Z-Image LoRA: Apa Artinya dan Kapan Anda Membutuhkannya (Ramah Pemula)

Hi, teman-temanku. Dora di sini. Minggu lalu saya tidak merencanakan untuk melatih apa pun. Saya hanya ingin pembantu kecil yang konsisten, karakter bergambar untuk duduk di sudut screenshot saya. Prompt terus membuat saya dekat, lalu menyimpang. Alis berubah. Warna tergelincir. Pada hari Selasa (13 Januari 2026), setelah beberapa kali hampir berhasil, saya mencoba Z-Image LoRA. Saya mengharapkan lubang kelinci. Ini lebih seperti lorong pendek.
Ini bukan putaran kemenangan. Tidak instan. Tetapi setup menghilangkan cukup gesekan sehingga saya berhenti berpikir tentang pengaturan dan mulai berpikir tentang gambar saya. Berikut adalah apa yang berhasil, apa yang tidak, dan kapan Anda mungkin tidak memerlukan LoRA sama sekali.
Z-Image LoRA dalam satu menit
LoRA (Low-Rank Adaptation) adalah add-on kecil yang Anda latih di atas model gambar dasar untuk mendorongnya ke arah gaya atau subjek tertentu tanpa melatih ulang seluruh model.
 Apa yang dilakukan Z-Image LoRA (Ramah Pemula) dengan baik:
Apa yang dilakukan Z-Image LoRA (Ramah Pemula) dengan baik:
- Menyembunyikan tombol yang menakutkan. Anda masih memilih beberapa dasar (gambar, keterangan, target), tetapi defaultnya masuk akal.
- Melatih cukup cepat untuk diiterasi. Lintasan pertama saya (10 gambar) memakan waktu sekitar 12–18 menit di GPU kelas menengah.
- Dimuat seperti lapisan. Anda mengalihkannya dalam alat pembuatan Anda dan prompt seperti biasa, ditambah kata pemicu opsional.
Apa yang Anda dapatkan: file kecil yang mendorong model saat Anda membutuhkan konsistensi, logo, karakter, tampilan cat air yang berani, tanpa mengunci Anda. Jika Anda tidak mengalihkannya, model dasar berperilaku seperti biasa.
Kapan Anda TIDAK memerlukan LoRA
Saya mengatakan ini dengan kasih sayang: banyak dari kita mencapai pelatihan terlalu cepat. Beberapa kasus di mana saya tidak repot:
- Model dasarnya sudah dekat. Jika prompt pendek dengan gambar referensi memberi Anda hasil 8/10 yang dapat Anda gunakan, selesai. IP-Adapter atau prompt gambar mungkin cukup.
- Anda membutuhkan variasi, bukan konsistensi. Jika setiap output harus berkelana, LoRA dapat over-steer.
- Visual sekali jadi. Untuk banner tunggal, saya akan menghabiskan lima menit ekstra prompt daripada menyiapkan pelatihan.
- Batasan hidup dalam komposisi, bukan identitas. Alat seperti ControlNet atau panduan pose membentuk tata letak tanpa mengajarkan model konsep baru.
Tes cepat yang saya gunakan: jika sapuan benih sederhana dan 2–3 penyesuaian prompt tidak dapat mempertahankan elemen yang saya pedulikan (karakter yang sama, proporsi logo yang sama) di lima gambar, itulah saat saya mempertimbangkan LoRA. Jika tidak, saya tetap sederhana.
Kapan LoRA membantu
Saya merasakan perbedaannya paling banyak dalam dua situasi minggu ini (Januari 2026):
- Maskot kecil yang ingin saya gunakan kembali di seluruh dokumen. Prompt terus goyah mata dan warna kemeja. Setelah LoRA singkat, mereka stabil, dan saya dapat fokus pada pose dan latar belakang.
- Tekstur pensil lembut untuk diagram. Saya bisa prompt “sketsa pensil,” tetapi bayangan berubah setiap kali. LoRA gaya 15 gambar memberi saya kualitas garis yang stabil tanpa membatasi konten.
Sinyal bahwa LoRA mungkin akan membantu:
- Anda memerlukan subjek yang sama di banyak adegan.
- Tekstur seni khusus penting (crosshatch, titik risograph, tepi gouache tebal) dan terus menyimpang.
- Anda ingin mengurangi gymnastics prompt. Setelah pelatihan, prompt saya turun dari 80–100 token menjadi 30–40. Upaya mental turun lebih dari waktu.
Apa yang mengejutkan saya adalah dampaknya terasa tenang. Tidak ada sebelum/sesudah dramatis. Hanya lebih sedikit pengulangan, lebih sedikit “hampir.”
Persyaratan data
 Saya menyederhanakan ini dan berhasil lebih baik dari yang saya harapkan. Beberapa catatan dari dua lari singkat minggu lalu:
Saya menyederhanakan ini dan berhasil lebih baik dari yang saya harapkan. Beberapa catatan dari dua lari singkat minggu lalu:
Kuantitas
- Karakter/subjek: 8–20 gambar dapat cukup jika bervariasi (sudut, pencahayaan, perubahan pakaian ringan). Saya menggunakan 12.
- Gaya/tekstur: 10–30 gambar yang berbagi tampilan yang sama tetapi konten berbeda. Saya menggunakan 15.
Kualitas
- Resolusi: berikan gambar yang kira-kira sesuai dengan ukuran generasi Anda. Jika Anda berencana membuat di 1024, jangan latih pada potongan 256 kecil.
- Varietas mengalahkan volume: Lima salinan pose yang sama mengajarkan model sangat sedikit dan mendorongnya ke overfitting.
- Latar belakang bersih membantu karakter: Adegan sibuk mengaburkan sinyal.
Keterangan
- Singkat dan harfiah: “maskot biru kecil dengan mata bulat, kemeja merah,” “sketsa pensil, crosshatch, bayangan lembut.”
- Konsisten dengan penamaan. Jika Anda membuat nama unik untuk karakter (seperti “mori-kiko”), gunakan dalam setiap keterangan sehingga Anda dapat memicunya nanti.
- Anda dapat mulai dengan keterangan otomatis, kemudian membersihkannya sedikit. Saya memotong sifat yang tidak mencerminkan ide inti.
Proses yang saya gunakan
- 12 foto subjek (depan/tiga perempat/samping), latar belakang netral.
- 15 frame gaya dari diagram saya sendiri, tekstur kertas yang sama.
- Satu lintasan, rank default, regularisasi ringan. Waktu pelatihan: ~16 menit di A10G yang disewa. Setup: ~10 menit. Lintasan kedua menggunakan 20% lebih sedikit langkah dan tetap tahan.
Jika Anda hanya mengingat satu hal: gambar lebih sedikit dan lebih jelas mengalahkan folder besar dan berisik.
LoRA Gaya vs Karakter
Saya dulu mengelompokkan ini bersama-sama. Mereka berperilaku berbeda.
LoRA Karakter/Subjek
- Tujuan: mengajarkan identitas tertentu (orang, maskot, produk).
- Data: subjek konsisten, konteks bervariasi: close-up wajah jika identitas wajah penting.
- Prompt: pertahankan nama pemicu ditambah deskripsi singkat. Biarkan LoRA menangani identitas: Anda mengarahkan pose/adegan.
- Risiko: overfitting pada pakaian atau latar belakang. Campurkan.
LoRA Gaya/Tekstur
- Tujuan: mengajarkan kualitas permukaan (garis kerja, palet, goresan kuas, butir).
- Data: banyak subjek berbeda, satu gaya.
- Prompt: tidak perlu nama pemicu, tetapi penanda sederhana membantu (“gaya sketchline”).
- Risiko: gaya menelan konten. Jika semuanya menjadi lukisan bergumul yang sama, kurangi kekuatan.
Kekuatan dan pencampuran
- Sebagian besar alat mengekspos bobot LoRA. Saya jarang naik di atas 0,8 untuk karakter atau 0,6 untuk gaya. Dorongan kecil penting.
- Anda dapat menumpuk dua LoRA (satu gaya, satu karakter). Saya mendapat hasil terbaik ketika salah satu dominan dan yang lain tetap di bawah 0,4.
Saya belajar menganggap LoRA karakter sebagai “siapa” dan LoRA gaya sebagai “bagaimana.” Sederhana, tetapi itu membuat saya tidak menyalahkan hal yang salah.
Mitos umum
Beberapa klaim yang saya temui banyak, dan apa yang sebenarnya saya lihat:
- “Anda memerlukan ratusan gambar.” Saya melatih karakter yang dapat digunakan dengan 12. Lebih banyak membantu, tetapi hanya jika bervariasi dan bersih.
- “Butuh waktu berjam-jam.” Dengan GPU sederhana dan preset pemula, lintasan saya mendarat di bawah 20 menit. Konfigurasi berat dan kustom dapat memakan waktu lebih lama.
- “LoRA menggantikan rekayasa prompt.” Ini mengurangi fiddling tetapi tidak menghilangkannya. Saya masih prompt untuk komposisi, pencahayaan, dan suasana hati.
- “Satu LoRA cocok untuk semua model.” Tidak selalu. LoRA yang dilatih pada satu basis dapat mentransfer dengan baik ke model saudara, tetapi hasilnya bergeser. Saya menganggapnya terkait, bukan dapat dipertukarkan.
- “Kekuatan lebih tinggi = lebih baik.” Melewati suatu titik, gambar runtuh menjadi kesamaan. Jika detail smear, turunkan bobot.
- “Keterangan otomatis baik-baik saja tanpa diedit.” Mereka permulaan yang baik. Saya masih memangkas sifat aneh (“ominous,” “cinematic”) yang bukan bagian dari konsep.
Tidak ada yang ajaib di sini. Ini adalah tweak kecil, berulang yang majemuk.
Glosarium cepat
- LoRA: Serangkaian update bobot yang dipelajari yang ringkas yang mengadaptasi model besar ke arah konsep target tanpa melatih ulang semuanya. Menurut dokumentasi LoRA IBM, dapat mengurangi parameter yang dapat dilatih hingga 10.000 kali dibandingkan dengan fine-tuning penuh.
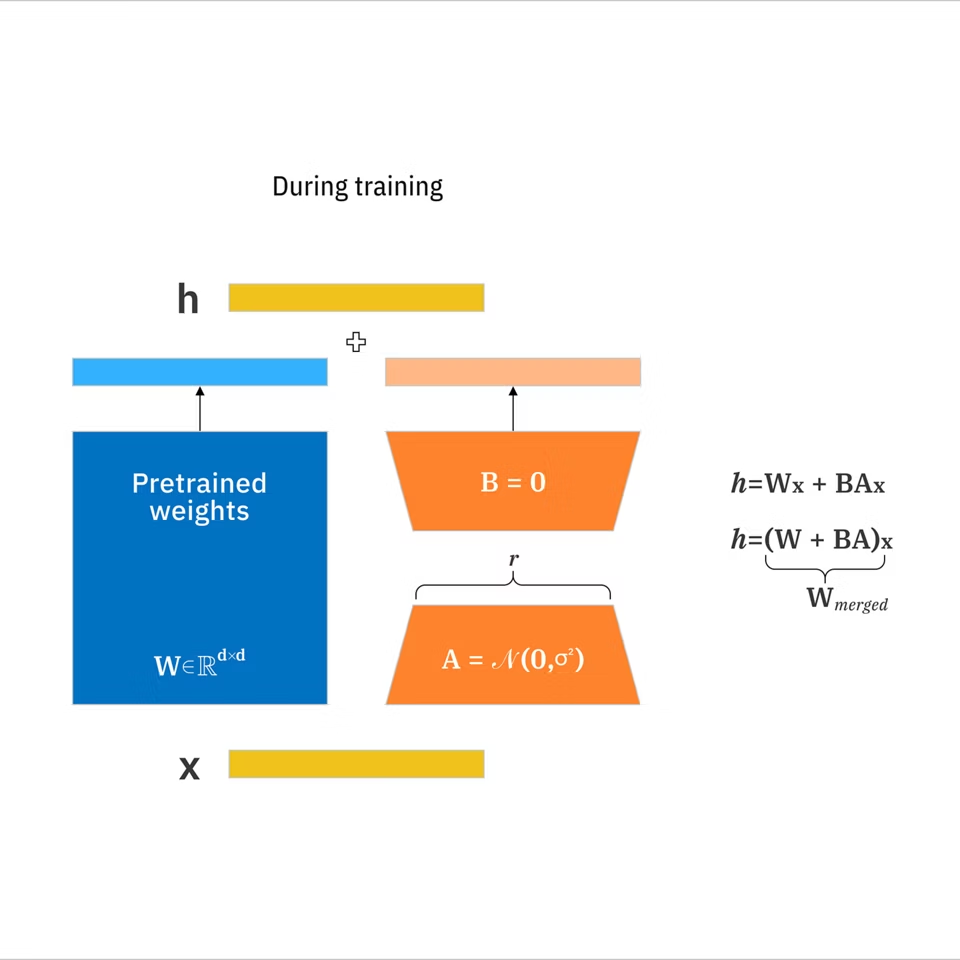
- Model dasar: Yayasan yang Anda buat darinya (apa yang Anda muat sebelum LoRA apa pun).
- Rank (r): Pengaturan yang mengontrol seberapa ekspresif LoRA. Rank lebih tinggi dapat menangkap lebih banyak nuansa tetapi mungkin overfitting dan menggelembungkan ukuran.
- Bobot/Kekuatan: Seberapa kuat LoRA mempengaruhi generasi pada waktu inferensi.
- Kata pemicu: Token unik yang Anda gunakan dalam prompt untuk memanggil LoRA subjek (misalnya, nama buatan yang Anda gunakan dalam keterangan).
- Overfitting: Ketika model menghafal gambar pelatihan dan berhenti menggeneralisasi. Muncul sebagai near-duplicates.
- Regularisasi: Teknik atau data tambahan untuk mencegah overfitting.
- UNet/Encoder teks: Bagian dari model yang menangani gambar dan teks. Beberapa pelatihan memperbarui keduanya: preset pemula sering menyentuh sisi gambar lebih banyak.
- Keterangan: Teks yang dipasangkan dengan setiap gambar pelatihan.
- Checkpoint: Status yang disimpan dari model atau LoRA.
Jika ada yang terasa berkabut, Anda masih bisa melatih. Preset pemula dirancang untuk membuat Anda tetap keluar dari masalah.
Langkah berikutnya di WaveSpeed
Saya menggunakan jalur yang ramah pemula di WaveSpeed untuk menjalankan Z-Image LoRA tanpa mengejar pengaturan. Alurnya tenang:
- Pilih model dasar.
- Masukkan 8–20 gambar dan keterangan pendek.
- Pilih “gaya” atau “karakter.”
- Mulai pelatihan dan buat teh.
- Muat LoRA untuk generasi dan coba dua bobot (0,4 dan 0,8) untuk merasakan jangkauannya.
Apa yang paling membantu adalah memperlakukan lintasan pertama sebagai sketsa. Saya mencari dua hal: apakah identitas bertahan di lima prompt, dan apakah gaya mempertahankan teksturnya tanpa menelan konten? Jika satu gagal, saya menyesuaikan dataset, bukan hanya slider.
Jika Anda berurusan dengan batasan yang sama, karakter yang menyimpang, tekstur yang goyah, nilai untuk dilihat. Ini berhasil untuk saya: hasil Anda mungkin berbeda.
Ini persis mengapa kami membangun WaveSpeed. Ketika karakter menyimpang, gaya goyah, dan prompt berubah menjadi gymnastics, kami ingin cara yang lebih tenang untuk mendapatkan konsistensi tanpa over-engineering. Di WaveSpeed, kami menjalankan Z-Image LoRA dengan alur yang ramah pemula—default yang jelas, iterasi cepat, dan kontrol yang cukup untuk menjaga identitas dan tekstur stabil, sehingga Anda dapat menghabiskan lebih sedikit waktu untuk mencoba ulang dan lebih banyak waktu untuk membuat gambar.
→ Latih LoRA sederhana di WaveSpeed
 Catatan kecil yang saya simpan untuk diri saya sendiri: semakin sedikit kata yang saya perjuangkan dalam prompt, semakin banyak perhatian yang saya miliki untuk gambar di depan saya. Itu adalah bagian yang tidak ingin saya otomatisasi.
Catatan kecil yang saya simpan untuk diri saya sendiri: semakin sedikit kata yang saya perjuangkan dalam prompt, semakin banyak perhatian yang saya miliki untuk gambar di depan saya. Itu adalah bagian yang tidak ingin saya otomatisasi.
Artikel Terkait

Seedance 2.0 Segera Hadir: Model Video Generasi Berikutnya ByteDance dengan Audio Asli

Panduan Lengkap Seedance 2.0: Pembuatan Video Multimodal

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: Perbandingan Generasi Video AI Terlengkap

Panduan Lengkap Seedream 5.0-Preview: Generasi Gambar Cerdas

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Perbandingan Lengkap
