Train Z-Image Turbo LoRA di WaveSpeed: Dataset, Langkah, dan Kesalahan Umum

Hei, teman. Aku Dora.
Minggu lalu, aku ingin gaya yang kecil dan konsisten untuk sekumpulan gambar header. Stok terasa salah, dan fine-tuning prompt terus bergeser. Jadi aku mencoba sesuatu yang telah aku hindari: LoRA cepat LoRA pada Z-Image Turbo di dalam WaveSpeed. Aku mengharapkan pengaturan yang merepotkan dan banyak trial-and-error. Yang aku dapatkan lebih sederhana dari yang aku pikir, tidak mudah, hanya rapi.
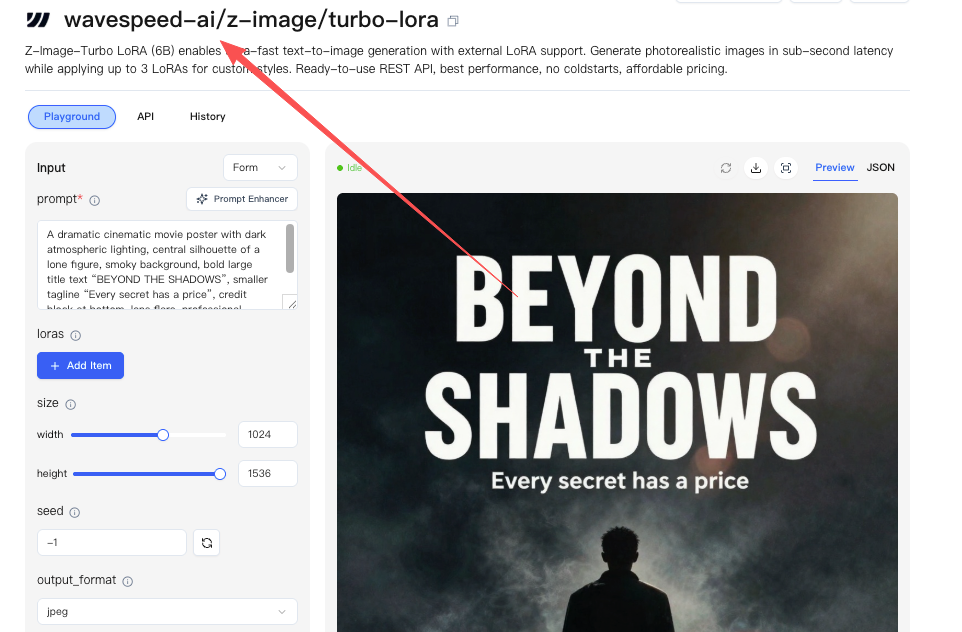
Ini adalah cara aku melatih Z-Image Turbo LoRA di WaveSpeed selama dua malam di Januari 2026, apa yang berhasil, apa yang tidak, dan pengaturan yang akan aku gunakan kembali. Ini bukan panduan untuk meraih setiap persen terakhir. Ini adalah baseline yang stabil yang membuat pikiranku tetap jernih dan hasilnya dapat diprediksi.
Aturan dataset
Apa yang aku kumpulkan
Aku membuatnya tetap kecil: 45 gambar untuk gaya visual yang terdefinisi (redup, garis bersih, tekstur kertas lembut). Aku telah memiliki hasil yang baik antara 30–120 gambar. Di bawah 20 cenderung overfit: lebih dari 150 Anda melatih lebih banyak fine-tune daripada LoRA, dan keuntungan kecepatan Z-Image Turbo mulai merata.
Keragaman mengalahkan kuantitas
Aku membagi set:
- 70% gambar “core look” (gaya yang ingin aku ajarkan),
- 30% konteks keragaman (objek/latar belakang berbeda sehingga LoRA tidak mengikat gaya ke satu adegan).
Sudut, pencahayaan, dan rasio aspek bervariasi. Aku menghindari duplikat mendekati (tidak ada tiga shot objek yang sama dari pergeseran 5°).
Ukuran dan format
- Resolusi: 768px di sisi pendek. Model Turbo menangani 1024, tetapi 768 membuat pelatihan lebih ringan dan mengurangi artefak dalam tes aku.
- Format: PNG atau JPEG berkualitas tinggi. Aku menghapus metadata. Profil tertanam besar kadang-kadang membingungkan warna sedikit.
- Cropping: Aku memotong untuk menjaga subjek dominan tetapi tidak berpusat setiap saat. Simetri membuat model menjadi malas.
Tips captioning
Aku mencoba dua pass: auto-tagging terlebih dahulu, lalu edit ringan. Caption otomatis membawaku 70% ke sana. 30% terakhir penting.
Jaga caption singkat dan konsisten
- 1–2 kalimat atau daftar tag yang kompak.
- Sebutkan token gaya (lebih banyak tentang token di bawah) ditambah kata kelas.
- Jangan jelaskan semuanya. Hanya namakan apa yang stabil dan penting.
Contoh yang aku gunakan:
- “soka-style, minimalist illustration of a ceramic mug on a desk, soft paper texture, muted palette.”
- “soka-style, simple plant in a clay pot, side light, clean negative space.”
Kata kelas membantu
Jika Anda mengajarkan gaya, gunakan kata kelas (illustration, photo, portrait, product shot). Jika Anda mengajarkan objek/karakter, gunakan apa itu (mug, backpack, planner). Ini membantu LoRA untuk generalisasi. Tanpa kata kelas, run awal aku membuat LoRA menempel pada tata letak.
Jangan overfit dengan adjektif
Aku menghapus adjektif berulang setelah pass kedua. Jika setiap caption mengatakan “warm, cozy, soft,” model mengunci pada vibe itu bahkan ketika Anda tidak menginginkannya. Aku menyimpan satu adjektif untuk tone.
Sinyal negatif
Aku menambahkan negatif ringan dalam beberapa caption di mana itu benar-benar penting: “no harsh shadows.” Tidak di mana-mana, hanya di mana kontras salah dalam gambar mentah. Terlalu banyak negatif membuatnya keras kepala selama inference.
Catatan kecil: Aku mencoba caption-free untuk lima gambar sebagai tes. Hasilnya menjadi sedikit lebih berisik. Tidak mengerikan, tetapi aku tidak akan melewatkan caption jika konsistensi penting.
Baseline parameter pelatihan
Ini adalah pengaturan yang memberi aku hasil yang stabil di WaveSpeed dengan Z-Image Turbo. Aku menjalankan tiga pelatihan singkat (sekitar 18–22 menit masing-masing pada GPU default di workspace aku). Waktu Anda mungkin berbeda.
Pengaturan inti yang aku gunakan kembali
- Base: Z-Image Turbo (terbaru per Januari 2026)
- LoRA rank (dim): 16 untuk gaya halus: 32 ketika gaya membutuhkan lebih banyak pukulan. Aku menetap di 16.
- Alpha: match rank (16) atau setengah (8). Aku menyamakannya.
- Learning rate: 1e-4 untuk memulai. 2e-4 jika gaya tidak menempel. 1e-3 terlalu matang cepat dalam tes aku. Dokumentasi pelatihan LoRA Hugging Face merekomendasikan memulai dengan 1e-4 untuk sebagian besar model stable diffusion.

- Batch size: 2–4. Aku menggunakan 4 untuk menjaga langkah masuk akal.
- Epochs/steps: Targetkan 1–2 pass penuh atas data. Untuk 45 gambar × 10 repeats ÷ batch 4 ≈ 112 langkah per epoch. Aku melatih 2 epoch (≈224 langkah). Lebih dari 3 epoch mulai menghafal latar belakang.
- Scheduler: Cosine atau constant dengan warmup. Aku menggunakan cosine dengan 5% warmup.
- Precision: bfloat16 ketika tersedia. Itu baik di sini.
Gambar regularisasi
Dengan LoRA gaya, aku tidak selalu menambahkan regularisasi. Untuk objek atau karakter, aku menambahkan 50–100 gambar kelas (plain “mug,” “portrait”) untuk menjaga anatomi dan bentuk jujur. Di Turbo, ini secara nyata mengurangi daun seperti tangan aneh dalam bidikan tanaman.
Checkpoints dan saving
Aku mengaktifkan penyimpanan setiap 50–80 langkah. Itu membiarkan aku kembali ke tempat termanis, yang untuk set aku adalah sekitar langkah 180. Langkah-langkah selanjutnya terlihat lebih bersih tetapi kurang fleksibel dalam prompt.
Jika Anda ingin pemeriksaan kewarasan cepat: lakukan run 60–90 langkah terlebih dahulu. Itu tidak akan sempurna, tetapi itu akan memberi tahu Anda apakah dataset Anda mengajarkan pelajaran yang benar.
Kata pemicu
Aku menggunakan token unik untuk menahan gaya: “soka-style”. Anda bisa menggunakan sesuatu seperti “kavli-ark” atau “mivva”. Singkat, diciptakan, dan tidak mungkin bertabrakan dengan kata-kata nyata.
Cara aku menulis caption
- Mulai caption dengan token sekali: “soka-style, minimalist illustration …”
- Tambahkan kata kelas: illustration, photo, render, apa pun yang cocok.
- Jaga konsistensi di seluruh dataset.
Cara aku mempromosikan
- Positif: “a product photo of a ceramic mug on a wooden desk, soka-style, soft paper texture, muted colors”
- Negatif: “harsh shadows, heavy grain, text watermark, chromatic aberration”
Kapan menghindari kata pemicu
Jika Anda melatih objek yang sangat spesifik (botol merek, maskot), gunakan token + kata kelas (“mivva-bottle”) dalam caption, tetapi Anda tidak harus memaksa token ke dalam setiap prompt inference. Dalam tes aku, Turbo menghormati distribusi pelatihan: kadang-kadang kata kelas saja sudah cukup. Token membantu ketika adegan menjadi kompleks.
Satu keanehan: menumpuk dua token gaya membingungkan model (“soka-style, nova-style”). Aku mendapatkan campuran keruh. Satu token sekaligus lebih bersih.
Gambar validasi
Validasi menyelamatkan aku dari mengejar hantu.
Seed tetap dan grid kecil
Aku menetapkan tiga prompt yang aku pedulikan dan menjaganya tetap fixed di seluruh run:
- “a ceramic mug on a desk, soka-style, soft paper texture, muted colors”
- “a leafy plant by a window, soka-style, side light, clean background”
- “a planner and pen, soka-style, top-down, gentle shadows”
- Seed: fixed (Aku menggunakan 12345). Satu seed per prompt.
- Steps: 20–28 untuk Turbo. Melampaui 30 mulai mengasah berlebihan.
- CFG: 3.5–6. Aku suka 4.5 untuk keseimbangan.
- Sampler: DPM++ 2M Karras atau varian Euler yang layak. Kedua-duanya berperilaku baik.
- Size: 768×768 untuk paritas dengan crop pelatihan.
Aku juga merender set yang sama sekali tanpa token untuk melihat apakah gaya terlalu dominan. Dalam run kedua aku, mug masih terlihat “papery” tanpa token, petunjuk aku mendorong gaya terlalu keras. Mengurangi bobot LoRA menjadi 0.6 memperbaikinya.
Jika Anda bisa, jaga panel validasi yang ringan terbuka saat pelatihan. Menonton tiga prompt yang sama memperbarui lebih tenang daripada mengintip sampel acak.
Perbaikan
Inilah apa yang salah dan apa yang memperbaikinya.
Overfit latar belakang
- Gejala: tekstur kertas yang identik muncul dalam adegan yang tidak terkait.
- Fix: kurangi repeats per gambar (dari 10 ke 6), tambahkan 6–10 latar belakang netral, kurangi bobot LoRA pada inference (0.6–0.75).
Warna drift ke beige
- Gejala: semuanya menghangat seperti filter sore akhir.
- Fix: hapus adjektif berulang “warm/soft/cozy” dalam caption: tambahkan 6 gambar bertone lebih sejuk: atur keragaman white-balance dalam dataset: tambahkan “overly warm tones” ke negatif.
Prompt rapuh
- Gejala: perubahan prompt kecil runtuh komposisi.
- Fix: tingkatkan keragaman dataset dalam tipe objek dan tata letak: latih dengan LR sedikit lebih rendah (1e-4 alih-alih 2e-4): coba rank 32 jika gaya kompleks.
Publikasi & penggunaan kembali
Melatih LoRA ini dapat dikelola sebagian besar karena kami membangun WaveSpeed untuk menghilangkan bagian yang mengganggu dari proses. Alih-alih menghubungkan script atau mengawasi GPU, aku bisa mengunggah dataset kecil, menjalankan pelatihan Turbo LoRA singkat, membandingkan checkpoints, dan menggunakan kembali model di seluruh proyek tanpa memecahkan alur kerja aku.
Jika Anda lelah dengan style drift, overfitting, atau kehilangan jejak “run yang bagus”.
→ Latih Z-Image Turbo LoRA di WaveSpeed

Ketika run ketiga terasa stabil, aku menerbitkan LoRA di dalam WaveSpeed dengan model card polos:
- Untuk apa: gaya paper-texture halus, palet redup, bentuk bersih.
- Untuk apa bukan: portrait photoreal, produk high-gloss, overlay teks berat.
- Pengaturan yang berhasil: bobot 0.6–0.85, CFG ~4.5, 20–26 langkah, output 768.
- Dua prompt yang bagus dan satu peringatan.
- Catatan versi: dilatih Jan 2026, rank 16, LR 1e-4, ~224 langkah.
Aku menyimpan lisensi sederhana dan menambahkan tiga gambar validasi. Masa depan aku akan berterima kasih kepada masa lalu aku atas spesifikasinya.
Penggunaan kembali
- Stacking: Aku bisa menumpuk LoRA gaya ini dengan LoRA objek terpisah, tetapi aku menyimpan hanya satu gaya sekaligus. Jika Anda harus menumpuk, jaga bobot gabungan di bawah 1.0.
- Merging: Aku tidak membakarnya ke dalam checkpoint. Seluruh pointnya adalah fleksibilitas.
- Teams: Aku membagikan link LoRA dan tiga prompt validasi fixed. Ini memotong back-and-forth review. Orang-orang melihat referensi yang sama.
Jika Anda baru mengenal WaveSpeed atau Z-Image Turbo, docs resmi layak diintip sebelum run pertama Anda, terutama catatan mereka tentang learning rate dan rank. Aku menintip mereka setelah pass pertama dan berharap aku melakukannya lebih cepat.
Apakah Anda juga bersumpah seribu kali bahwa Anda hanya “akan melatih sedikit LoRA,” hanya untuk menemukan setiap gambar dua malam kemudian menampilkan “eternal beige filter” atau “forced paper texture background”?
Cepat, buang 45 gambar Anda ke WaveSpeed dan coba Z-Image Turbo LoRA. Kemudian kembali dan beri tahu aku: apakah itu menyelamatkan konsistensi header Anda, atau apakah itu membuat semua objek Anda menumbuhkan “mysterious textured tentacles”?
Artikel Terkait

Seedance 2.0 Segera Hadir: Model Video Generasi Berikutnya ByteDance dengan Audio Asli

Panduan Lengkap Seedance 2.0: Pembuatan Video Multimodal

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: Perbandingan Generasi Video AI Terlengkap

Panduan Lengkap Seedream 5.0-Preview: Generasi Gambar Cerdas

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Perbandingan Lengkap
