメータ
理由がない限りノブをいじらないようにしています。実際に重要だったのはほんの一握りです。
- モデル選択:Nano Banana Proはテスト期間(2026年1月現在)を通じて一貫していました。予期しないスワップはありません。この安定性が私が続けた主な理由です。
- 温度:タグ付けと分類の場合、ほぼゼロに設定しました。これで不一貫性が減りました。合成を少し含むサマリー化の場合、0.3~0.4は簡潔な範囲内でフレージングを滑らかにしてくれました。
- 最大トークン:短いタスクではタイトな上限を設定して、膨張した出力を避けました。長いサマリーの場合は寛大な制限を設け、投稿後の文字数に依存しました。
- システム指示:長いポリシーブロックよりも短くシンプルな指示の方が効果的でした。ロールを設定するために1文を使用し、「推測しないで、不確かな場合は証拠を示す」という小さなルーブリックを追加しました。追加すればするほど、より多くのヘッジが行われました。
- Top-pと温度:Top-pは1.0に固定して温度を調整しました。両方を混ぜると違いを追跡しづらくなりました。
私を驚かせたのは、モデルがサンプルの配置にどの程度敏感であるかでした。指示の直後に2つの具体的な例があれば、5つを全体に混ぜるより効果的でした。例を最後に移すと、エッジケースの品質が低下しました。APIはフォーマットを強制しませんでしたが、一貫性は報われました:同じフィールド名、同じ順序、同じ句読点です。
品質ノブ
温度とトークン上限を超えて、出力の感触を変えたいくつかの動きがあります:
- 長いポリシーより短いプライマー。1行の意図+2つの例は、1ページの指導よりも少ない過剰説明を生成しました。
- 証拠プロンプトが役に立ちました。「このタグをトリガーしたフレーズを引用してください」と聞くことで、架空のタグ付けが大幅に減りました。また、幻覚を素早く特定できるため、QAが穏やかになりました。
- ハード制約よりもソフト制約。「3~5個の箇条書きを目指す」はより効果的でした。「正確に4個の箇条書き」より。モデルはジャンプすることなく境界を尊重しました。
- 決定論的フレーミング:「戻す:ラベル、信頼度(0~1)、証拠(テキスト)」という構造を少し追加しました。これは出力をすっきりに保ちながら、スキーマの刑務所のような感覚を避けました。
品質が低下した2つのケースがあります:汚いOCR入力とドメイン固有の言葉遣いです。修正はより賢いプロンプティングではありませんでした。ほんの小さな前処理ステップです:ジャンク文字を削除し、ハイフンを統一し、未知の用語を「見つかった用語」として上部にリストアップしました。それを行うと、モデルは奇妙なラベルの推測を止めました。これは初日の時間を節約しませんでしたが、4回目の実行までに再読する必要がなくなったことに気付きました。精神的な努力が少なくなります。
価格設定に関する考慮事項
最も安い行を追い求めませんでした。予測可能な出力のための予測可能な支出を望んでいました。
テスト全体で、Nano Banana ProはWaveSpeedの千トークンあたりのコストの中程度に着地しました。静かな利点は、より一貫したトークン使用状況でした。モデルが正しいプロンプト形状で饒舌にならなかったので、サプライズスパイクが少なくなりました。ソフト箇条書き制約を追加した後、サマリーの平均出力長は安定しました。
2つの小さな習慣は品質を害さずにコストを削減しました:
- 定期的な指示と例のプロンプトキャッシング(WaveSpeedが一部を行いました。アダプタはそれを行い、同一のリクエストをショートサーキットします)。
- ノーオペレーションケースの早期終了。入力が短すぎるか明らかに無関係な場合は、呼び出しをスキップしてデフォルトを返します。これは明らかに聞こえますが、請求書を見るまで忘れがちです。
スパイキーなワークロードを扱っている場合、従量課金モデルは私にとって意味がありました。使用状況が安定していて重い場合は、コミット済みクレジットを調べてみるかもしれませんが、実際の数字を1か月取得した後のみです。推測に基づいて事前にコミットしません。
バッチのヒント
試用期間中に2回の週別バッチを実行しました。いくつかのパターンが役に立ちました:
- 小さく安定したバッチサイズ。50項目のチャンクに落ち着きました。並行性は控えめでした(10~12)。スループットは問題なく、エラー処理は健全なままでした。
- バックオフ付きの再試行予算。一時的な問題の場合は1回の高速再試行、その後より長いバックオフ、その後アイテムを駐車します。無限ループはありません。
- べき等トークン。同じ入力、同じハッシュ、同じリクエストキー。再試行が着地した場合、2倍に支払ったりダブルログしたりしませんでした。
- 事前検証。必須フィールドがない入力をAPIに送信する前に拒否しました。退屈ですが、時間を節約しました。
1つの摩擦はレート制限の透明性でした。WaveSpeedのダッシュボードは使用状況を明確に表示しましたが、1分間のシーリングはピーク時に少し不透明に感じました。アダプタに移動平均ガードを追加し、429をエラーではなくシグナルとして扱うことで解決しました。その後、バッチはドラマなく実行されました。
エラー処理
エラー処理をシンプルで監視可能に保ちました。REST API エラーハンドリングのベストプラクティスに従いました。
- タイムアウト:保守的なクライアントタイムアウトを設定しました。リクエストが長く実行された場合、より遅い再試行レーンにマークしました。長いリクエストは再試行時に完了することが多い:キーは高速レーンを詰まらせないことでした。
- 4xxと5xx:4xxは、レート制限でない限り手動レビューのために駐車されました。5xxは短い再試行バースト。これは悪い入力で循環を燃やすことを避けました。
- 出力のガードレール:モデルに常に信頼度スコアを含めるよう要求しました。スコアが0.6以下に低下した場合、アイテムをヒューマンレビュー待機キューに送信しました。シンプルなトリアージ、後悔が少ない。
- ロギング:フラグされた場合のみ生のプロンプトと応答をログに記録し、すべてではありません。プライバシーはより清潔に保たれ、ログは小さくなりました。
風刺に自信を持っているが間違っているラベルなど、本物のモデル不良がいくつかありました。プロンプトでそれから抜け出そうとしませんでした。皮肉チェックを別の軽量パスとして追加してから、メインのタガーを適用しました。2つのステップ、より少ない混乱。
ペイロードロジックの例(非コード説明)
平易な言語で、私が送信したものの形です。
- システムロール:ジョブに関する1文。例えば、「マーケティング コピーをラベルの小さなセットでタグ付けし、決定を促した単語を指す慎重な分類器です。」
- コンテキスト:奇妙な用語の小さな用語集、および2つの気の利いた例(1つのクリーン、1つのトリッキー)。
- 指示:何を返すか、どの順序で返すか(ラベル、信頼度、証拠)、およびトーン制約(簡潔、ヘッジングのない言語)。
- 入力:生のテキスト、スペースのクリーンアップ以外は未処理。
- 制限:証拠の要求される最大長とラベル数の上限。
アダプタ側では、システムロール+例+指示から安定したハッシュを生成しました。そのハッシュが同じ入力の以前のリクエストと一致した場合、キャッシュをチェックしました。そうでない場合は、WaveSpeedのNano Banana Proエンドポイントを温度とトークン上限を呼び出して呼び出しました。位置ではなくキーで出力を解析したので、小さなフレージング変更は何も破りませんでした。
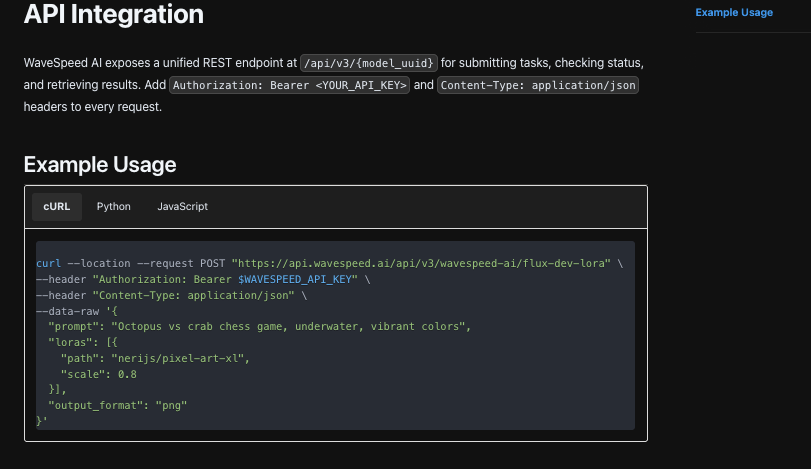
レスポンスが必須キーを欠いている場合、モデルに機械的に修正を依頼しませんでした。短いリマインダーで再度プロンプトを発行しました:「3つのキーのみを返す。」最大1回の再試行。その後、レビューキューに移動します。これにより、システムが自分自身をナンセンスにループするのを防ぎました。
関連記事

Seedance 2.0がWaveSpeedAIに登場予定:ネイティブ音声対応のバイトダンス次世代ビデオモデル

Seedance 2.0完全ガイド:マルチモーダルビデオクリエーション

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1:究極のAIビデオ生成モデル比較

Seedream 5.0-Preview完全ガイド:インテリジェント画像生成

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: 完全比較
