Z-Image LoRA: その意味と必要な場合(初心者向け)

こんにちは、みなさん。ドーラです。先週、何も訓練するつもりはありませんでした。ただ、スクリーンショットの隅に座る、一貫性のある小さなヘルパーのようなイラストキャラクターが欲しかっただけです。プロンプトで何度も近い結果が出ていたのに、それが流れていってしまいました。眉毛が変わる。色が滑る。火曜日(2026年1月13日)、何度かの失敗の後、私はZ-Image LoRAを試してみました。ウサギの穴にはまると思っていましたが、短い廊下のようなものでした。
これは勝利を宣言するものではありません。すぐに結果が出たわけではありません。しかし、このセットアップは十分な障害を取り除いてくれて、設定について考えるのをやめて、画像について考え始めました。ここで何が上手くいったのか、何が上手くいかなかったのか、そしていつLoRAが必要ないかについて説明します。
1分で分かるZ-Image LoRA
LoRA(ローランク適応)は、ベースの画像モデルの上に訓練する小さなアドオンで、モデル全体を再訓練することなく、特定のスタイルまたは被写体に向かって推し進めます。
 Z-Image LoRA(初心者向け)の得意なこと:
Z-Image LoRA(初心者向け)の得意なこと:
- 複雑な設定を隠してくれます。いくつかの基本的なもの(画像、キャプション、ターゲット)を選択しますが、デフォルトは理にかなっています。
- 十分に速く訓練できるため、繰り返し改善できます。最初のパス(10画像)は、中程度のGPUで約12~18分かかりました。
- レイヤーのように読み込みます。生成ツールでオン/オフを切り替えて、通常どおりプロンプトを入力し、オプションでトリガーワードを使用します。
得られるもの:モデルを微調整する小さなファイルで、一貫性、ロゴ、キャラクター、ブラッシーな水彩画のような外観が必要なときにモデルを導きます。オンにしなければ、ベースモデルは通常どおり動作します。
LoRAが不要なケース
愛情を込めて言いますが、私たちの多くが訓練に手を出すのが速すぎます。LoRAを使わない場合のいくつかのケースがあります:
- ベースモデルがすでに近い結果を出している。参照画像を使った短いプロンプトで8/10の使える結果が得られれば、完了です。IP-AdapterまたはImage Promptで十分な場合があります。
- 一貫性ではなく、バリエーションが必要です。各出力が異なるべき場合、LoRAは過剰に制御する可能性があります。
- 一度きりのビジュアル。単一のバナーの場合、訓練設定よりも5分余分にプロンプトを作成するでしょう。
- 制約が構成にある場合、アイデンティティではなく。ControlNetやポーズガイダンスなどのツールは、モデルに新しい概念を教えることなく、レイアウトを形作ります。
簡単なテストを使用します:シンプルなシードスイープと2~3つのプロンプト調整で、5つの画像全体で気になる要素(同じキャラクター、同じロゴの比率)を保持できない場合、それがLoRAを検討する時です。それ以外の場合は、シンプルなままにしておきます。
LoRAが役に立つとき
先週(2026年1月)、2つの状況で最も違いを感じました:
- ドキュメント全体で再利用したい小さなマスコット。プロンプトで目とシャツの色が揺らいでしまいました。短いLoRA後、これらは安定し、ポーズと背景に焦点を当てることができました。
- 図用の柔らかい鉛筆テクスチャ。「鉛筆スケッチ」とプロンプトできますが、陰影が毎回変わります。15画像のスタイルLoRAは、コンテンツをピンで留めることなく、一貫した線の品質をくれました。
LoRAがおそらく役立つ兆候:
- 多くのシーンで同じ被写体が必要です。
- 特定のアートテクスチャが重要で(クロスハッチ、リソグラフドット、厚いガッシュエッジ)、流れていく。
- プロンプトジムナスティクスを減らしたい。訓練後、私のプロンプトは80~100トークンから30~40に減りました。精神的な努力は時間以上に減りました。
意外だったのは、その影響がいかに静かに感じたかです。劇的なビフォーアフターなし。ただ、より少ないリトライ、より少ない「惜しい」。
データ要件
 これをシンプルに保ち、予想以上にうまくいきました。先週の2つの短い実行からのいくつかのメモ:
これをシンプルに保ち、予想以上にうまくいきました。先週の2つの短い実行からのいくつかのメモ:
量
- キャラクター/被写体: 様々な場合(角度、照明、軽い衣装の変更)、8~20画像で十分な場合があります。私は12を使用しました。
- スタイル/テクスチャ: 同じ外観を共有しているが、異なるコンテンツの10~30画像。私は15を使用しました。
品質
- 解像度: 生成サイズにほぼ一致する画像を供給します。1024で生成する予定の場合、小さな256クロップで訓練しないでください。
- ボリュームより多様性: 同じポーズの5つのコピーはモデルにほとんど何も教えず、過剰適合に向かって押し進めます。
- キャラクターのためにクリーンな背景は役に立ちます: 忙しいシーンはシグナルを曇らせます。
キャプション
- 短くて文字通り:「丸い目、赤いシャツの小さな青いマスコット」、「鉛筆スケッチ、クロスハッチ、柔らかい影」。
- ネーミングで一貫性を保ちます。キャラクター用に一意の名前を発明する場合(「mori-kiko」など)、後で起動できるようにすべてのキャプションで使用します。
- オートキャプションから始めて、軽くクリーンアップできます。コアアイデアを反映しなかった形容詞をカットしました。
私が使用したプロセス
- 12の被写体写真(前面/三四分の一面/側面)、ニュートラル背景。
- 私の図から15のスタイルフレーム、同じ紙のテクスチャ。
- 1パス、デフォルトランク、軽い正則化。訓練時間:レンタルA10Gで約16分。セットアップ:約10分。2番目の実行は20%少ないステップを使用し、うまくいきました。
1つだけ覚えておくべきこと:大きくて騒々しいフォルダより、より少ない、より明確な画像。
スタイルとキャラクターLoRA
これらを一緒にまとめるのに使われていました。彼らは異なる動作をします。
キャラクター/被写体LoRA
- 目標: 特定のアイデンティティ(人、マスコット、製品)を教えます。
- データ: 一貫した被写体、様々なコンテキスト:顔のアイデンティティが重要な場合は顔のクローズアップ。
- プロンプト: トリガー名と短い説明を保ちます。LoRAがアイデンティティを処理させます。ポーズ/シーンを操舵します。
- リスク: 衣装や背景への過剰適合。それらを混ぜます。
スタイル/テクスチャLoRA
- 目標: 表面の品質(線画、パレット、ブラシストローク、グレイン)を教えます。
- データ: 多くの異なる被写体、1つのスタイル。
- プロンプト: トリガー名は必要ありませんが、シンプルなマーカーが役立ちます(「スケッチラインスタイル」)。
- リスク: スタイルがコンテンツを飲み込みます。すべてが同じぼやけた絵画になる場合、強さを減らします。
強さとミキシング
- ほとんどのツールはLoRA重みを公開します。キャラクター用に0.8、スタイル用に0.6を超えることはめったにありません。小さなナッジが重要です。
- 2つのLoRAをスタックできます(1つのスタイル、1つのキャラクター)。1つが支配的で、もう1つが0.4未満のままのときに、最良の結果が得られました。
キャラクターLoRAを「誰」と、スタイルLoRAを「どのように」と考えるようになりました。シンプルですが、間違ったものを責めるのを防いでくれます。
一般的な誤解
私が多く遭遇する主張と、実際に見たこと:
- 「数百の画像が必要です。」12で使える文字を訓練しました。もっとが役立ちますが、様々できれいな場合のみです。
- 「数時間かかります。」控えめなGPUとビギナープリセットで、私の実行は20分以内に終わりました。ヘビー、カスタム設定はより長くかかります。
- 「LoRAはプロンプトエンジニアリングに代わります。」それはいじくり回しを減らしますが、削除しません。作成、照明、ムードのためにプロンプトを入力し続けます。
- 「1つのLoRA全モデルに合わせます。」必ずしも。1つのベースで訓練されたLoRAは兄弟モデルへ転送できますが、結果はシフトします。それらを相互交換可能ではなく、関連するものとして扱います。
- 「より高い強さ=より良い。」ある時点を過ぎると、画像が同一性に崩壊します。詳細がぼやける場合、重みを下げます。
- 「自動キャプションは編集なしで問題ありません。」彼らは良いスタートです。コンセプトの一部ではなかった奇妙な形容詞(「不気味」、「映画的」)をまだトリミングしました。
このどれも魔法ではありません。複合する小さな、反復可能な微調整です。
クイック用語集
- LoRA: モデル全体を再訓練することなく、大規模なモデルをターゲットの概念に適応させる、学習された重み更新のコンパクトセット。IBMのLoRAドキュメントによると、それは完全なファインチューニングと比較して訓練可能なパラメータを最大10,000倍削減できます。
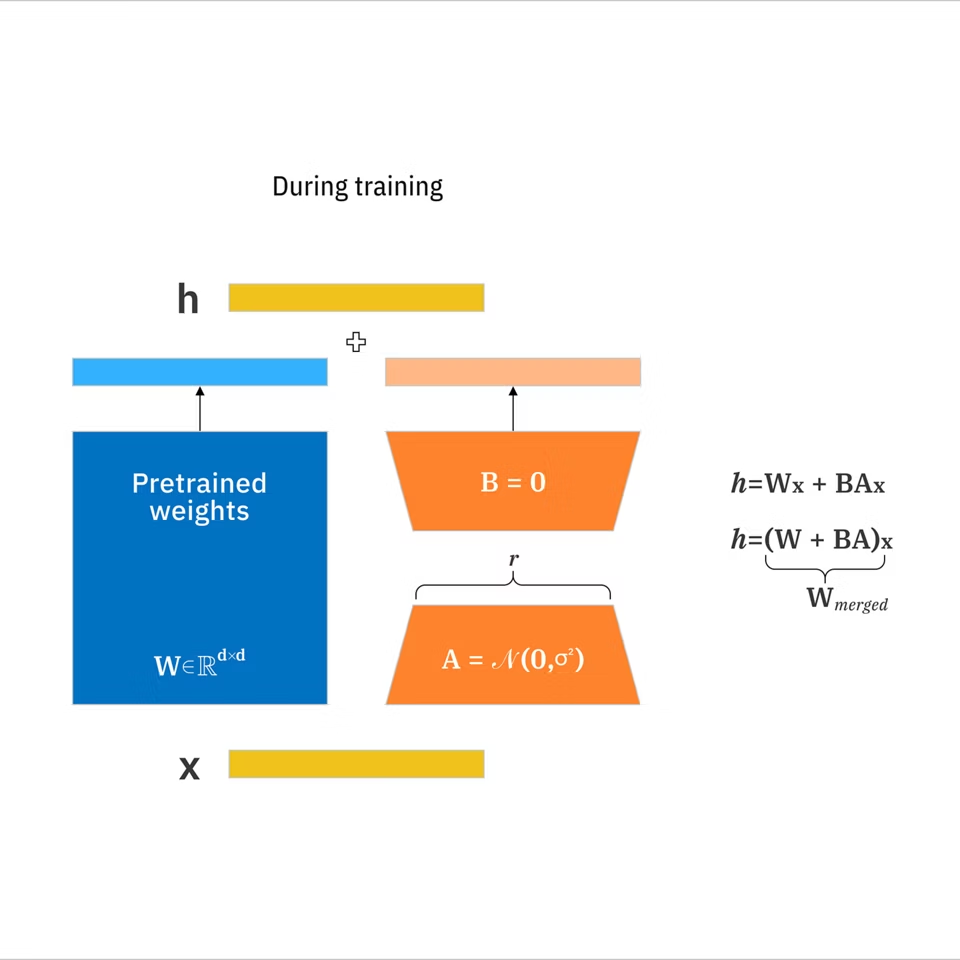
- ベースモデル: 生成する基礎(任意のLoRAの前にロードするもの)。
- ランク(r): LoRAがどれほど表現力があるかを制御する設定。より高いランクはより多くのニュアンスをキャプチャできますが、過剰適合して膨らむ可能性があります。
- 重み/強さ: 推論時にLoRAが生成にどれほど強く影響するか。
- トリガーワード: プロンプトで被写体LoRA(キャプションで使用した創作名など)を呼び出すために使用する一意のトークン。
- 過剰適合: モデルが訓練画像を暗記し、一般化を停止するとき。ほぼ複製として現れます。
- 正則化: 過剰適合を防ぐテクニックまたは追加データ。
- UNet/テキストエンコーダー: 画像とテキストを処理するモデルの部分。一部の訓練は両方を更新します:ビギナープリセットは多くの場合、画像側をより多くタッチします。
- キャプション: 各訓練画像に対になったテキスト。
- チェックポイント: モデルまたはLoRAの保存された状態。
これらのいずれかがぼやける場合でも、訓練できます。ビギナープリセットは問題を避けるように設計されています。
WaveSpeedの次のステップ
Z-Image LoRAを設定なしで実行するWaveSpeedのビギナーフレンドリーなパスを使用しました。フローは穏やかでした:
- ベースモデルを選択します。
- 8~20の画像と短いキャプションをドロップします。
- 「スタイル」または「キャラクター」を選択します。
- 訓練を開始し、紅茶を作ります。
- 生成用にLoRAを読み込み、2つの重み(0.4と0.8)を試して範囲を感じます。
最も役に立ったのは、最初の実行をスケッチとして扱うことでした。2つのことを探していました:5つのプロンプト全体でアイデンティティが保持されたかどうか、そしてスタイルがコンテンツを飲み込むことなくそのテクスチャを保持したかどうか。1つが失敗した場合、スライダーだけでなく、データセットを調整しました。
同じ制約に対処している場合、流れていくキャラクター、揺らぐテクスチャは、一見の価値があります。これは私にはうまくいきました:あなたの成功は異なるかもしれません。
これはまさに私たちがWaveSpeedを構築した理由です。キャラクターが流れていくとき、スタイルがぐらつき、プロンプトが体操に変わるとき、私たちは過度なエンジニアリングなしに一貫性を得るためのより穏やかな方法をしたかった。WaveSpeedでは、ビギナーフレンドリーなフロー(クリアなデフォルト、高速反復、アイデンティティとテクスチャを安定させるための十分な制御)でZ-Image LoRAを実行するため、リトライに費やす時間を減らし、実際に画像を作成するのに費やす時間が増えます。
→ WaveSpeedで簡単なLoRAを訓練します
 自分のために保ちおくメモ:プロンプトで戦う単語が少ないほど、目の前の画像に対する注意が増えます。それは自動化したくない部分です。
自分のために保ちおくメモ:プロンプトで戦う単語が少ないほど、目の前の画像に対する注意が増えます。それは自動化したくない部分です。
関連記事

Seedance 2.0がWaveSpeedAIに登場予定:ネイティブ音声対応のバイトダンス次世代ビデオモデル

Seedance 2.0完全ガイド:マルチモーダルビデオクリエーション

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1:究極のAIビデオ生成モデル比較

Seedream 5.0-Preview完全ガイド:インテリジェント画像生成

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: 完全比較
