Seedance 1.5 Pro : Une étape majeure vers la génération audio-visuelle native

À mesure que la vidéo générative entre en production réelle, les visuels seuls ne sont plus suffisants. Les flux de travail modernes nécessitent de plus en plus que la vidéo et l’audio soient générés ensemble—nativement et en synchronisation.
Seedance 1.5 Pro, le modèle de nouvelle génération de ByteDance pour la co-génération audio-visuelle native, est désormais disponible sur WaveSpeedAI. Conçu de zéro pour une synchronisation fiable, contrôlable et prête pour la production, il marque une étape importante vers une véritable génération multimodale unifiée.
Dans un prochain article à dominante technique, nous examinerons de plus près Seedance 1.5 Pro—en explorant ses capacités de modèle, cas d’usage pratiques, insights des benchmarks, et l’architecture multimodale qui le sous-tend.
Capacités principales du modèle (Fonctionnalités et utilisation pratique)
1. Génération audio-visuelle native avec synchronisation haute fidélité
La percée la plus fondamentale de Seedance 1.5 Pro est son paradigme de génération audio-visuelle-natif. En une seule passe d’inférence, le modèle produit à la fois les images vidéo et la piste audio correspondante, en maintenant l’alignement du rythme vocal, du mouvement des lèvres, du mouvement des personnages et de la dynamique de caméra dans la même référence temporelle.
Au cours de plusieurs tours d’évaluation, Seedance 1.5 Pro a constamment surpassé les pipelines courants de « vidéo + TTS » stitchés—particulièrement dans les dialogues longs, les mouvements rapides des lèvres et les scénarios action-avec-son où les approches traditionnelles ont tendance à dériver.
Prompts : Un homme séduisant se tient au sommet d’une crête montagneuse enveloppée de brume. Il porte un équipement de plein air épuré et pratique—une veste coupe-vent gris charbon foncé, un pantalon d’escalade professionnel et un sac à dos sur les deux épaules. La brise montagnarde ébouriffe légèrement ses cheveux ; son expression est calme et déterminée. Derrière lui, des nuages et de la brume tourbillonnants s’enroulent parmi les rochers dentelés, s’ouvrant occasionnellement pour révéler des pics enneigés au loin. La caméra pousse lentement de l’arrière alors qu’il regarde dans l’abîme des nuages qui roulent ci-dessous. Dans l’air glacial, son souffle se condense en brume blanche, ajoutant un détail atmosphérique naturel. Il se tourne légèrement vers la caméra, ses yeux perçants remplis d’une détermination inébranlable, et dit d’une voix ferme et puissante : « J’aime les défis. »
2. Génération multi-locuteurs, multi-langues et consciente des dialectes
Seedance 1.5 Pro prend en charge la génération audio-visuelle dans les principales langues mondiales et les dialectes régionaux. Il préserve le timing, les phonèmes et les expressions spécifiques à la langue, offrant une synchronisation labiale précise et un alignement émotionnel naturel—même à travers plusieurs locuteurs et des changements rapides de langue.
Prompts : Un court-métrage de style anime japonais hautement cinématographique dépeignant la splendeur d’un festival de feux d’artifice d’été. L’accent est mis sur les textures très détaillées (tissu de kimono, cheveux, peau), les micro-expressions subtiles, le mouvement naturel et fluide, et la narration délicate et émotionnellement riche. Les feux d’artifice ressemblent à un éclairage cinématographique doux, améliorant l’atmosphère émotionnelle. (prompt omis…) Elle dit doucement en japonais : « Je t’aime beaucoup ». L’homme s’incline légèrement et se résout à parler : « En fait, je t’aime aussi ». (prompt omis…)
3. Mouvement expressif et performance émotionnelle
Seedance 1.5 Pro va au-delà des stratégies de mouvement conservatrices et à faible risque. L’animation des personnages montre une plus grande amplitude, une variation de tempo plus riche et une intention émotionnelle plus claire—tout en maintenant la stabilité globale.
Les expressions faciales progressent de simples reconnaissables à véritablement performatives : les micro-expressions, les transitions émotionnelles et le langage corporel s’alignent naturellement avec le dialogue parlé. Le résultat est un mouvement qui semble nettement plus vivant.
Prompts : Un jeune astronaute dans une combinaison spatiale usée est assis dans le cockpit faiblement éclairé d’un vaisseau spatial. La visière du casque est couverte de buée et de rayures, et le panneau de contrôle scintille de lumières orange-jaune, créant une atmosphère tendue et solitaire. La vidéo commence par ce cadre d’ouverture statique. La caméra fait ensuite rapidement un zoom sur le visage de l’astronaute avant de basculer à l’extérieur, révélant le vaisseau spatial fendant une tempête semblable à un blizzard de débris cosmiques. Style de thriller de science-fiction. Musique de fond : synthétiseurs électroniques graves associés à des cordes montantes rapides pour construire la tension. Effets sonores : bourdonnements de moteur urgents et bruit de tempête spatiale hurlante. Dialogue : « Dans le vide de l’espace, une seule erreur… » suivi d’un bref silence, se terminant par : « Mayday… systèmes défaillants. »
4. Esthétique visuelle cinématique orientée vers le photo-réalisme
Visuellement, Seedance 1.5 Pro penche vers un look naturel en prise de vue réelle plutôt que vers une stylisation lourde ou des effets surrendu.
L’éclairage, la composition, l’harmonie des couleurs et la profondeur de champ sont constamment stables, produisant des résultats qui se rapprochent de la cinématographie de qualité commerciale plutôt que de l’imagerie synthétique.
Prompts : POV à la première personne depuis le siège avant d’un énorme montagnes russes en acier. Les montagnes russes franchissent le sommet et plongent tout droit dans un tunnel sombre. Le paysage environnant (un parc d’attractions au coucher du soleil) est légèrement flou, tandis que le vent est représenté comme des particules d’air sifflant.
5. Adaptation automatique de la durée vidéo
En définissant le paramètre de longueur vidéo sur -1, Seedance 1.5 Pro sélectionne automatiquement la durée la plus appropriée dans une plage de 4–12 secondes (secondes entières uniquement).
Le modèle évalue le rythme narratif, l’exhaustivité du mouvement et la clôture audio-visuelle pour choisir un point d’arrivée naturel. Cela réduit les générations gaspillées et l’ajustement manuel causés par des durées fixes mal choisies.
Prompts : Style d’art pixel 8 bits, un héros courant et sautant au coucher du soleil, avec des effets de ligne de balayage et de la musique de jeu vidéo rétro.
6. Effets intégrés via contrôle des prompts
Seedance 1.5 Pro inclut une gamme d’effets intégrés directement dans le modèle de base. Ceux-ci peuvent être déclenchés via les instructions du prompt plutôt que de s’appuyer entièrement sur la composition en post-production.
Ceci est particulièrement utile pour le contenu riche en animation ou stylisé—comme les bandes dessinées en mouvement—où la densité des effets et le timing sont critiques.
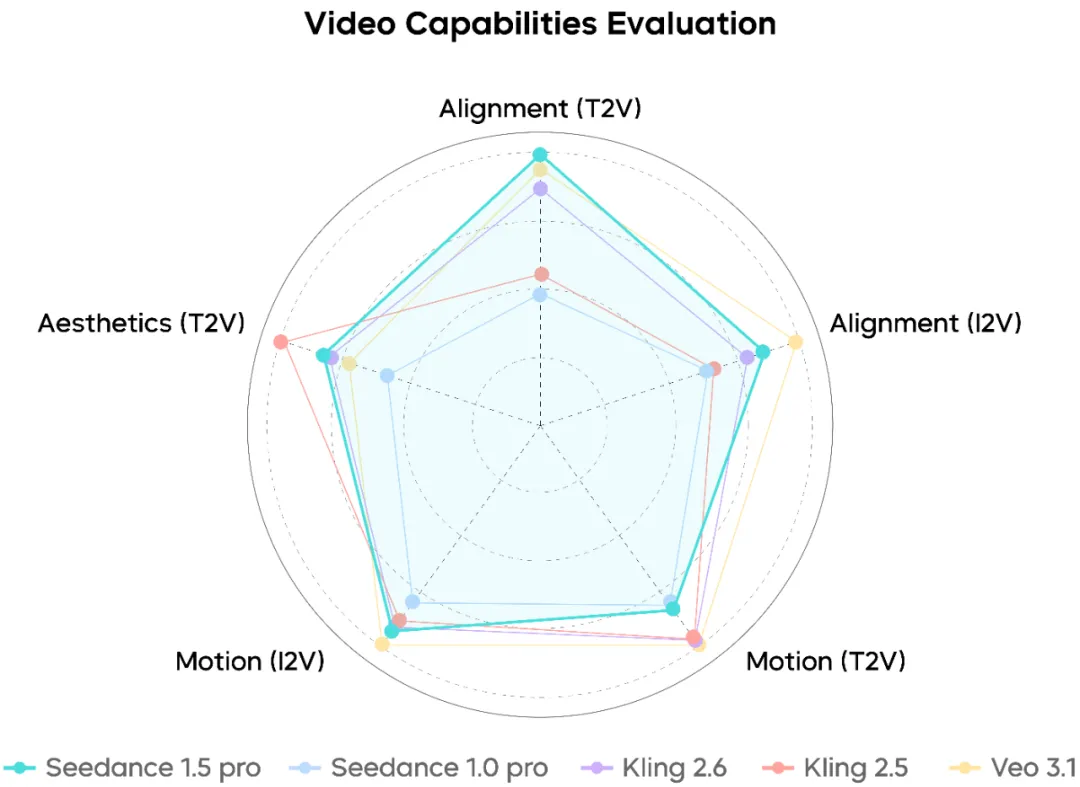
Performances de génération vidéo
Seedance 1.5 Pro démontre une forte compréhension des prompts complexes impliquant la chorégraphie de caméra, la séquençage des actions et le rythme narratif. Les gros plans du visage semblent naturels, tandis que les longs plans et les mouvements de caméra composés restent relativement fluides et cohérents.
Cela dit, dans les scénarios de mouvement d’extrême intensité, il y a encore de la place pour d’autres améliorations de stabilité.
Performances de génération audio
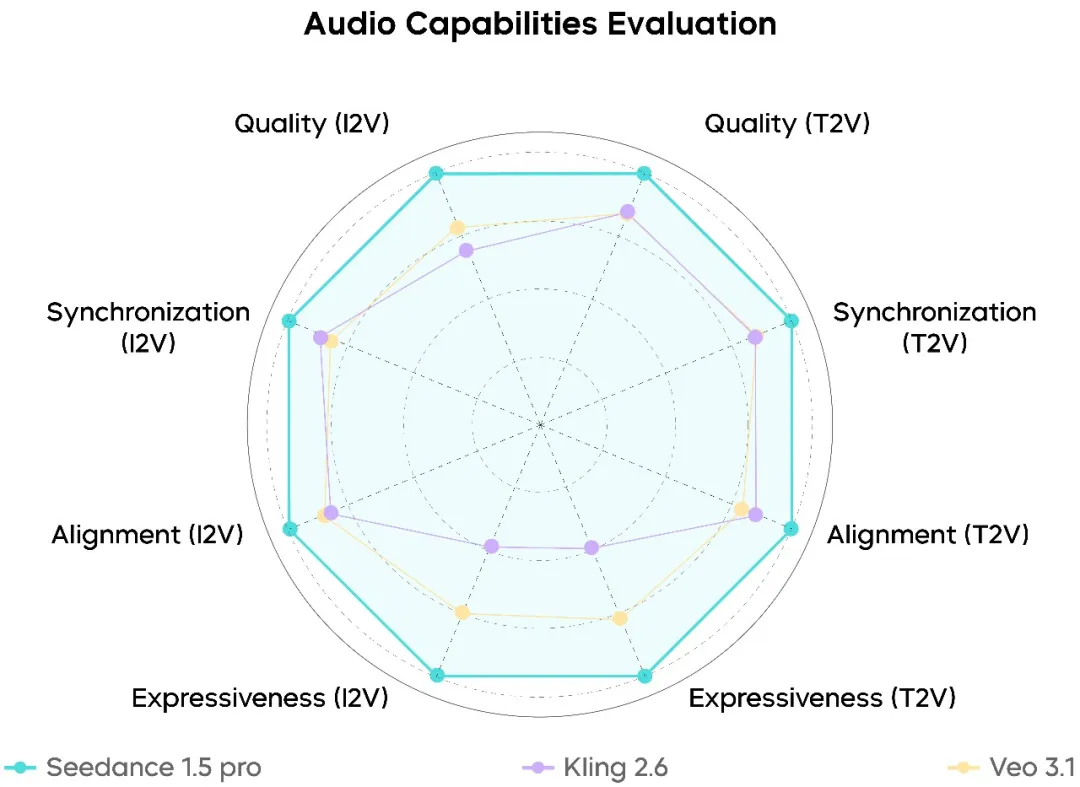
Du côté audio, Seedance 1.5 Pro se situe fermement dans la catégorie supérieure des modèles actuels :
- Voix humaines hautement naturelles avec artefacts mécaniques réduits
- Caractéristiques audio spatial et réverbération plus réalistes
- Erreurs d’alignement audio-visuel considérablement moins nombreuses
Les performances sont particulièrement fortes dans le dialogue chinois et riche en dialectes, où l’exhaustivité de la prononciation et la clarté répondent déjà aux exigences de la production réelle.
Architecture de co-génération multimodale : comment la vision et l’audio restent synchronisés
Seedance 1.5 Pro n’est pas un patchwork de modules indépendants—son pipeline d’entraînement et d’inférence a été repensé de bout en bout.
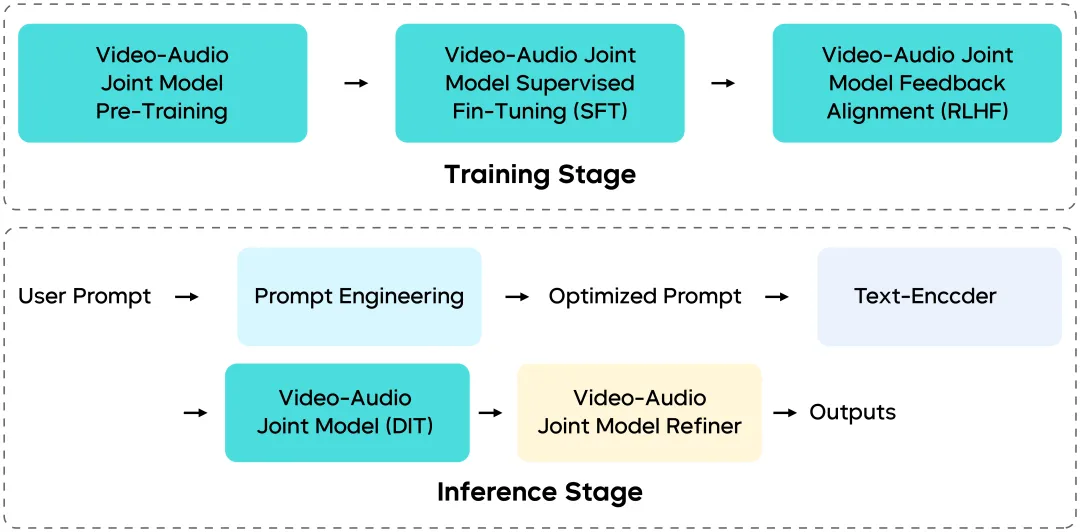
Architecture multimodale unifiée (basée sur MMDiT)
Construite sur une architecture de style MMDiT améliorée, le modèle permet une interaction profonde entre les flux visuels et audio dans le même espace temporel, garantissant :
- Synchronisation temporelle
- Cohérence sémantique
- Émotion et rythme coordonnés
Un entraînement multi-tâche mixte-modal à grande échelle améliore encore la généralisation dans les tâches en aval.
Pipeline de données multi-étapes
Le pipeline de données est conçu pour équilibrer :
- Alignement audio-visuel
- Expressivité du mouvement
- Calendriers d’entraînement basés sur le curriculum
En plus des données vidéo-caption traditionnelles, les descriptions audio structurées sont systématiquement introduites, permettant au modèle d’internaliser un espace sémantique audio-visuel conjoint plus riche.
Post-entraînement fin et RLHF
Des ensembles de données audio-visuels de haute qualité sont utilisés pour l’ajustement supervisé, aux côtés de modèles RLHF spécifiquement conçus pour la sortie audio-visuelle, renforçant :
- Qualité du mouvement
- Esthétique visuelle
- Fidélité audio
Inférence efficace et préparation au déploiement
Grâce à la distillation multi-étapes, la quantification et les optimisations d’inférence parallèle :
- Le nombre d’évaluations de fonction (NFE) est considérablement réduit
- L’inférence de bout en bout réalise des accélérations de 10×+ tout en maintenant la qualité
Cette efficacité est une raison clé pour laquelle Seedance 1.5 Pro peut être déployé de manière fiable sur WaveSpeedAI.
Cas d’usage prêts pour la production
Seedance 1.5 Pro est particulièrement bien adapté pour :
- Commerce électronique transfrontalier et publicité localisée
- Contenu narratif court et contenu épisodique
- Bandes dessinées en mouvement et animation expressive
- Narration de marque et marketing cinématographique
- Pré-visualisation de film et validation de concept
Réflexions finales
La valeur de Seedance 1.5 Pro ne réside pas dans le fait de prouver que les modèles peuvent générer du son—c’est de créer les conditions pour que la coordination audio-visuelle devienne un défaut fiable.
Pour les équipes en quête de production de contenu évolutive, cette approche unifiée, construite de zéro, promet moins de retouches en post-production, une plus grande liberté créative et un flux de travail vidéo générative conçu pour résister dans les environnements de production réels.
Articles associés

Seedance 2.0 arrive bientôt : Le modèle vidéo nouvelle génération de ByteDance avec audio natif

Guide Complet Seedance 2.0 : Création Vidéo Multimodale

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1 : La Comparaison Ultime de la Génération Vidéo

Guide Complet Seedream 5.0-Preview : Génération d'Images Intelligente

Examen de Vidu Q3 : Comment il se compare à Sora 2, Wan 2.6, Seedance 1.5, Veo 3.1 et Grok Imagine Video
