WAN 2.5 ComfyUI Workflow: Meilleur graphe de nœuds + Paramètres pour résultats stables

Salut, copain ! Je m’appelle Dora. Ce jour-là, je créais de courtes boucles de produits pour une démo, et ma configuration habituelle n’arrêtait pas de dériver, les manches des personnages changeaient, l’arrière-plan pulsait, le mouvement vacillait sur les bords. Pas terrible, juste distrayant. Je voulais un flux de travail vidéo qui se comportait comme une main ferme, pas comme un jeu de devinettes.
J’ai passé quelques soirées ce mois-ci (janvier 2026) à faire fonctionner proprement WAN 2.5 dans ComfyUI. Rien de spectaculaire. J’ai gardé le graphique minimaliste, verrouillé quelques paramètres, et testé différentes façons de garder le mouvement stable sans perdre les parties intéressantes. Voici ce qui s’est cristallisé, et où ça n’a pas marché. Si vous cherchez « WAN 2.5 ComfyUI » parce que vous voulez quelque chose de fonctionnel, pas de la performance, c’est la version que je vous donnerais autour d’un café.
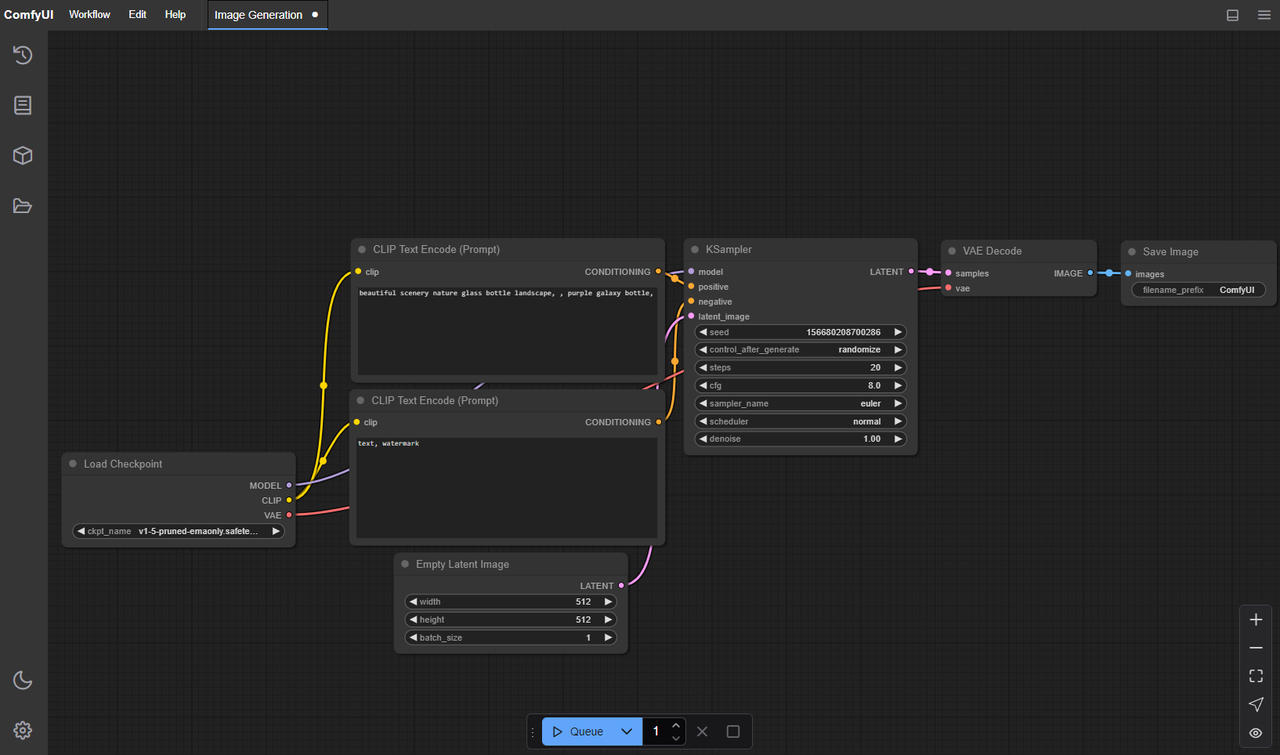
Graphique de nœuds minimaliste
J’ai d’abord essayé quelques graphiques étendus. Ils avaient l’air puissants sur le canevas et se sont avérés fragiles en pratique. La configuration la plus fiable pour WAN 2.5, du moins sur ma machine (RTX 4090, 24 Go de VRAM), était volontairement ennuyeuse.
Ce avec quoi j’ai fini :
- Chargeur de modèle pour WAN 2.5 (les poids officiels + config : chargés une fois au démarrage)
- Encodeur de texte (un prompt, un prompt négatif)
- Nœud de seed (une seule seed, pas par image)
- Sampler pour vidéo (sampler WAN ou un sampler vidéo compatible dans ComfyUI)
- VAE (décodage à la fin : pas de ré-encodage en milieu de graphique)
- Sauvegarder la vidéo
C’est tout. Pas de suréchantillonneurs supplémentaires, pas d’adaptateurs de guidance, pas de branches denoise. Pas parce que ces éléments sont mauvais, mais parce que je voulais voir ce que WAN 2.5 fait sans aide. L’avantage était clair : moins de pièces mobiles, moins de surprises. Quand quelque chose scintillait, je savais que ce n’était pas un nœud externe.
Si vous partez de zéro, j’installerais ComfyUI fraîchement, j’ajouterais ComfyUI Manager pour une gestion plus facile des nœuds, puis j’ajouterais le pack de nœuds WAN 2.5 depuis sa source officielle. Après cela, résistez à l’envie de décorer le graphique. Obtenez un clip de 3-4 secondes qui se rend proprement à une résolution modeste. Puis ajoutez de la complexité si vous en avez toujours besoin.
Paramètres de base
J’ai testé une poignée de bases et les ai augmentées ou diminuées jusqu’à ce que les clips arrêtent de vaciller.
Mon point de départ stable :
- Résolution : 896×504 (16:9). Divisible par 16, léger pour la VRAM, assez bon pour juger le mouvement.
- Durée : 48 images à 12 fps (~4 secondes). Assez long pour repérer la dérive, assez court pour itérer.
- Étapes : 28-32. En dessous de 24, le mouvement tendait à être flou : au-dessus de ~36 ne m’apportait pas grand chose.
- Guidance CFG : 4,0-6,0. Je me suis assis surtout à 5,0. Les valeurs plus élevées poussaient le style mais augmentaient le micro-scintillement.
- Sampler : Euler ou DPM++ 2M SDE (version compatible vidéo). DPM++ semblait un peu plus stable frame-à-frame.
- Force de denoise : 0,85-0,9 pour le texte vers vidéo. Si je conditionnais sur une image, je baissais à 0,7-0,8.
- Seed : fixe. Même seed dans tout le clip.
Sur la 4090, cette base de référence rendait ~4 secondes en environ 2-3 minutes. Sur une 4080 Super que j’ai empruntée pour un après-midi, c’était plus proche de 3-4 minutes. Quand je suis passé à 1024×576, le temps de rendu a grimpé ~20-30% et l’utilisation de VRAM a dépassé les 17 Go.
Petite note : si vous cherchez des fps plus élevés pour la lecture (disons 24), j’ai trouvé de meilleurs résultats en générant à 12 fps et en interpolant plus tard qu’en essayant de renderer directement à 24. Le sampler avait plus facile à rester cohérent.
Stratégie de cohérence
Garder un aspect cohérent, c’est essentiellement trois leviers : la seed, le conditionnement, et l’agressivité avec laquelle vous poussez le prompt.
Ce qui a marché pour moi :
- Verrouillez la seed et ne la touchez pas. Dans une exécution, j’ai accidentellement activé le seed par image, chaos instantané de garde-robe.
- Gardez les prompts courts. WAN 2.5 semble plus heureux avec des noms clairs et un léger indice de style qu’avec des adjectifs empilés. « Un bateau en papier sur une rue pluvieuse, lumière douce, couleurs atténuées » a mieux fonctionné qu’un paragraphe.
- Utilisez une image de référence seulement si vous en avez besoin. Le conditionnement d’image a aidé à ancrer le design du personnage (cheveux, tenue) mais a parfois sur-contraint le mouvement. Quand je l’utilisais, je baissais la force de denoise et CFG d’environ 0,5.
- Les prompts négatifs peuvent calmer le scintillement : « éclairage brutal, reflets clignotants, distorsion d’objectif. » N’entassez juste pas tout ce que vous détestez : 3-6 éléments suffisent.
J’ai aussi essayé une branche IP-Adapter pour verrouiller la pose sur les images. Cela a aidé pour les scènes « nature morte avec un petit mouvement » (vapeur, ondulations), mais pour le mouvement des personnages, cela a parfois pincé les gestes. Bon outil, retour sur investissement situationnel.
Stabilité du mouvement
C’était la partie la plus délicate. Un mouvement fluide sans transformer tout en gelée.
Les petits ajustements qui ont compté :
- Retenue de guidance. Garder CFG près de 5,0 a réduit les petits pops d’éclairage entre les images.
- Plafond de nombre d’étapes. Traverser ~36 étapes m’a donné des stills plus nets mais plus de micro-gigue au fil du temps.
- Choix du sampler. DPM++ 2M SDE était constamment plus calme dans les panoramas et les zooms lents : Euler semblait plus dynamique mais scintillait sur les bords à fort contraste.
- Verbes du prompt. Des mots comme « tremblant, tenu à main levée, chaotique » font ce qu’ils disent. Je les ai évités sauf si je voulais cet aspect.
- Sources de lumière. Les lumières ponctuelles dures et les reflets spéculaires encourageaient le scintillement. « Ciel couvert » ou « éclairage softbox » gardait les surfaces stables.
Quand j’avais besoin de plus de prise, j’ai ajouté deux choses après le rendu plutôt qu’à l’intérieur du graphique :
- Une passe de deflicker légère (deflicker de DaVinci Resolve ou un filtre FFmpeg) à faible force.

- Interpolation d’images 12→24 fps avec interpolation compensée en mouvement. Cela a lissé le mouvement perçu sans confondre le modèle pendant la génération.
Une surprise : les poussées de caméra (dolly-in lent) tenaient mieux que les panoramas latéraux. Si un panorama de gauche à droite n’arrêtait pas de se déchirer sur la signalisation, je reformulais le prompt en « la caméra se déplace doucement en avant » et j’obtenais des résultats plus nets avec un sentiment similaire.
Rendu par lots
Je ne m’attendais pas à ce que les lots aident, mais ils l’ont fait, surtout pour la prise de décision. Exécuter 4-8 seeds consécutives a exposé quels prompts avaient vraiment du potentiel.
Ce que j’ai utilisé :
- Un simple nœud « Seed (batch) » alimentant le même graphique.
- Longueur de queue de 4-6 travaux. Au-delà, j’ai commencé à faire du babysitting thermique pour aucune bonne raison.
- Mêmes paramètres de base sur tout le lot : seule la seed variait.
Conseils de quelques nuits d’exécutions :
- Gardez la durée courte dans les lots (2-3 secondes). Vous saurez en une seconde si une seed est prometteuse.
- Enregistrez avec des noms de fichiers informatifs : slug de prompt + seed + résolution + fps. J’ai aussi ajouté la seed aux métadonnées vidéo, le moi futur me remerciera.
- Si la VRAM augmente, réduisez la taille du lot à 1 mais gardez la liste des seeds. C’est toujours un lot en esprit.
J’ai essayé de traiter par lots différentes valeurs CFG en une seule fois. Cela a marché, mais cela a brouillé la comparaison. J’ai obtenu des lectures plus nettes en isolant une seule variable par lot.
Erreurs courantes
Quelques récidivistes se sont montrés. Aucun n’était dramatique, mais ils ont mangé du temps jusqu’à ce que je les note.
- CUDA mémoire insuffisante. Habituellement un signe que j’avais nudgé la résolution juste au-delà d’une falaise. Correctifs : baisser la largeur/hauteur de 64 px, réduire les étapes de 4-6, ou fermer n’importe quoi grignotant la VRAM (les onglets du navigateur comptent). La demi-précision (fp16) a aidé.
- Modèle/config non-appariés. Si le chargeur WAN 2.5 et sa config ne sont pas d’accord, vous obtiendrez des erreurs de forme ou de dtype. Réinstaller le pack de nœuds et resélectionner la config exacte l’a corrigé.
- Dimensions non-divisibles. Les décodeurs vidéo sont plus pointilleux. Je m’en tiens aux multiples de 16 pour la largeur et la hauteur.
- Codec non-supporté. Le nœud Sauvegarder la vidéo avait parfois par défaut un codec que mon FFmpeg système n’aimait pas. J’ai défini H.264 avec yuv420p explicitement pour éviter les images vertes.
- Prompts cassés. Les négatifs sur-spécifiés ont fait effondrer les visages. Supprimer « déformé, défiguré, moche » (le boilerplate habituel) a en fait amélioré la stabilité dans plusieurs clips.
Quand les logs devenaient bruyants, je vérifiaisais deux choses d’abord : la version de ComfyUI (mettez à jour si vous êtes de quelques semaines en arrière), et le pilote NVIDIA. Deux tiers de mes bizarreries vivaient là. Si vous êtes bloqué, les problèmes GitHub de ComfyUI sont étonnamment directs sur les patterns d’erreur.
 Si vous préférez vous concentrer sur les prompts et le mouvement plutôt que sur les pilotes et les limites de VRAM, c’est une raison pour laquelle nous avons construit WaveSpeed. Nous offrons un accès géré aux modèles comme WAN 2.5 via une couche API stable — afin que vous puissiez générer sans maintenir la pile locale.
Si vous préférez vous concentrer sur les prompts et le mouvement plutôt que sur les pilotes et les limites de VRAM, c’est une raison pour laquelle nous avons construit WaveSpeed. Nous offrons un accès géré aux modèles comme WAN 2.5 via une couche API stable — afin que vous puissiez générer sans maintenir la pile locale.
Export
J’ai arrêté de trop réfléchir à l’export une fois que j’ai choisi un chemin propre.
Ce que j’utilise pour les brouillons :
- Codec : H.264
- Format de pixel : yuv420p
- FPS : correspondre à la génération (généralement 12)
- Débit : constant 8-12 Mbps pour 896×504
Pour l’édition, j’exporte d’abord plus perdu, puis je ne up-convertis que les gardiens :
- Interpolez 12→24 fps en post-production.
- Si j’ai besoin de fichiers adaptés à la notation, je rerender les finales en ProRes 422 LT. Plus lourd, mais beaucoup plus agréable pour les passes de couleur.
Deux petites notes qui m’ont sauvé de re-rendus :
- Décalages de couleur : certains lecteurs lèvent les noirs sur yuv420p. Si cela semble faux dans VLC mais bien dans Resolve, c’est le lecteur.
- Audio : le nœud Sauvegarder la vidéo ne l’ajoutera pas. Si j’ai besoin d’une bande sonore temporaire, je mux avec FFmpeg après.
J’intègre aussi la seed, les étapes, CFG, et la résolution dans le nom de fichier et dans un JSON en sidecar. C’est un travail de bureau ennuyeux qui prévient l’archéologie future.
Idée de modèle
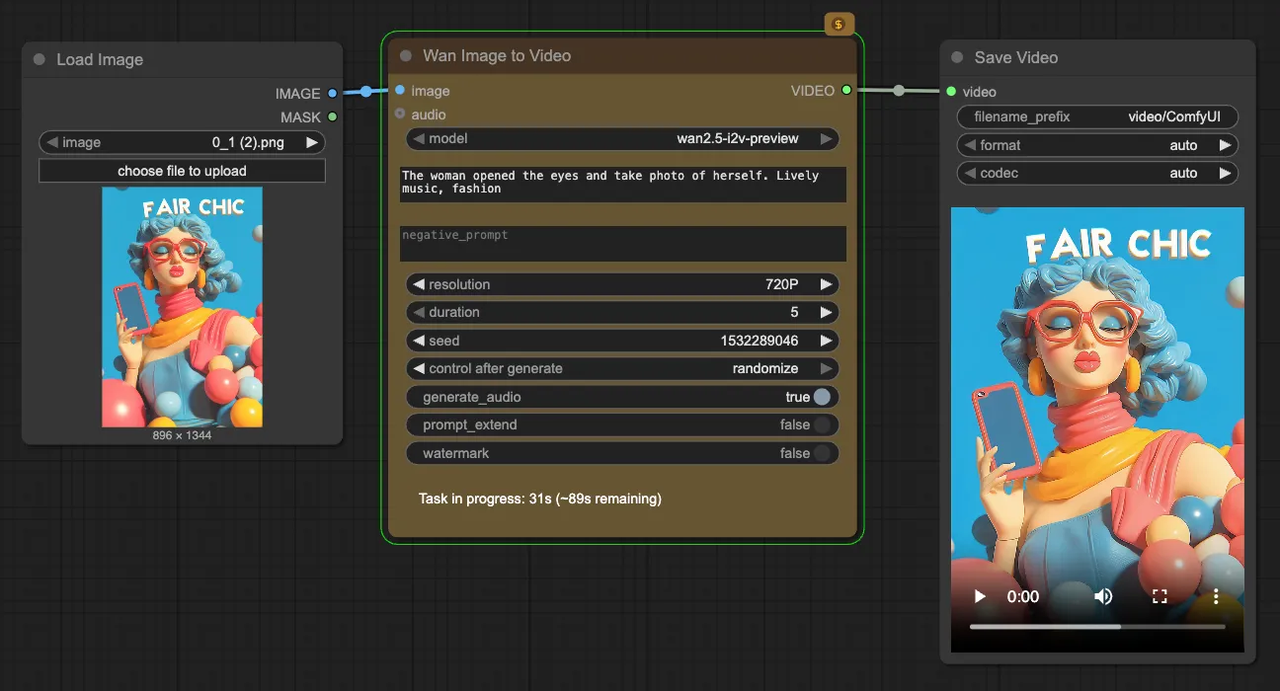 Le modèle que je garde maintenant est petit et a trois bascules.
Le modèle que je garde maintenant est petit et a trois bascules.
Squelette du graphique :
- Chargeur WAN 2.5 → encodeur de texte → seed fixe → sampler vidéo → décodage VAE → Sauvegarder la vidéo
Trois branches optionnelles que je peux activer ou désactiver :
- Conditionnement d’image de référence. Quand je veux des personnages stables. S’accompagne d’une baisse automatique de denoise et CFG.
- Calendrier de prompt. Un gentle two-phase prompt pour les clips avec un simple beat (par exemple, « la pluie commence » après une seconde). Je garde les transitions douces pour éviter le scintillement.
- Liste de seeds par lot. Un seul champ où je colle 3-8 seeds.
Défauts cuits :
- 896×504 à 12 fps, 48 images, CFG 5,0, étapes 30
- Export H.264 avec yuv420p, modèle de nom de fichier qui inclut la seed
C’est le contraire de spectaculaire, et c’est le point. Je veux un modèle qui m’encourage vers les mêmes habitudes à chaque fois : d’abord des clips courts, une variable à la fois, des notes au fur et à mesure.
À qui cela convient : à quiconque valorise la régularité plutôt que la surprise, aux équipes de produits faisant des shots répétables, aux créateurs solo qui ont besoin d’un aspect prévisible, et aux gens qui trouvent les grands graphiques plus fatigants qu’habilitants.
Qui ne l’aimera pas : si vous aimez les curseurs maximaux et les regards émergents chaotiques, vous rebondirez sur celui-ci. C’est OK.
Pourquoi c’est important pour moi : WAN 2.5 dans ComfyUI semblait enfin respecter mon attention. Moins de boutons, des compromis plus clairs, et des résultats en lesquels je pouvais assez faire confiance pour construire dessus.
Je suis toujours curieux de savoir comment WAN se comporte à des résolutions plus élevées et des séquences plus longues, mais je n’ai pas eu hâte. La victoire tranquille pour moi a été de remarquer que les petits changements, un CFG plus calme, une seed fixe, un éclairage plus doux, ont fait plus pour la stabilité que n’importe quel nœud héroïque. Je m’attendais à un truc. Il s’est avéré être un système.
Articles associés

Seedance 2.0 arrive bientôt : Le modèle vidéo nouvelle génération de ByteDance avec audio natif

Guide Complet Seedance 2.0 : Création Vidéo Multimodale

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1 : La Comparaison Ultime de la Génération Vidéo

Guide Complet Seedream 5.0-Preview : Génération d'Images Intelligente

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image : Comparaison Complète
