Exécuter GLM-4.7-Flash Localement : Configuration Ollama, Mac & Windows

Bonjour, je suis Dora. Il y a quelques jours, une petite friction m’a poussée à faire ceci : j’attendais constamment les complétions distantes pour de petites tâches de rédaction. Pas des minutes, juste assez de délai pour que je me dérive vers l’email et que je perde le fil. La semaine dernière (janvier 2026), j’ai essayé d’exécuter GLM-4.7-Flash localement pour voir si réduire ces quelques secondes m’aiderait réellement à penser plus clairement.
Version courte : oui, mais pas pour les raisons les plus spectaculaires. GLM-4.7-Flash ressemblait plus à un assistant fiable qu’à un modèle vedette. Il est assez rapide pour me maintenir dans le flux, et léger assez pour s’exécuter sur un ordinateur portable sans le surcharger. Je vais partager ce qui a fonctionné, où ça a pataugé, et la configuration qui a gardé les choses ennuyeuses, d’une bonne façon.
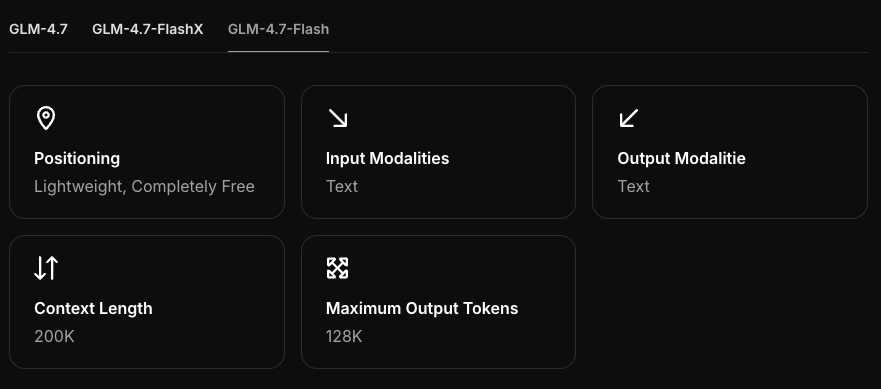
Configuration matérielle requise
GPU / RAM minimum
J’ai exécuté GLM-4.7-Flash sur trois machines :
- MacBook Pro M3 Pro (CPU 12 cœurs / GPU 18 cœurs, 36 Go RAM)
- Mac mini M2 (24 Go mémoire unifiée)
- Bureau Windows avec RTX 4090 (24 Go VRAM)
À partir de ces tests, un seuil pratique :
- CPU uniquement (Mac/Windows/Linux) : 16 Go de mémoire système fonctionne, 32 Go est plus agréable. Attendez-vous à des premiers tokens plus lents.
- Apple Silicon (Metal) : 16 Go de mémoire unifiée est utilisable avec une quantification 4-bit/5-bit et un contexte modeste (2-4 K). 8 Go semblait étroit.
- NVIDIA : 8-12 Go VRAM est le minimum que j’essaierais pour un quant 4-bit. 16 Go+ est plus confortable.
GLM-4.7-Flash ressemble à un modèle de taille moyenne (pensez à moins de 10-12B params). En 4-bit, vous regardez généralement environ 5-6 Go de mémoire d’appareil plus le cache KV. Si vous poussez des contextes longs ou plusieurs invites parallèles, la mémoire augmente.
Spécifications recommandées
Si vous voulez cette sensation « toujours réactive » :
- Apple Silicon : M3 ou plus récent avec 24-36 Go de mémoire unifiée : gardez un contexte 4-8K.
- NVIDIA : 24 Go VRAM (par exemple, 3090/4090) donne de la marge pour un contexte plus élevé et de la concurrence.
- Stockage : SSD rapide : les modèles se chargent plus rapidement et l’échange est moins important.
J’ai remarqué que le modèle cesse de sembler « flashy » quand la pression mémoire augmente, les page-outs ou les débordements VRAM ajoutent un léger tremblement qui brise le flux. Un peu d’espace supplémentaire fait une grande différence.
Configuration Ollama
J’ai utilisé Ollama parce que cela garde les exécutions locales simples et cohérentes sur les machines. Le contexte de la version compte ici.
Installer Ollama 0.14.3+
- macOS : brew install ollama (ou mettre à jour avec brew upgrade ollama).
- Windows : utilisez le programme d’installation officiel du site Ollama.

- Linux : suivez le script curl de la documentation.
Je suis sur la version 0.14.3 à partir de ce test (janvier 2026). Les versions plus récentes changent parfois les backends par défaut ou le comportement de quantification, donc je m’en tiens à la version qui est stable pour moi jusqu’à ce que j’aie une raison de sauter.
Télécharger et exécuter GLM-4.7-Flash
Deux chemins ont fonctionné pour moi :
-
Si votre bibliothèque Ollama inclut une version officielle de GLM-4.7-Flash :
- ollama pull glm-4.7-flash
- ollama run glm-4.7-flash
-
Si elle n’apparaît pas (cela s’est produit sur une machine) :
- Créez un Modelfile qui pointe vers un artefact GGUF connu ou compatible pour GLM-4.7-Flash.
- Exemple de Modelfile (simplifié) :
- FROM ./glm-4.7-flash-q4.gguf
- Ajoutez des modèles d’invite uniquement si vous savez que vous en avez besoin : je l’ai laissé minimal.
- Ensuite : ollama create glm-4.7-flash-local -f Modelfile
- Exécuter : ollama run glm-4.7-flash-local
Notes d’utilisation :
- Le premier chargement est plus lent car il réchauffe les caches.
- Je garde num_ctx conservateur (4K ou 8K) sauf si je résume un brouillon de livre. Les contextes plus grands semblent agréables, mais ils sont gourmands en mémoire et n’aident pas toujours à la qualité pour la rédaction au quotidien.
- Si les générations semblent hésitantes, essayez de réduire la température à 0,6-0,7 et d’augmenter légèrement top_p : cela a resserré les résultats pour moi sans perdre de vitesse.
Références : la documentation Ollama est solide pour les drapeaux spécifiques à la plateforme et les backends actuels.

Performance Mac
Références M4 / M3 / M2
Ce ne sont pas des notes de laboratoire, juste des exécutions régulières sur des tâches d’écriture et de codage léger, température 0,7, contexte 4K, quant 4-bit :
- M4 (machine empruntée, 48 Go) : 60-85 tok/s une fois chaud. Premier token en ~350-500 ms.
- M3 Pro (36 Go) : 35-55 tok/s. Premier token en ~500-800 ms.
- M2 (24 Go) : 20-30 tok/s. Premier token en ~900-1200 ms.
Prenez les gammes comme une vérification d’ambiance. J’ai poussé quelques contextes 8K sur le M3 Pro : la vitesse a chuté ~20-30% mais est restée utilisable pour la rédaction. Sur le M2, les contextes longs ont dépassé ma ligne « se sent collant ». Je l’ai gardé à 2-4K là.
Optimisation mémoire
Ce qui a aidé le plus sur macOS :
- Gardez moins d’onglets de terminal exécutant les modèles. Évident, oui, mais j’oublie trop.
- Contexte de la bonne taille. 4K est un point idéal pour moi.
- Utilisez le quant 4-bit quand vous le pouvez. 5-bit semblait similaire en qualité pour mon utilisation, mais plus lent.
- Fermez les applications qui prennent du temps GPU (éditeurs vidéo, certains onglets de navigateur avec WebGL).
J’ai également remarqué que l’utilisation d’une invite système stable réduisait le rework. Pas plus rapide sur papier, mais moins de nouvelles tentatives signifie une meilleure « vitesse ressentie ». Une petite invite comme : « Soyez concis, utilisez un anglais simple, pas de ton marketing. » Elle correspond aux forces du modèle.
Windows + NVIDIA
Configuration RTX 3090 / 4090
Sur le 4090 (24 Go), GLM-4.7-Flash semblait constamment rapide :
- Quant 4-bit, contexte 4-8K : 120-220 tok/s après chauffe.
- Premier token : ~250-400 ms.
- Invites parallèles : 2-3 flux avant de voir des tremblement.
Un ami l’a exécuté sur un 3090 (24 Go) et a vu ~15-25% de débit inférieur avec des paramètres similaires. Si vous dépassez un contexte 8K ou conservez plusieurs réponses à la fois, vous atteindrez la marge VRAM. Je fais généralement marche arrière à 4-6K et je garde les lots petits.
Configuration CUDA
Ce qui compte en pratique :
- Pilote NVIDIA récent (une installation propre a aidé une machine qui tremblait).
- CUDA 12.x et runtime correspondant si vous sortez d’Ollama (vLLM/SGLang). Pour Ollama lui-même, vous n’avez pas toujours besoin d’un kit d’outils complet, mais les pilotes à jour sont non négociables.
- Paramètres d’alimentation : définissez votre GPU sur « Préférer les performances maximales ». Cela ressemble à un conseil de joueur, mais cela a arrêté l’étranglement d’horloge pendant les longues exécutions.
Si vous rencontrez des erreurs de chargement ou des chutes difficiles vers le processeur, je vérifierais :
- Alignement de version du pilote avec le runtime CUDA.
- Si un antivirus analyse votre répertoire de modèles (c’est arrivé : c’était bête : c’était lent).
Référence : Le tableau de compatibilité pilote-CUDA d’NVIDIA vaut le coup d’être vérifié rapidement avant de vous enfoncer une heure dans le débogage.
vLLM / SGLang
J’ai essayé GLM-4.7-Flash avec vLLM et SGLang quand je voulais plus de contrôle sur le batching et les points de terminaison de style serveur.
vLLM
- Installation : Python récent, PyTorch compatible CUDA, puis pip install vllm.
- Exécuter :
python -m vllm.entrypoints.openai.api_server --model <your_glm_flash_id> --dtype auto --max-model-len 4096 - Pourquoi je l’ai utilisé : API stable compatible OpenAI, débit solide pour les flux multi-utilisateurs ou multi-onglets.
SGLang
- Installation : pip install sglang
- Exécuter :
python -m sglang.launch_server --model <your_glm_flash_id> --context-length 4096 - Pourquoi je l’ai utilisé : le streaming à faible latence semblait rapide, et il s’entendait bien avec les petites tâches d’acheminement.
Les deux veulent un chemin de modèle approprié ou un identifiant de repo HF. Si GLM-4.7-Flash n’est pas sur votre index par défaut, vous devrez les pointer vers un GGUF local ou un format de poids compatible. Aussi : faites correspondre les versions CUDA et pilote, ou vous chasserez les erreurs de noyau opaques. J’ai gardé dtype sur auto et j’ai forcé fp16 uniquement quand je savais que j’avais de la VRAM à revendre.
Pour mes sessions d’écriture mono-utilisateur, Ollama est resté plus simple. vLLM/SGLang avait du sens quand j’ai testé des outils qui nécessitaient un point de terminaison de style OpenAI.
Dépannage
Échecs de chargement de modèle
Ce que j’ai vu :
- « manque de mémoire » pendant le chargement. Correction : basculez vers un quant plus petit (par exemple, 4-bit), abaissez num_ctx, ou fermez les applications gourmandes en GPU.
- « pas de backend compatible » sur Windows. Correction : mettre à jour le pilote GPU : assurez-vous que vous n’avez pas installé un PyTorch CPU uniquement si vous utilisez vLLM/SGLang : redémarrez après les mises à niveau du pilote.
- Modèle non trouvé dans Ollama. Correction : créez un Modelfile et ollama create : ou tirez du tag de repo exact s’il existe.
Si un modèle bascule silencieusement vers le processeur, le signe est le bruit du ventilateur (ou son absence) plus des tokens/sec beaucoup plus lents. J’ai appris à vérifier l’utilisation des appareils avant de supposer que le modèle était devenu « pire ».
Correctifs d’inférence lente
Les petits changements qui ont compté plus que je ne m’y attendais :
- Contexte de la bonne taille. Réduire de moitié le contexte accélère souvent plus que de bricoler l’échantillonnage.
- Réchauffez le cache. Une courte exécution rapide améliore la suivante.
- Réduisez les flux parallèles. La concurrence semble efficace jusqu’à ce que le cache KV vous fasse trébucher.
- Pour NVIDIA : définissez le mode de performances élevées, fermez les applications en superposition, et arrêtez les encodeurs en arrière-plan.
- Sur macOS : gardez le chargeur dans : certains ordinateurs portables se décalent lorsque sur batterie.
Un de plus : j’ai cessé de chasser les max tokens/sec. La meilleure métrique pour moi était « première pensée utilisable ». GLM-4.7-Flash m’a donné cela rapidement quand j’ai gardé les invites concentrées et les contextes raisonnables.
 Si vous aimez la vitesse de GLM-4.7-Flash mais n’aimez pas garder à l’œil les pilotes, les versions CUDA, ou les bizarreries du backend, essayez WaveSpeed - notre propre plateforme axée sur l’inférence stable et rapide sans l’ajustement de bas niveau. Vous obtenez une latence prévisible sans vous soucier des fichiers de modèles, des formats de quant, ou de la compatibilité GPU.
Si vous aimez la vitesse de GLM-4.7-Flash mais n’aimez pas garder à l’œil les pilotes, les versions CUDA, ou les bizarreries du backend, essayez WaveSpeed - notre propre plateforme axée sur l’inférence stable et rapide sans l’ajustement de bas niveau. Vous obtenez une latence prévisible sans vous soucier des fichiers de modèles, des formats de quant, ou de la compatibilité GPU.
Articles associés

Seedance 2.0 arrive bientôt : Le modèle vidéo nouvelle génération de ByteDance avec audio natif

Guide Complet Seedance 2.0 : Création Vidéo Multimodale

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1 : La Comparaison Ultime de la Génération Vidéo

Guide Complet Seedream 5.0-Preview : Génération d'Images Intelligente

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image : Comparaison Complète
