DeepSeek V4 vs Claude Opus 4.5 コーディング比較:ベンチマーク分析

Let me provide you with the Japanese translation:
やあ、Doraです。先週の日曜日の朝、エディタとチャットウィンドウを行き来して不安定なテストにパッチを当てていたら、モデルが存在しないインポートを作り続けていました。大したことではありませんが、手作業を遅くするそういった細かい問題の一つです。モデルを切り替えることで、実際の時間だけでなく、リポジトリに着地するものを信頼するのに必要な精神的努力を軽くできるかどうか知りたかったのです。
そこで先週(2026年1月27日~2月1日)、シンプルで反復可能なループを実行してみました:同じタスク、同じリポジトリスナップショット、DeepSeek V4とClaude Opus 4.5を交互に使うという方法です。これはラボでの研究ではありません。モデルをCIに組み込む前に自分で確認するような検証です。あなたもコーディング用にDeepSeek V4 vs Claude Opus 4.5を検討しているなら、これらのノートは切り替える前に読みたいものになると思います。

現在のベンチマーク首位モデル
SWE-bench Verifiedのランキング
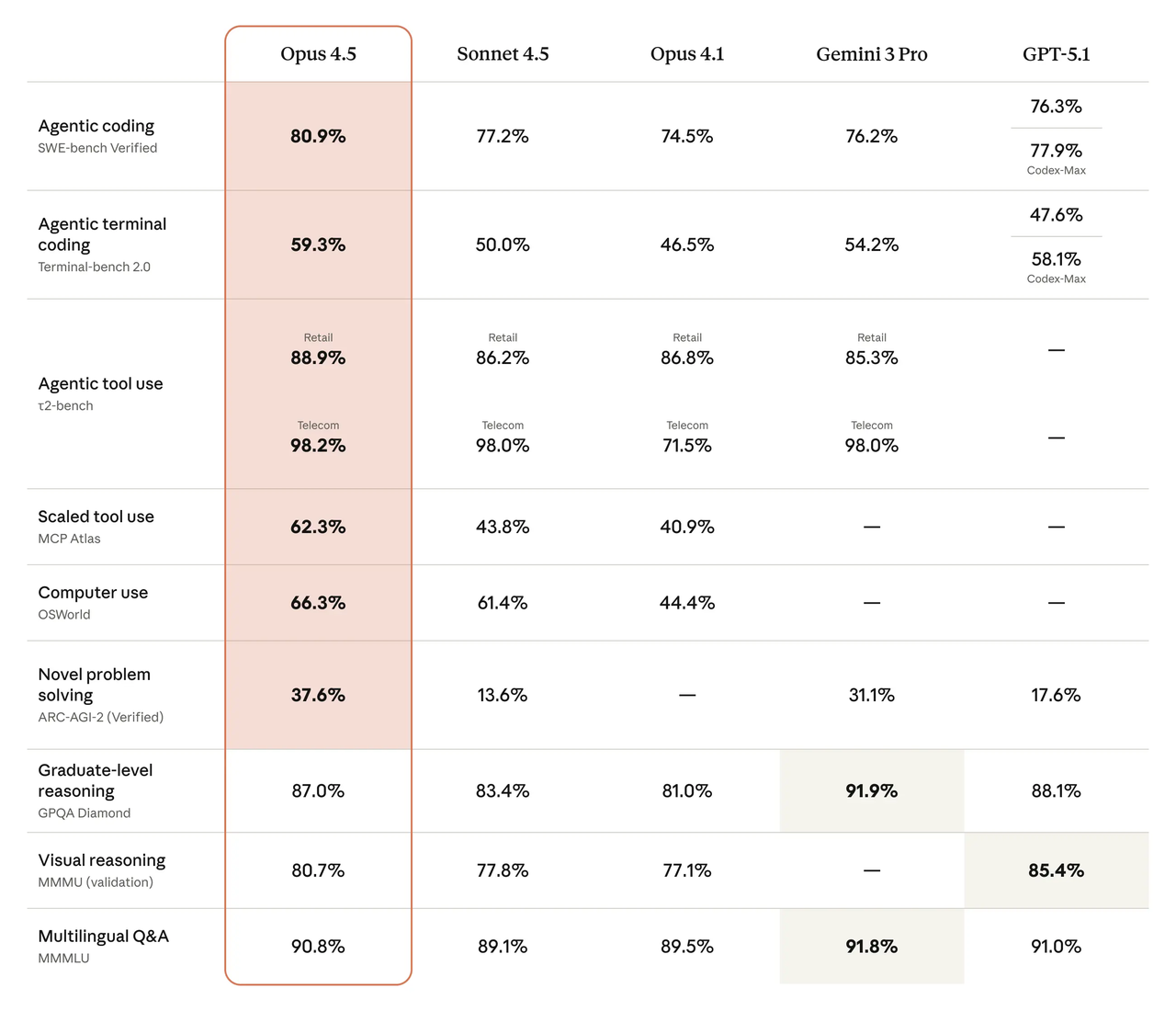
風がどこに吹いているのか素早く把握する必要があるときは、公開リーダーボードから始めます。SWE-bench Verifiedリーダーボードでは、DeepSeekの最近のモデルとAnthropicの新しいClaudeファミリーの両方が上位にいて、プロンプト、ツール、評価方法が変わるにつれて週ごとに小さな差が変わります。私にとって重要なのは単一の数字ではなく、パターンです:どのモデルがツールへの依存なしに一貫して端から端までの問題を解くか、そしてプロンプト調整にどのくらい敏感であるかです。
2026年2月初旬時点での私の簡潔な見解:
- DeepSeek V4は、必要とするすべてのコンテキストを与えたときに、マルチファイル、リポジトリスケールのタスクで強い動きを見せます。長いプロンプトと明確なファイルマップから恩恵を受けます。
- Claude Opus 4.5は安定した結果を提供し、コンテキストを削減するかシステムメッセージを削除すると回帰する傾向が少ない傾向があります。派手ではありませんが、下限は高いように感じます。
HumanEvalスコア
HumanEvalはより狭く、ユニットテスト付きの短いコーディング問題ですが、すぐに使えるコード生成の有用な匂いテストです。OpenAI HumanEvalリポジトリと、EvalPlusリーダーボードのようなコミュニティトラッカーの現在のサマリーは、両方のモデルをトップティアに配置しています。ここで正確なpass@1に固定しません:言語トリックに頼るのではなく、直接的で慣用的なコードを書くモデルがシードにわたってどのくらい安定しているかと、どのくらい頻繁に言語トリックに頼るかを監視します。
私の実行では、DeepSeek V4はより長く、より「説明的な」解決策を生成することがありますが、それは細かいdiffで私が望むものではありません。Claude Opus 4.5はより頻繁にコンパクトな関数を返し、余計なコメントなくテストを通過しました。ベンチマークはこの違いを示唆しています:実際の作業でそれが明らかになりました。
各モデルが優れている場所
ロングコンテキスト(DeepSeek)
このセットアップを端から端まで再現したい場合は、短いDeepSeek V4クイックスタートガイドをまとめました。ここで頼っているチャットとAPIの基礎を説明しています。
両方のモデルに実際のタスクを与えました:静かに絡み合いに成長していた小さなFastAPIサービスをリファクタリングします。約14のファイルが関係し、さらにREADMEがありました…楽観的でした。リポジトリスナップショットをzipして、ファイルサマリーと簡単なスクリプトで生成した呼び出しグラフを与えました。DeepSeek V4は蔓延に冷静でした。クロスファイル効果を追跡し、段階的な計画を求めたときにパニックになりませんでした:インターフェース最初、テスト二番目、ハンドラー最後。驚くべき部分は、構造的なヒントをどのくらいよく使ったかです。ファイル名と責任の簡単な「マップ」を与えたとき、存在しないファイルに対する編集を提案するのを止めました。
2つの実用的なノート:
- 余裕が必要でした。コンテキストを積極的に削減しすぎたとき、それは慎重になり、すでに提供していたファイルを見るように頼み始めました。完全な絵を与えたとき、それはきれいに動きました。
- 「何が足りていないのか?」というプロンプトにうまく対応しました。テストスイートに基づいてエッジケースを求めると、忘れていた3つを表面化させました:空の認証ヘッダー、壊れたページネーションパラメータ、エラーログの遅い経路です。
これは最初は時間を節約しませんでした。初期セットアップ、パッケージコンテキスト、短いファイルマップの作成には約20分かかりました。しかし数回実行した後、精神的負荷は低下しました。「これを伝えたか?」という心配が少なくなりました。コーディングの日が複数のモジュールに広がる大きなdiffのようなら、DeepSeek V4はコンテキストが広いときに安定した手を持っています。
コード信頼性(Claude)

Claude Opus 4.5は異なる方法で私を勝たせました:より少ない鋭い端。最小パッチを求めたとき、それはそれを与えました。3段階の計画とドライランを求めたとき、コマンドを幻覚しませんでした。そして頼みもしないことを「改善」する衝動に抵抗しました。
小さな例:タイムゾーン算数の周りに不安定なテストがありました。私のプロンプトは率直でした:「本番コードを変更せずにテストを修正し、ルート原因を1文で説明してください。」Claudeはtzフィクスチャをパラメータ化し、単一のアサーションを調整して認識されたdatetimeを使うことを提案しました。初回で合格しました。DeepSeekもそれを修正しましたが、同じ呼吸でヘルパーをリファクタリングしようとしました。間違いではありませんが、望んでいたより重かったのです。
5つのタスクにわたって、Claudeのdiffは一貫してより小さかったのです。どこからともなく現れるインポートが少ないのです。そして推測したとき、それはきれいなメモを残しました:「pytzが利用可能であると仮定:そうでなければ、zinfoinfo で置き換えます。」そういった慎重な提案は監査が簡単です。
2つの制限が現れました:
- Claudeはパフォーマンスで安全に遊びました。1つのケースでは、DeepSeekがすぐに指摘した簡単なO(n)改善より明確さを選びました。私は肘でそれを突いた:「同じ制約の下で最適化します。」それはしましたが、最初に飛び込みません。
- 非常に長いプロンプトで、私はより速く天井に当たりました。サマリーは助けになりましたが、DeepSeekはモデルが「アプリ全体を心に留める」ことを望んだとき、より窮屈に感じません。
あなたの日が主に外科手術用パッチ、テスト修復、API周辺のグルーコードなら、Claude Opus 4.5は変更を痩せて予測可能に保ちます。実際には、信頼性を感じることができます。
自分で比較を実行する方法
コーディング用にDeepSeek V4 vs Claude Opus 4.5を迷っているなら、短く退屈な実験はどのリーダーボードよりもあなたに多くを伝えます。私が使ったループがここにあり、自由に調整してください。
1. あなたの週を反響するタスクを選ぶ
- 1つのリポチョア(リファクタリングまたはモジュール抽出)
- 1つの不安定なテスト
- 1つのAPI統合変更
- 1つの小さなアルゴリズムの微調整
それぞれを45分以下に保ちます。相互作用をタイムボックス化し、モデルの生成だけではありません。
2. 入力をフリーズする
- 特定のコミットをピンします。テスト中にターゲットを移動しないでください。
- モデルが何を見ることができるかを決定:完全なファイルまたは抜粋。抜粋を渡す場合は、短いファイルマップを作成します。
- 両方のモデルに同じシステムプロンプトスタイルを使用します。私はそれをシンプルに保ちます:「あなたは役立つコーディングアシスタントです。最小限のdiffと実行可能なコードを優先します。」
3. 再利用できるプロンプトを作成する
- タスク:「目標、制約、テストをここに示します。」
- コンテキスト:ファイルリストまたはサマリー、既知の落とし穴。
- 出力形式:「計画を提案(箇条書き)、その後diff、その後1文のリスク注記。」
4. 両方で同じシグナルをキャプチャする
- テストに合格するまでの試み(1~N)
- diffの行変更(大まかでいい)
- モデルのために書く必要があったノート(「Xの編集を停止」、「既存のヘルパーY を使用」)
- 最初の緑色のテストへの時間
5. 漏出を防ぐ
- 比較をツール使用する計画がない限り、ツールを無効にします。1つのモデルが出殻し、もう1つはそうしない場合、同じことをテストしていません。
- 取得を許可する場合は、両方を同じドックススナップショットにポイントします。
6. ベンチマークで正気チェック、崇拝しないでください
- SWE-bench Verifiedに一目を通して、あなたの結果が野生的に外れているかどうかを確認します。そうであれば、モデルを責める前にプロンプトを確認してください。
- バイトサイズの問題については、公式リポジトリのHumanEvalサンプルをスキムするか、ローカルでいくつか実行します。単一実行よりも複数のシード上の一貫性がより明らかです。
7. オプション:小さなルーブリックを追加
1~5でスコア:
- Diff最小主義(必要なもののみに触れたか?)
- フィクスチャ規律(テスト、環境、依存関係)
- リカバリー動作(ミスを指摘すると自己修正されるか?)
- 説明の品質(1つまたは2つの明確な文、ブログポストではなく)
実際に見守ること
- モデルは最初に制約を尊重しますか?
- 間違っているとき、見つけやすい方法で間違っていますか?
- コンテキストスイッチしている間、パッチを提案してもらっても安全だと感じますか?
これは私にとってうまくいきました、あなたの走行距離は異なるかもしれません。ポイントは勝者を決めることではなく、どちらがあなたのコード、あなたのスケジュールで認識負荷を減らすかを見ることです。
関連記事

Seedance 2.0がWaveSpeedAIに登場予定:ネイティブ音声対応のバイトダンス次世代ビデオモデル

Seedance 2.0完全ガイド:マルチモーダルビデオクリエーション

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1:究極のAIビデオ生成モデル比較

Seedream 5.0-Preview完全ガイド:インテリジェント画像生成

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: 完全比較
