GLM-4.7-Flash vs GLM-4.7 : Lequel convient à votre projet ?

Bonjour mes amis. Je suis Dora. Si cela vous semble familier, vous n’êtes pas seul. J’y ai été : fixant une file d’attente de petites invites répétitives qui n’ont besoin que d’une réponse rapide et solide—tandis que quelques tâches de raisonnement multi-étapes têtues restent de côté, demandant tranquillement beaucoup plus de puissance.
J’ai donc finalement posé la question à haute voix : où GLM-4.7-Flash brille-t-il vraiment, et où avez-vous besoin d’apporter le modèle plus lourd et plus délibéré GLM-4.7 ? C’est la réponse directe, sans prise de tête, sur laquelle j’ai abouti—basée sur des exécutions réelles, des benchmarks quand ils comptent, et l’objectif tranquille de rendre votre pile quotidienne notablement plus légère. Si vous vous êtes déjà arrêté en vous demandant « quel modèle devrais-je utiliser ici ? », c’est pour vous.
Réponse en 30 secondes
Si la rapidité et le faible coût sont vos principaux leviers, GLM-4.7-Flash vous semblera probablement approprié. Si votre travail repose sur la profondeur du raisonnement, les outils, ou des résultats de plus haute fidélité, GLM-4.7 est le choix plus stable. Le reste est une nuance autour des budgets de latence, de la taille du contexte, et de la façon dont vos invites se comportent sous pression.
Choisir Flash si…
Flash n’est pas « plus faible »—il est juste très honnête sur ce pour lequel il est bon.
- Vous distribuez de nombreux petits travaux : résumés, étiquettes, brouillons, transformations rapides.
- La latence est plus importante que d’extraire les derniers 10 % de qualité.
- Vous expérimentez, créez des prototypes, ou construisez des interactions UI qui doivent sembler instantanées.
- Les petits problèmes occasionnels dans les longues étapes de raisonnement ne vous arrêteront pas.
- Vous voulez un modèle par défaut moins cher et pouvez escalader vers GLM-4.7 seulement quand c’est nécessaire.
Choisir GLM-4.7 si…
C’est votre modèle « ne gâchez pas cela ».
- Vous vous souciez de la fiabilité du code, du raisonnement multi-étapes, ou de la précision de l’utilisation d’outils.
- Les invites sont longues, les instructions strictes, ou les résultats doivent être cohérents.
- Vous exécutez des évaluateurs, des tests, ou des flux de travail où une erreur est coûteuse.
- Vous avez besoin de résultats plus forts sur les tâches de codage et de long contexte.
- Vous pouvez tolérer un coût plus élevé et un peu plus de latence pour de meilleurs résultats.
Différences architecturales
 Je ne chasse pas les comptes de paramètres pour le sport, mais l’architecture explique beaucoup sur le comportement : pourquoi un modèle semble rapide et l’autre semble délibéré.
Je ne chasse pas les comptes de paramètres pour le sport, mais l’architecture explique beaucoup sur le comportement : pourquoi un modèle semble rapide et l’autre semble délibéré.
Nombre de paramètres et experts actifs
GLM-4.7 semble exécuter un backbone plus grand et (d’après les notes publiques) utilise un routage d’experts qui privilégie le raisonnement. Flash est réglé pour le débit, un routage plus léger, moins d’experts actifs par token, et des paramètres d’efficacité agressifs. En pratique, cela tend à se manifester par :
- Flash : calcul par token plus faible, temps de premier token rapides, mais il peut abandonner les chaînes de raisonnement sous stress.
- GLM-4.7 : plus de calcul par token, chemins de raisonnement plus stables, meilleurs choix d’appels d’outils.
Si vous survolez les diagrammes des fournisseurs, vous verrez des indices de mixture-of-experts (MoE) et d’activation parcimonieuse. Les chiffres exacts varient selon les versions, je les traite donc comme directionnels, pas absolus. L’idée principale : Flash dépense moins de « réflexion » par token donc il se déplace plus tôt ; GLM-4.7 réfléchit plus longtemps et trébuche moins sur les cas limites.
Fenêtre de contexte et limite de sortie
Deux questions pratiques sont plus importantes que le nombre de contexte en titre :
- À quel point dans les longues invites la qualité se maintient-elle ?
- Quand les résultats deviennent longs, le modèle perd-il le fil ?
Flash annonce généralement une fenêtre de contexte saine, mais la qualité a tendance à diminuer plus tôt avec des invites très longues ou des instructions denses. GLM-4.7 maintient la cohérence plus profondément dans les longs contextes et reste plus obéissant à la structure dans les longs résultats. Si vous empaquetez une base de connaissances, GLM-4.7 est le choix par défaut plus sûr. Si vous divisez les entrées ou utilisez la récupération pour garder les invites minces, Flash est souvent suffisant—et beaucoup plus rapide.
Comparaison des benchmarks
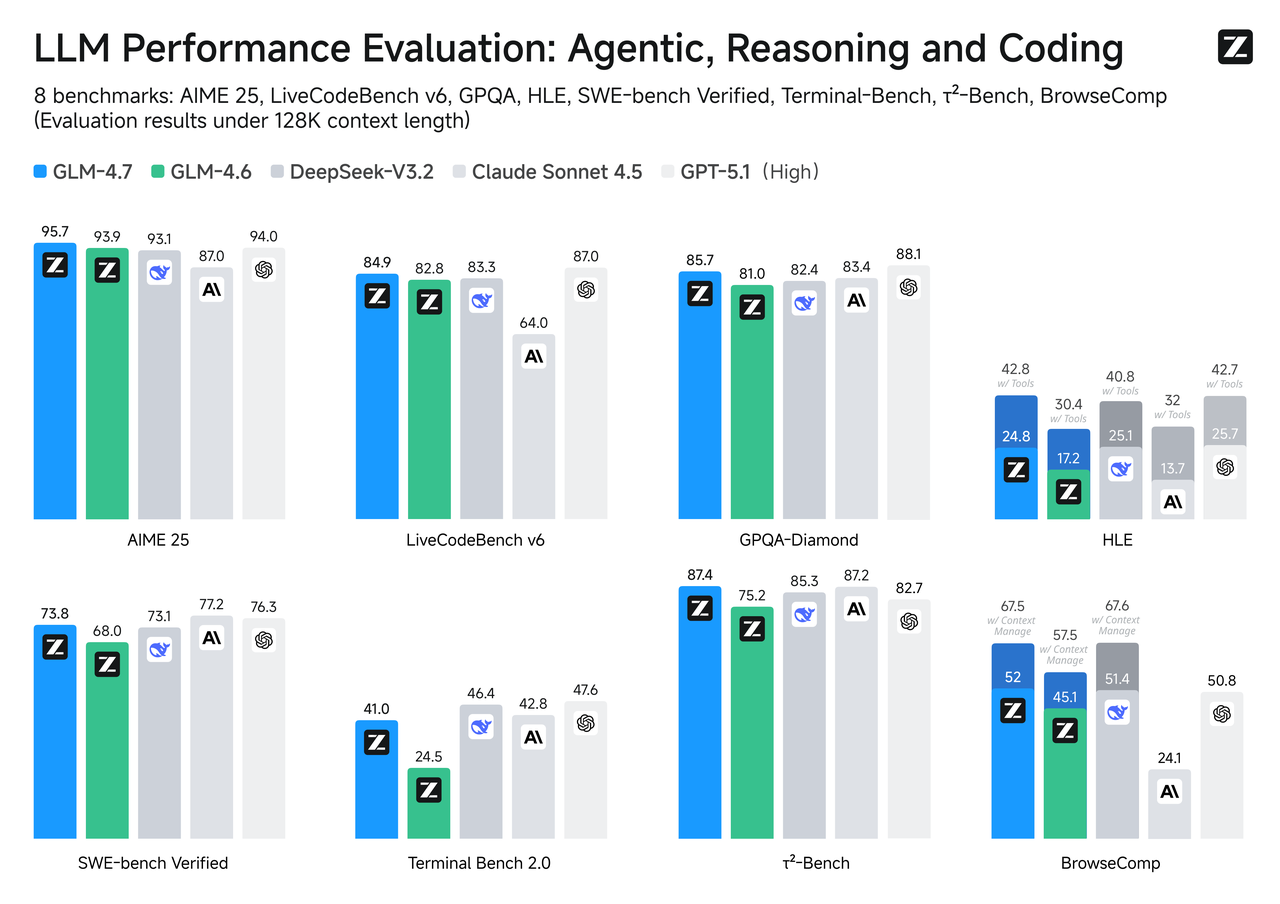 Les benchmarks ne sont pas toute l’histoire, mais ils sont une boussole utile, surtout quand votre cas d’usage s’aligne avec la tâche.
Les benchmarks ne sont pas toute l’histoire, mais ils sont une boussole utile, surtout quand votre cas d’usage s’aligne avec la tâche.
SWE-bench Verified
Pour les modifications de code qui doivent réellement compiler et passer les tests, GLM-4.7 a tendance à se classer au-dessus de son homologue Flash. Cela correspond à ce que vous attendriez d’un modèle réglé pour la profondeur du raisonnement et l’utilisation d’outils. Flash peut rédiger des correctifs et expliquer le code joliment, mais quand le patch a besoin de plusieurs modifications coordonnées entre les fichiers, GLM-4.7 est plus susceptible de suivre la chaîne sans sauter les étapes.
Si votre pipeline inclut des auto-PR ou des boucles de réparation, il vaut la peine de faire une vérification logique avec un petit échantillon d’abord. La différence se manifeste davantage sur les problèmes multi-sauts que sur les modifications à fichier unique.
LiveCodeBench / τ²-Bench
Sur les benchmarks de codage en direct ou en rotation temporelle, GLM-4.7 suit généralement plus près du tier supérieur compte tenu de son budget de raisonnement plus lourd. Flash, optimisé pour la vitesse, se situe un tier plus bas mais répond rapidement. Si votre produit repose davantage sur la qualité de la synthèse du code que sur la vitesse d’interaction, GLM-4.7 est le choix conservateur. Si le code est consultatif (vous le vérifierez de toute façon) et la réactivité compte, Flash peut être le bon compromis.
Vitesse et latence
C’est ici que la division semble la plus claire. Flash renvoie souvent le premier token notablement plus rapidement, et le temps total jusqu’au dernier token reste faible pour les résultats courts et moyens. Cela s’accumule si vous exécutez de nombreux petits appels ou diffusez vers une UI.
GLM-4.7 démarre plus lentement et fonctionne plus lourdement, mais il est plus stable pour les générations longues et les séquences d’appels d’outils complexes. Vous verrez moins de blocages, moins de détours bizarres, et une meilleure adhérence aux schémas de fonction.
Si vous construisez un système :
- Utilisez Flash pour les moments UX à haut trafic : saisie semi-automatique, résumés rapides, aide en ligne.
- Utilisez GLM-4.7 pour la voie lente : évaluateurs, actions de code, vérifications de politique, passes finales.
Une simple règle de routage paie souvent pour elle-même : commencez par Flash, escaladez vers GLM-4.7 quand la confiance baisse ou que les seuils sont franchis. Laissez les règles décider afin que vous n’ayez pas à le faire.
Ventilation des prix
Les prix varient selon la région et le fournisseur, je traite donc les chiffres comme des cibles mouvantes et je garde la structure stable.
Tier gratuit Flash vs GLM-4.7 paiement par token
-
Flash : De nombreuses plates-formes exposent un tier gratuit ou à faible coût pour les modèles de type Flash, avec des limites de débit généreuses par rapport aux modèles phares. Idéal pour le prototypage, les tâches de base et l’optimisation de l’UI.
-
GLM-4.7 : Généralement facturé par token à un taux plus élevé. Meilleure valeur coût-bénéfice sur les tâches sérieuses, mais il est facile de trop dépenser si vous le laissez par défaut.
 Conseils pratiques :
Conseils pratiques : -
Limitez les tokens de sortie par défaut. Augmentez la limite seulement dans les routes qui en ont besoin.
-
Utilisez la récupération pour garder les invites courtes : ne versez pas tout le corpus dans la fenêtre.
-
Mettez en cache les sous-résultats déterministes (cartes regex, extraits de schéma, blocs few-shot) afin de ne pas les payer à nouveau.
-
Enregistrez les coûts de token par route. Le rapport que vous lisez réellement est celui qui se trouve dans votre flux de travail hebdomadaire, pas celui avec le plus de graphiques.
En cas de doute, commencez bon marché, mesurez, puis promouvez. L’escalade bat l’optimisme.
Choisir par cas d’usage
Voici comment je les rangerais quand l’objectif est moins de maux de tête :
- Opérations de contenu à haut taux de roulement (extraits, lignes d’objet, métadonnées) : Flash. Le gain est le débit et la cohérence à faible coût.
- Macros de support et triage rapide : Flash en premier, puis escalader vers GLM-4.7 si la détection signale la complexité ou le risque de politique.
- Notes de recherche, synthèse, résumés structurés : Flash pour les survols ; GLM-4.7 pour la passe qui doit être fidèle à la source et bien scaffoldée.
- Assistance au code : Flash pour les explications et « que fait cela ? » ; GLM-4.7 pour les édits multi-fichiers, les migrations, et les modifications conscientes des tests.
- Nettoyage et transformation des données : Flash est bien pour le mappage simple ; GLM-4.7 pour les schémas stricts, la validation, et les jointures multi-étapes.
- Agents et utilisation d’outils : GLM-4.7. Vous obtiendrez des arguments de fonction plus fiables et moins de tentatives.
- Lecture de long contexte ou QA basée sur des documents : GLM-4.7 si vous poussez la fenêtre ; Flash si vous gardez les chunks minces.
Quelques notes de terrain que je garde à portée de main :
- Les invites courtes cachent les différences. L’écart se manifeste quand les instructions sont denses ou que les résultats doivent suivre une structure.
- Le routage aide. Même une simple règle, « Flash sauf si l’invite > N tokens, alors GLM-4.7 », économise de l’argent sans drame.
- Les garde-fous comptent plus que le choix du modèle pour les tâches répétitives. La validation, les tentatives, et les petits vérificateurs préviennent les gâchis en aval.
- Ne fetichisez pas la vitesse. Sous une seconde semble « instantané » pour la plupart des utilisateurs. Au-delà, le comportement stable bat le rasage de 100 ms.
Pourquoi cela compte : les outils vieillissent bien quand ils réduisent la charge mentale. Flash garde les petites choses légères. GLM-4.7 porte les boîtes lourdes sans les laisser tomber. La plupart des piles ont besoin des deux.
Si vous êtes incertain, commencez avec Flash comme votre par défaut et créez une voie claire pour GLM-4.7. Laissez les routes, pas les humeurs, décider. Votre kilométrage peut varier, et c’est bon.
Je remarque toujours, dans les jours tranquilles, comment cette division réduit la fatigue décisionnelle. Rien de tape-à-l’œil—juste moins de maux de tête.
Comment je pratique réellement cette division
 Quand j’ai besoin de router les travaux rapides vers Flash et d’escalader les plus lourds vers GLM-4.7 sans surveiller les scripts, j’utilise WaveSpeed—notre propre plateforme.
Quand j’ai besoin de router les travaux rapides vers Flash et d’escalader les plus lourds vers GLM-4.7 sans surveiller les scripts, j’utilise WaveSpeed—notre propre plateforme.
Nous l’avons construite pour gérer le commutation de modèles, la concurrence, et les appels par lots proprement, afin que le modèle « Flash en premier, escalader si nécessaire » reste simple au lieu d’être fragile.
Si vous exécutez beaucoup de petits appels et ne voulez pas que la logique de routage devienne une autre chose à maintenir, essayez Wavespeed !
FAQ : GLM-4.7-Flash vs GLM-4.7
1. Quelles sont les différences principales entre GLM-4.7-Flash et GLM-4.7 ?
GLM-4.7-Flash est une variante légère et optimisée de GLM-4.7. Il réalise une inférence plus rapide et un coût inférieur en réduisant le nombre d’experts actifs, en simplifiant le routage, et en appliquant des optimisations d’efficacité. GLM-4.7 conserve un backbone plus grand et des capacités de raisonnement plus fortes, excelle dans le raisonnement multi-étapes complexe, la cohérence du long contexte, et l’appel d’outils précis.
En bref : Flash échange une certaine intelligence contre la vitesse ; GLM-4.7 privilégie la profondeur et la fiabilité.
2. Quel modèle est plus rapide, et dans quels scénarios la différence de vitesse est-elle la plus notable ?
GLM-4.7-Flash a un temps-au-premier-token (TTFT) et une latence par token significativement plus faibles. Il brille dans les cas d’utilisation à haut débit et à faible latence tels que les interactions UI en temps réel, la synthèse de contenu, la génération de métadonnées, et le prototypage rapide.
GLM-4.7 a une surcharge de démarrage plus élevée et un calcul plus lourd mais reste plus stable pour les résultats longs ou les séquences d’appels d’outils complexes. En pratique, Flash est notablement plus rapide pour les résultats courts à moyens (moins de 500 tokens).
3. Quel modèle est plus fort en intelligence et raisonnement ?
GLM-4.7 surpasse Flash dans le raisonnement multi-étapes, la fiabilité du code, l’utilisation d’outils, et les tâches de long contexte. Exemples :
- SWE-bench Verified : GLM-4.7 mène dans l’édition multi-fichiers et les correctifs coordonnés.
- LiveCodeBench / τ²-Bench : GLM-4.7 offre une code de meilleure qualité, surtout pour les scénarios de raisonnement profond.
Flash convient aux édits à fichier unique ou aux tâches d’assistance qui tolèrent l’examen humain, mais se dégrade plus rapidement sur les longues chaînes de raisonnement ou les invites denses.
4. Comment se comparent la longueur de contexte et les limites de sortie ?
Les deux modèles partagent des fenêtres de contexte similaires, mais GLM-4.7 maintient une meilleure cohérence et suivi des instructions sur les contextes très longs (>32k tokens) ou les invites denses. Flash se dégrade plus rapidement sous une longueur ou densité extrême d’invitation—associez-le au chunking ou à RAG pour de meilleurs résultats.
5. Comment devrais-je choisir en fonction de la tarification et du contrôle des coûts ?
GLM-4.7-Flash offre généralement des quotas gratuits plus élevés et une tarification inférieure ou même zéro par token, ce qui le rend idéal pour le prototypage, les tâches de base, et les appels à haut volume et à faible risque. GLM-4.7 a des coûts par token plus élevés mais une meilleure valeur pour les tâches critiques.
Recommandation : utiliser Flash par défaut, escalader vers GLM-4.7 pour les travaux complexes, et toujours fixer les limites de tokens et la mise en cache pour éviter les dépenses excessives.
Articles associés

Seedance 2.0 arrive bientôt : Le modèle vidéo nouvelle génération de ByteDance avec audio natif

Guide Complet Seedance 2.0 : Création Vidéo Multimodale

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1 : La Comparaison Ultime de la Génération Vidéo

Guide Complet Seedream 5.0-Preview : Génération d'Images Intelligente

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image : Comparaison Complète
