Qu'est-ce que TranslateGemma ? Le modèle de traduction Open AI expliqué

Salut à tous ! Je m’appelle Dora. Ce jour-là, j’éditais un bulletin d’information bilingue et je naviguais constamment entre les brouillons, les captures d’écran et les onglets Google Traduction. Rien n’était terrible. C’était juste… bruyant. Vous savez le genre. Je voulais quelque chose de discret qui puisse s’intégrer à mon flux de travail, pas à côté.
Donc plus tôt cette semaine (janvier 2026), j’ai essayé TranslateGemma. Je n’attendais pas grand-chose au départ, un autre modèle « ouvert » avec un nom brillant. Mais après quelques essais dans un notebook et puis dans un petit outil interne, j’ai remarqué quelque chose de subtil : la charge mentale a baissé. Je ne tripotais pas les onglets. Je ne surveillais pas autant la formulation. C’était comme avoir un traducteur que je pouvais garder sur mon bureau, pas de l’autre côté de la pièce.
Qu’est-ce que TranslateGemma
 TranslateGemma est une famille de modèles de traduction ouverts construits sur l’architecture Gemma de Google. En termes simples : c’est un ensemble de modèles linguistiques ajustés spécifiquement pour les tâches de traduction, avec des tailles que vous pouvez réellement exécuter localement ou adapter dans le cloud.
TranslateGemma est une famille de modèles de traduction ouverts construits sur l’architecture Gemma de Google. En termes simples : c’est un ensemble de modèles linguistiques ajustés spécifiquement pour les tâches de traduction, avec des tailles que vous pouvez réellement exécuter localement ou adapter dans le cloud.
Quelques points se sont démarqués pendant que je l’utilisais réellement :
- C’est un modèle ajusté spécifiquement pour la traduction. Vous n’avez pas à forcer un LLM général à se comporter. Les invites restent épurées.
- Il gère le contexte mieux qu’une simple API traduction phrase par phrase. Les paragraphes avec des idiomes, des noms de produits et des indices de ton légers sont passés avec moins de zones « plates ».
- C’est calme. Le résultat n’est pas tape-à-l’œil ou porté à la paraphrase. Pour les documents de travail, c’est un soulagement.
Sur le papier, TranslateGemma se situe entre les assistants complètement générateurs et les traducteurs phrase par phrase classiques. En pratique, c’est un traducteur qui respecte le sens source tout en lissant la langue cible. Quand je lui ai donné une courte note de lancement avec un mélange d’étiquettes d’interface utilisateur et de lignes conversationnelles, il a gardé les étiquettes intactes et a quand même rendu le texte naturel. C’est cet équilibre qui m’a poussé à continuer les tests.
Les licences sont dans la famille Gemma : permissives pour de nombreux usages commerciaux avec des restrictions d’IA responsable. Si vous l’intégrez dans un produit, lisez la licence dans le repo officiel ou dans l’entrée Model Garden. C’est la partie ennuyeuse, mais c’est important.
Tailles de modèles : 4B, 12B et 27B
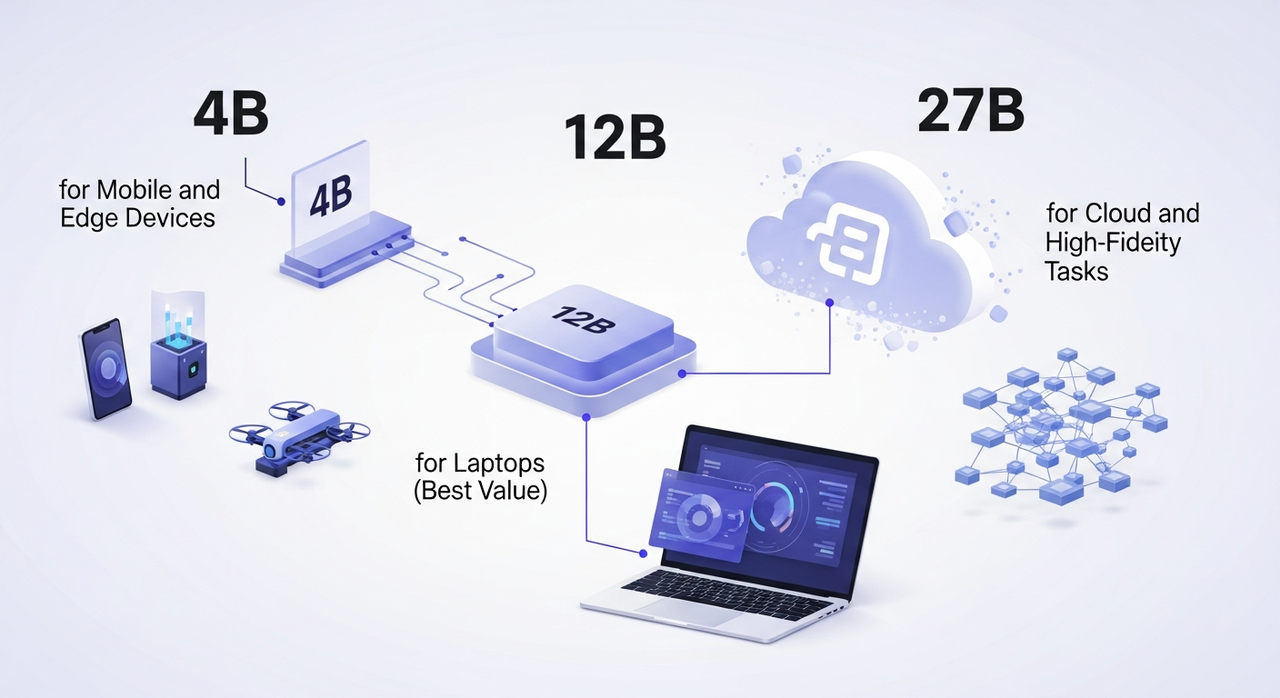 TranslateGemma existe en trois tailles. Même famille, compromis différents. J’ai exécuté de petits tests sur chacun pendant deux jours, quelques pages de produits, une séquence d’e-mails et un résumé de recherche en espagnol, français et japonais.
TranslateGemma existe en trois tailles. Même famille, compromis différents. J’ai exécuté de petits tests sur chacun pendant deux jours, quelques pages de produits, une séquence d’e-mails et un résumé de recherche en espagnol, français et japonais.
4B pour les appareils mobiles et périphériques
J’ai essayé une version 4B quantifiée sur 4 bits sur un téléphone Android récent et un Raspberry Pi 5 (juste pour voir). La latence sur le téléphone était acceptable pour les phrases courtes (moins d’une seconde par ligne), et les résultats étaient clairs pour le texte simple : chaînes d’interface utilisateur, texte d’aide, courtes légendes. Tout ce qui avait un ton complexe ou des clauses imbriquées commençait à vaciller. C’était mon signal d’arrêt.
Ce qui a fonctionné :
- Traduction sur l’appareil des chaînes d’application sans envoyer de données à un serveur.
- Brouillons rapides pour les légendes de médias sociaux dans une deuxième langue.
Les limites que j’ai rencontrées :
- Les paragraphes plus longs ont recueilli de la raideur. Il a gardé le sens, perdu la musique.
- Le texte mélangé (EN + une deuxième langue) a parfois été surré-normalisé.
Si vous avez besoin de traduction en périphérie, dans les kiosques, les applications hors ligne, les flux de travail sensibles à la confidentialité, 4B est le petit marteau qui rentre dans votre poche. Pour l’écriture quotidienne, je le traiterais comme une première passe, pas le brouillon final.
12B pour les ordinateurs portables (meilleur rapport qualité-prix)
C’est celui auquel je revenais constamment. Sur mon ordinateur portable (32 Go de RAM, GPU grand public), le modèle 12B en 4-8 bits s’exécutait confortablement avec des invites au niveau des paragraphes. Latence moyenne : 1-2 secondes pour quelques phrases, peut-être 5-8 secondes pour un paragraphe dense. C’est dans la gamme « ne pas interrompre la réflexion ».
La qualité semblait équilibrée : moins littérale que 4B, moins ornementée que les plus grands LLM qui adorent reformuler. Quand j’ai traduit une petite étude de cas du français vers l’anglais, elle a préservé la structure et reflété l’accent des phrases sans tout mélanger en un seul ton. Les noms, les termes de produits et les citations sont restés à leur place.
Où ça brille :
- Les e-mails de marketing qui ont besoin de ton mais pas de poésie.
- La documentation, les notes de version et la copie UX où la clarté bat la flourish.
- Les tâches par lot sur un ordinateur portable : 50-200 paragraphes à la fois sans facture cloud.
Où je le nudge encore :
- Les lignes quasi-poétiques (slogans, accroches) lisent parfois sûr. Une rapide passe le répare.
- Les documents très techniques peuvent devenir littéraux. Ajouter « maintenir le registre académique formel » dans l’invite a aidé.
27B pour le cloud et les tâches haute fidélité
J’ai lancé le modèle 27B sur un seul A100 dans le cloud. C’est l’option pour les équipes qui se soucient des nuances et qui peuvent justifier l’infrastructure. La latence était fine pour une utilisation interactive mais évidemment pas adaptée aux appareils mobiles.
Ce que j’ai remarqué :
- Il a conservé les indices stylistiques sur des sections plus longues. Dans le texte juridique du japonais vers l’anglais, il a maintenu la formalité sans paraître guindé.
- Il a géré les pronoms ambigus mieux. Moins de référents mal assortis entre les paragraphes.
- Pour les paires de langues peu dotées en ressources, il n’a pas fait de miracles, mais il a échoué plus gracieusement, moins de termes hallucينés.
Pour être honnête, si vous traduisez du contenu long pour la publication, ou si vous avez besoin de cohérence sur des milliers de segments, 27B justifie son fonctionnement. Pour les petites équipes, je ne m’y référerais que quand la fidélité du ton est non négociable ou quand vous avez besoin de standardiser les résultats à l’échelle.
TranslateGemma vs Google Traduction
 Je ne suis pas là pour remplacer Google Traduction à la hâte. C’est rapide, c’est partout, et pour les recherches rapides c’est toujours le chemin le plus rapide de « que signifie ceci ? » à « c’est bon ». Mais les compromis sont différents.
Je ne suis pas là pour remplacer Google Traduction à la hâte. C’est rapide, c’est partout, et pour les recherches rapides c’est toujours le chemin le plus rapide de « que signifie ceci ? » à « c’est bon ». Mais les compromis sont différents.
Où TranslateGemma semblait mieux dans mes essais :
- Fenêtres de contexte : je pouvais déposer un paragraphe entier ou deux et garder le ton et les références intacts. Google Traduction capture souvent le sens mais aplatit le style quand le contexte est désordre.
- Personnalisation : une instruction d’une ligne comme « préserver les noms de produits, garder les contractions » a façonné de manière fiable le résultat. Avec Google Traduction, vous avez ce que vous obtenez.
- Confidentialité/contrôle : exécuter localement (4B/12B) ou dans un cloud privé réduit l’exposition des données. Pas de navigation par onglets, pas d’appels externes si vous ne les voulez pas.
Où Google Traduction gagne toujours :
- Largeur et commodité : 100+ langues, accès Web instantané, OCR, entrée caméra mobile. C’est le couteau suisse.
- Vitesse à l’échelle pour un usage occasionnel : si je n’ai besoin que d’une phrase rapide, TranslateGemma est excessif à moins qu’il ne soit déjà intégré dans mon éditeur.
- Collaboration sans friction : il est facile de lier à quelqu’un une page Google Traduction et de dire « c’est proche ? »
En termes de coût, TranslateGemma change les dépenses des frais d’API par demande au calcul. Si vous avez déjà un GPU décent ou une configuration cloud modeste, cela peut être moins cher pour une utilisation soutenue. Si non, le niveau gratuit de Google Traduction est difficile à discuter.
La qualité est plus proche que je ne l’attendais. TranslateGemma était moins littéral de bonne manière, modeste, pas tape-à-l’œil. Google Traduction a amélioré la gestion du ton, mais c’est toujours comme un dictionnaire qui est allé à l’école du raffinement. Si vous écrivez pour les gens, cet écart compte.
Ma règle d’or après une semaine : je recherche toujours Google Traduction pour vérifier une ligne dans une langue que je connais à peine. Je recherche TranslateGemma quand je me soucie de comment ça sonne, pas juste ce que ça dit.
Une fois que j’ai décidé que TranslateGemma était le bon choix, la prochaine question était où l’exécuter réellement sans transformer la configuration en projet en soi.
C’est exactement pour cela que nous avons construit WaveSpeed. Notre équipe l’utilise pour lancer des environnements GPU propres, exécuter des tâches de traduction par lot et passer à autre chose — sans surveiller les pilotes, les files d’attente ou les scripts temporaires.
Où obtenir TranslateGemma
J’ai tiré les modèles des endroits habituels :
- Hugging Face : le plus facile pour les tests rapides avec Transformers ou Text Generation Inference. Cherchez « TranslateGemma » et vérifiez la carte pour la licence et les variantes quantifiées.
- Google Model Garden (Vertex AI) : déploiement géré, autoscaling, points de terminaison privés. Si votre équipe vit déjà dans GCP, c’est le chemin le plus fluide.
- Kaggle Models : pratique pour les notebooks en un clic et le benchmarking rapide si vous ne voulez pas encore câbler l’infrastructure.
- GitHub + Colab : les échafaudages communautaires apparaissent rapidement, loaders, modèles d’invite et scripts d’évaluation de base.
Notes de configuration de mon essai :
- La quantification aide. 4-8 bits ont rendu le modèle 12B confortable sur un GPU grand public sans massacrer le résultat. Je ne manquais pas les bits supplémentaires.
- Les invites restent courtes. « Traduire en anglais. Préserver les noms de produits. Garder les contractions. » C’est généralement suffisant.
- Grouper par lots avec prudence. Découpez par paragraphes ou groupes de puces. Phrase par phrase fonctionne, mais vous perdez la colle de ton.
Si vous avez besoin de garde-fous ou de contrôle du glossaire, ajoutez une étape de pré/post-traitement légère :
- Pré-marquez les noms de produits avec des balises (par ex. ) et demandez au modèle de les préserver.
- Post-vérifiez avec un outil de correspondance de glossaire pour attraper la dérive sur des termes comme « Se connecter » vs « Connexion ».
Qui je pense aimera TranslateGemma
- Les rédacteurs et les responsables du marketing qui veulent des brouillons locaux et décents sans basculer d’outils.
- Les équipes produits qui ajoutent la traduction discrètement dans une application, sans externaliser vers un autre service.
- Les chercheurs qui se soucient des paragraphes longs et des références qui restent intactes.
Qui probablement pas
- Quiconque a besoin d’une traduction instantanée par caméra en vacances, utilisez Google Traduction.
- Les équipes qui ne veulent pas gérer de calcul. Une API payante avec des SLA peut être plus calme.
Je ne m’attendais pas à la garder. Mais elle a vécu dans mon flux de travail toute la semaine parce qu’elle me demande moins : moins d’onglets, moins de rappels, moins de petites décisions. C’est généralement mon indice. Et la petite surprise ? Je lui fais confiance avec le ton d’un paragraphe, pas juste les mots. Vos résultats peuvent varier — mais si vous ressentez le bruit de trop d’outils, celui-ci reste discret. C’est pourquoi il a restéavec moi.
Articles associés

Seedance 2.0 arrive bientôt : Le modèle vidéo nouvelle génération de ByteDance avec audio natif

Guide Complet Seedance 2.0 : Création Vidéo Multimodale

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1 : La Comparaison Ultime de la Génération Vidéo

Guide Complet Seedream 5.0-Preview : Génération d'Images Intelligente

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image : Comparaison Complète
