Démo en ligne TranslateGemma + Guide de démarrage rapide

Bonjour, je m’appelle Dora. Avez-vous entendu parler de « TranslateGemma » ?
Le coup de pouce pour celui-ci était léger : un client m’a envoyé du texte mélangé en anglais et en espagnol, plus quelques placeholders malveillants, et je ne voulais pas surveiller un modèle de traduction ligne par ligne. Vous savez, le genre : un mauvais pas et les placeholders s’effondrent. Je continuais à voir « TranslateGemma » surgir dans les discussions, alors j’ai essayé, non parce qu’il était nouveau, mais parce que je voulais un moyen plus calme d’obtenir des traductions fidèles sans détruire la mise en forme. Spoiler : cela a surtout livré. Je l’ai testé en janvier 2026 sur plusieurs démos en ligne et une configuration locale. Voici ce qui a vraiment aidé, où cela a buté, et comment j’ai fini par structurer les prompts pour le maintenir stable.
Essayez TranslateGemma en Ligne (Sans Configuration)
Je n’aime pas installer des choses juste pour voir si elles sont utiles. J’ai donc commencé par TranslateGemma en ligne. Si vous cherchez « TranslateGemma online », vous trouverez une poignée de playgrounds hébergés : Hugging Face Spaces, des démos Replicate, et quelques UIs web légers qui enveloppent des checkpoints basés sur Gemma ajustés pour la traduction. Certains nécessitent une connexion gratuite : d’autres non. De toute façon, vous pouvez généralement coller du texte et sélectionner les langues.
Ce qui m’a surprise : la vitesse était correcte même sur les démos partagées. Les paragraphes courts revenaient en une seconde ou deux : les pages plus longues prenaient un peu plus, mais pas assez pour me pousser vers le café. J’ai quand même continué à fixer l’écran. Vieille habitude, j’imagine. La plus grande différence n’était pas la vitesse, c’était comment je formulais le prompt.
Un simple « Traduire en français » fonctionnait, mais les résultats s’éloignaient quand le texte mélangeait les tons, contenait du code inline, ou utilisait des variables comme {{first_name}}. La correction était un ensemble d’instructions court et explicite. Quand la démo exposait un champ « system prompt », je l’utilisais. Quand ce n’était pas le cas, je mettais l’instruction au début du message utilisateur.
Voici le prompt minimal qui a réduit régulièrement le nettoyage pour moi :
- Nommez les langues source et cible.
- Dites au modèle ce qu’il faut garder inchangé (placeholders, blocs de code, tags).
- Encadrez le texte pour que le modèle sache où il commence et s’arrête.
- Demandez une traduction pure sans commentaire.
Exemple que j’ai utilisé en ligne :
Exemple que j’ai utilisé en ligne :
Traduire ce qui suit de l'anglais au français. Gardez les placeholders comme {{first_name}}, {{price}}, et les tags HTML inchangés. Préservez les sauts de ligne et la ponctuation. Retournez uniquement le texte traduit, rien d'autre.
<
Objet : Bienvenue, {{first_name}}.
Votre total est {{price}}.
Cliquez <a href="/start">ici</a> pour commencer.
>>>Cela n’a pas gagné de temps la première fois. Après deux passages, c’était le cas, surtout parce que j’ai arrêté de corriger les placeholders cassés. Si vous faites juste un test de santé sur TranslateGemma en ligne, essayez un court passage avec et sans cette structure. La différence apparaît rapidement.
Format de Modèle de Chat Que Vous Devez Suivre
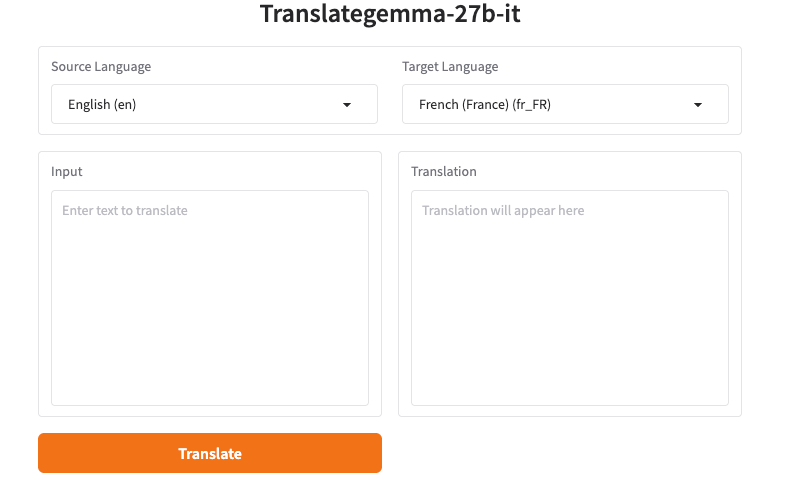 Les modèles de chat de style Gemma répondent mieux quand vous respectez les marqueurs de tour. Certaines UIs les ajoutent pour vous. D’autres s’attendent à du texte brut. Si vous envoyez des prompts directement (API, Python, ou une UI basique), un modèle clair et répétable aide.
Les modèles de chat de style Gemma répondent mieux quand vous respectez les marqueurs de tour. Certaines UIs les ajoutent pour vous. D’autres s’attendent à du texte brut. Si vous envoyez des prompts directement (API, Python, ou une UI basique), un modèle clair et répétable aide.
Deux patterns fiables ont fonctionné pour moi :
1. Modèle en texte brut (fonctionne dans la plupart des démos web)
Vous êtes un assistant de traduction précis.
- Langue source : anglais
- Langue cible : français
- Gardez les placeholders comme {{...}}, les backticks markdown, et les tags HTML inchangés.
- Préservez la ponctuation et les sauts de ligne. N'ajoutez pas d'explications.
Texte à traduire :
<
[COLLEZ VOTRE TEXTE]
>>>2. Style tour de chat Gemma (utile dans les bibliothèques qui exposent le modèle de chat)
<start_of_turn>user
Vous êtes un assistant de traduction précis.
Source : anglais
Cible : français
Règles : gardez les {{placeholders}}, les blocs de code, et le HTML intact : préservez les sauts de ligne : affichez uniquement la traduction.
Texte :
<
[COLLEZ VOTRE TEXTE]
>>>
<end_of_turn>
<start_of_turn>modelJe ne m’attendais pas à ce que les marqueurs de tour importent autant, mais c’est le cas. Sans eux, j’ai vu plus de paraphrases « utiles » (le modèle essayant d’améliorer la formulation). Avec eux, et avec une entrée encadrée, le modèle s’en tenait davantage à la tâche.
Les petits détails qui ont fait une grande différence :
- Nommez explicitement les langues. « De l’anglais au français » s’est mieux comporté que « Traduire en français ».
- Mettez les règles avant le texte. Si vous traînez les règles après le texte, elles sont plus faciles à ignorer.
- Encadrez le texte avec un début/arrêt distinct (
<<<et>>>ou triple backticks). Cela a réduit la troncature accidentelle au début ou à la fin.
Exécutez TranslateGemma Localement (Python)
 J’aime avoir un plan B local pour les travaux plus longs ou les brouillons sensibles. Appelez-moi paranoïaque, mais parfois le cloud se sent juste trop… bavard. Sur ma machine (32 GB RAM, GPU grand public), un checkpoint de traduction plus petit basé sur Gemma fonctionnait confortablement : les plus grands avaient besoin de plus de VRAM ou de quantification. Si vous êtes CPU uniquement, c’est lent mais faisable avec des paramètres soigneux.
J’aime avoir un plan B local pour les travaux plus longs ou les brouillons sensibles. Appelez-moi paranoïaque, mais parfois le cloud se sent juste trop… bavard. Sur ma machine (32 GB RAM, GPU grand public), un checkpoint de traduction plus petit basé sur Gemma fonctionnait confortablement : les plus grands avaient besoin de plus de VRAM ou de quantification. Si vous êtes CPU uniquement, c’est lent mais faisable avec des paramètres soigneux.
Voici un pattern simple avec Hugging Face Transformers. J’ai gardé le model_id générique exprès, choisissez un modèle de traduction Gemma ou dérivé de Gemma en qui vous avez confiance depuis le Hub, idéalement un documenté pour la traduction. Le modèle ci-dessous reflète les prompts en ligne.
# Testé en jan 2026 avec transformers >= 4.40
from transformers import AutoTokenizer, AutoModelForCausalLM, TextStreamer
import torch
model_id = "<your-gemma-translation-checkpoint>" # e.g., a Gemma chat or translation-tuned model
device = "cuda" if torch.cuda.is_available() else "cpu"
dtype = torch.float16 if device == "cuda" else torch.float32
# Load
tokenizer = AutoTokenizer.from_pretrained(model_id, use_fast=True)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=dtype,
device_map="auto" if device == "cuda" else None
)
# Prompt template (plain text). Swap for chat turns if your model requires them.
prompt = (
"You are a precise translation assistant.\n"
"Source language: English\n"
"Target language: Spanish\n"
"Rules: keep placeholders like {{...}}, code blocks, and HTML tags unchanged: "
"preserve punctuation and line breaks: output only the translation.\n\n"
"Text:\n<<<\n"
"Subject: Welcome, {{first_name}}.\nYour total is {{price}}.\n"
"<p>Click <a href=\"/start\">here</a> to begin.</p>\n"
">>>\n"
)
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
gen = model.generate(
**inputs,
max_new_tokens=300,
temperature=0.3,
top_p=0.9,
repetition_penalty=1.02,
do_sample=True,
eos_token_id=tokenizer.eos_token_id,
)
output = tokenizer.decode(gen[0][inputs["input_ids"].shape[1]:], skip_special_tokens=True)
print(output)Quelques notes de test
- Si votre checkpoint inclut un modèle de chat, utilisez l’utilitaire
apply_chat_template()de la bibliothèque au lieu de chaînes manuelles. Cela réduit les comportements bizarres de moitié. - Pour les entrées longues, définissez
max_new_tokensassez haut et gardeztemperaturebas (0,2–0,4). Un échantillonnage plus chaud invitait des « améliorations ». Certaines utiles, d’autres… pas tellement. - La quantification aide sur les petits GPUs. 4-bit (bitsandbytes) s’est bien comporté pour une traduction droite.
- Si vous avez besoin de traduction par lot, encapsulez le prompt dans une petite fonction et diffusez les lignes. J’ai trouvé que la segmentation par paragraphe était plus sûre que les gros blobs, moins de risque de perdre la structure.
Avez-vous besoin d’exécuter des charges de travail de traduction sans gérer l’infrastructure GPU ou les configurations locales ?
Nous avons construit WaveSpeed pour que notre équipe puisse appeler les modèles via une API unifiée et gérer les tâches par lot sans lancer de serveurs ou lutter avec les pilotes → Essayez-le!
Erreurs Courantes et Correctifs
 Ce sont les patterns que j’ai rencontrés le plus souvent en essayant TranslateGemma en ligne et localement, plus ce qui a vraiment réduit les frictions pour moi.
Ce sont les patterns que j’ai rencontrés le plus souvent en essayant TranslateGemma en ligne et localement, plus ce qui a vraiment réduit les frictions pour moi.
La Sortie N’est Pas dans la Langue Cible
J’ai vu cela surtout quand je n’ai pas déclaré la langue source. Les entrées multilingues l’ont confus juste assez pour garder des phrases en anglais autour. Les correctifs qui ont tenu :
- Nommez les deux langues : « Traduire de l’anglais au français. » Ne pas compter sur la détection quand la précision compte.
- Réduisez la température (0,2–0,4) et utilisez une légère
repetition_penalty(autour de 1,02). Cela a éloigné le modèle des réécritures créatives. - Ajoutez une ligne de garde finale : « Si le texte est déjà en français, retournez-le inchangé. » Cela a réduit la sur-traduction sur les snippets bilingues.
Mise en Forme Perdue ou Placeholders
C’était le gros avec les e-mails marketing et les chaînes de produit. Les premiers passages cassaient {{variables}} ou réorganisaient le HTML. Ce qui a aidé :
- Soyez explicite : « Gardez les placeholders comme
{{...}}et les tags HTML inchangés. Ne traduisez pas à l’intérieur des barrières de code. » - Encadrez l’entrée et préservez les sauts de ligne. Le pattern
<<<et>>>a mieux fonctionné que de compter sur les lignes vides. - Pour le contenu fragile, entourez les placeholders de marqueurs dans le prompt : « Les placeholders sont protégés avec des accolades doubles comme
{{this}}. Ne les modifiez pas. » Si une démo continuait à perdre les accolades, j’ai remplacé temporairement{{par[[[et}}par]]]avant la traduction, puis réchangé. Ce n’est pas élégant, mais c’est plus sûr pour les travaux en masse.
Le Modèle Réécrit au Lieu de Traduire
Parfois, la sortie lisait comme la réécriture d’un éditeur, pas une traduction. Utile dans certains contextes, ennuyeux dans la plupart. Mes correctifs pratiques :
- Énoncez le rôle et la contrainte en haut : « Vous êtes un assistant de traduction. Affichez uniquement une traduction fidèle. Pas de résumés, pas d’explications. »
- Réduisez la température et évitez les longs
max_new_tokenssur les courtes entrées : l’espace supplémentaire encourageait le commentaire dans certains checkpoints. - Si le modèle continue à s’embellir, essayez le modèle tour de chat avec un arrêt clair. Dans le code local, définissez les séquences d’arrêt sur vos marqueurs de tour (par ex.,
<end_of_turn>). Dans les démos hébergées sans support d’arrêt, ajouter « Retournez uniquement le texte traduit » a réduit les remplissages d’environ 80% du temps.
Une dernière note tranquille : certains checkpoints communautaires étiquetés pour la traduction sont en réalité des modèles généraux ajustés sur les instructions. Ils traduiront, mais ils sont plus bavards. Si vous frappez les trois problèmes à la fois, essayez un checkpoint différent ou un plus petit et plus strict. Moins astucieux signifie souvent plus fidèle dans cette voie. Et honnêtement, c’est tout ce dont j’avais besoin.
Avez-vous essayé TranslateGemma ? Quel est votre prompt préféré pour garder les placeholders intacts, ou le texte le plus difficile qui l’a fait buté ? Partagez vos victoires, vos échecs, ou vos astuces préférées ci-dessous !
Articles associés

Seedance 2.0 arrive bientôt : Le modèle vidéo nouvelle génération de ByteDance avec audio natif

Guide Complet Seedance 2.0 : Création Vidéo Multimodale

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1 : La Comparaison Ultime de la Génération Vidéo

Guide Complet Seedream 5.0-Preview : Génération d'Images Intelligente

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image : Comparaison Complète
