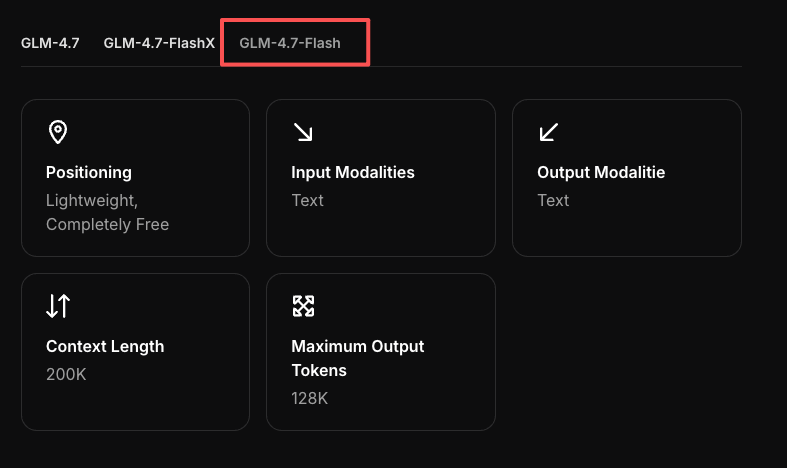
GLM-4.7-Flash API : Guide de démarrage rapide pour les complétions de chat et le streaming

Bonjour, je m’appelle Dora. La semaine dernière, j’ai rencontré un petit obstacle : une tâche de résumé de brouillon qui semblait plus lourde qu’elle ne devrait l’être. Les outils que j’utilise normalement étaient soit trop lents, soit trop complexes pour leur propre bien. Je voulais quelque chose de rapide et prévisible, même si ce n’était pas spectaculaire.
J’ai donc donné une chance appropriée à l’API GLM-4.7-Flash (janvier 2026). Je ne cherchais pas un “wow”. Je voulais des requêtes propres, des réponses rapides et des paramètres qui se comportent comme ils le disent. Voici ce que j’ai mis en place, ce qui a aidé, où cela a buté, et pourquoi je l’utiliserais à nouveau quand j’ai besoin de vitesse sans prise de tête.
Obtenir Votre Clé API
J’ai commencé simplement : obtenir une clé, faire une requête, voir si les bases semblent sensées. J’apprécie les API qui ne cachent pas les leviers. Pour le contexte, GLM-4.7-Flash fait partie de la plus large famille de modèles GLM de Zhipu AI, qui encadre bon nombre des décisions de conception autour de la vitesse et de la prévisibilité.

Présentation du Tableau de Bord WaveSpeed
J’ai utilisé le tableau de bord WaveSpeed, qui enveloppe l’accès à l’API GLM-4.7-Flash. Le flux était assez simple :
- Créer un projet (j’ai nommé le mien “flash-notes”).
- Générer une clé serveur et un jeton client léger. J’ai seulement utilisé la clé serveur dans mes scripts locaux.
- Consulter le panneau d’utilisation pour identifier les limites de débit par défaut. Le mien affichait un plafond de rafale modeste et un quota par minute, suffisant pour les tests mais pas pour une augmentation de production.
Une petite chose que j’ai aimée : le tableau de bord affiche les erreurs 4xx/5xx récentes avec des horodatages. Quand j’ai atteint les limites plus tard, je n’ai pas eu à deviner. Si vous faites du travail d’équipe, la visibilité des clés basée sur les rôles a aidé : j’ai conservé la clé capable d’écrire dans un fichier .env et j’ai effectué une rotation une fois pendant la semaine pour vérifier que la révocation fonctionnait (c’était le cas, instantanément).
Requête de Base
Mon premier point de repère était le même que celui que j’utilise pour tout nouveau modèle : une invitation courte, une réponse courte et aucune surprise dans le JSON.
Le schéma API suit le même modèle de complétions de chat décrit dans le guide officiel de l’API GLM-4.7, ce qui signifiait que je n’avais pas besoin de réapprendre la sémantique des requêtes.
Exemple curl
Voici l’appel le plus simple qui a fonctionné de manière cohérente pour moi. Le nom du point de terminaison peut varier selon les fournisseurs : c’est le modèle que j’ai utilisé lors des tests.
curl https://api.wavespeed.ai/v1/chat/completions \
-H "Authorization: Bearer $WAVESPEED_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "GLM-4.7-Flash",
"messages": [
{"role": "system", "content": "You are concise and helpful."},
{"role": "user", "content": "Summarize this in one sentence: GLM-4.7-Flash API quick test."}
],
"temperature": 0.2,
"max_tokens": 120
}'Notes de la course
- Latence: J’ai observé le premier jeton en ~200–400 ms sur une invitation courte en milieu de matinée (heure américaine). La fin à la fin était terminée en moins d’une seconde pour les courtes réponses.
- Stabilité: Les réponses étaient du JSON bien formé à chaque fois quand le streaming était désactivé.
- Coût: Je ne peux pas parler de votre plan, mais les jetons ont été signalés clairement dans les journaux d’utilisation. Cela compte quand vous poussez des itérations rapides.
Exemple Python
Pour les minuscules scripts, je préfère une seule fonction avec des clés chargées par l’environnement.
import os
import requests
API_KEY = os.getenv("WAVESPEED_API_KEY")
BASE_URL = "https://api.wavespeed.ai/v1/chat/completions"
payload = {
"model": "GLM-4.7-Flash",
"messages": [
{"role": "system", "content": "You are concise and helpful."},
{
"role": "user",
"content": "Give me 3 bullet points on maintaining a calm writing workflow."
}
],
"temperature": 0.3,
"max_tokens": 180
}
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
resp = requests.post(BASE_URL, json=payload, headers=headers, timeout=30)
resp.raise_for_status()
data = resp.json()
print(data["choices"][0]["message"]["content"]) # typical OpenAI-style schemaDeux petites réactions :
- Soulagement: Le schéma correspondait au format de complétions de chat habituel, ce qui signifiait aucune couche d’adaptateur. Je l’ai intégré dans un outil préexistant avec des changements minimes.
- Une limite: Les sorties plus longues à température plus élevée parfois déambulaient. C’est normal pour les modèles de type “Flash” : j’ai coupé avec
max_tokenset j’ai ajusté le ton via une invitation système plus stricte.
Activer le Streaming
Je n’active le streaming que lorsque je façonne du texte en direct ou quand la latence compte plus que l’exhaustivité. GLM-4.7-Flash semblait conçu pour cela : premiers jetons rapides, chunking stable une fois que les paramètres étaient correctement définis.
Configuration du Paramètre Stream
Pour activer les événements envoyés par le serveur (SSE), j’ai défini stream: true. C’est tout. Le reste est du travail de maintenance : assurez-vous que votre client lit les lignes d’événements et s’arrête à [DONE].
Version curl que j’ai utilisée:
curl https://api.wavespeed.ai/v1/chat/completions \
-H "Authorization: Bearer $WAVESPEED_API_KEY" \
-H "Content-Type: application/json" \
-N \
-d '{
"model": "GLM-4.7-Flash",
"messages": [
{"role": "user", "content": "Draft a two-sentence intro about quiet tools."}
],
"stream": true,
"temperature": 0.2,
"max_tokens": 120
}'Deux notes de terrain :
- Si vous oubliez
-N(pas de tampon) avec curl, le stream peut sembler bloqué. - Si vous obtenez un blob JSON simple au lieu d’événements, vérifiez deux fois que
streamest un booléentrueet non une chaîne.
Gérer les Chunks dans le Code
En Python, je lis ligne par ligne, parse les frames data: et m’arrête au sentinel. Ce modèle a fonctionné sans problème.
import os, json, requests
API_KEY = os.getenv("WAVESPEED_API_KEY")
BASE_URL = "https://api.wavespeed.ai/v1/chat/completions"
payload = {
"model": "GLM-4.7-Flash",
"messages": [{"role": "user", "content": "Write a calm closing paragraph."}],
"stream": True,
"temperature": 0.2,
}
with requests.post(
BASE_URL,
json=payload,
headers={
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
},
stream=True,
timeout=60
) as r:
r.raise_for_status()
for line in r.iter_lines(decode_unicode=True):
if not line or not line.startswith("data:"):
continue
data = line[len("data:"):].strip()
if data == "[DONE]":
break
try:
delta = json.loads(data)["choices"][0]["delta"].get("content", "")
print(delta, end="", flush=True)
except (KeyError, json.JSONDecodeError):
# Skip malformed or heartbeat frames gracefully
continue
print() # newlineCe qui m’a un peu surpris : le timing des chunks était régulier. J’ai essayé quelques invitations plus longues et j’ai toujours obtenu un rythme prévisible. Le streaming n’a pas économisé le temps d’horloge sur très courtes réponses, mais cela a réduit mon sentiment d’attente, ce qui compte quand je modifie directement dans le terminal.
Référence des Paramètres
Je n’ajuste que quelques leviers au quotidien. Avec l’API GLM-4.7-Flash, ceux-ci se sont comportés comme prévu.
temperature / top_p / max_tokens
- temperature: Je gardais cela entre 0,1 et 0,4 pour les tâches de style production. Les nombres plus bas donnaient une formulation plus stricte et moins imaginative, ce qui est bien pour les résumés et le texte de support. Si vous dérivez au-dessus de 0,7, attendez-vous à des tangentes.
- top_p: J’ai laissé top_p autour de 0,9. Quand je l’ai resserré à 0,6 avec une température basse, les sorties semblaient coupées, utiles pour les listes à puces, moins pour l’écriture nuancée.
- max_tokens: C’était ma barrière de sécurité. Pour les tâches de courte forme, 150–250 gardaient les coûts rangés et prévenaient les bavardages. Pour les plans, 600–800 était suffisant. Si le modèle s’arrête tôt, c’est généralement cela, pas un bogue.
Une petite configuration qui a bien fonctionné pour moi quand j’avais besoin de réponses nettes et factuelles :
{
"model": "GLM-4.7-Flash",
"temperature": 0.2,
"top_p": 0.9,
"max_tokens": 200
}Pourquoi cela compte en pratique : quand vous voulez de la vitesse, vous ne voulez pas de réécriture. Une température conservatrice avec un max_tokens généreux mais pas illimité m’a épargné d’avoir à exécuter le même appel deux fois juste pour ajuster la formulation.
Erreurs Courantes
 J’ai gardé un petit carnet à côté de moi pendant les tests. Deux erreurs se sont présentées assez souvent pour mériter d’être mentionnées clairement.
J’ai gardé un petit carnet à côté de moi pendant les tests. Deux erreurs se sont présentées assez souvent pour mériter d’être mentionnées clairement.
429 Limite de Débit
Ce que j’ai vu:
- Les rafales de requêtes parallèles (5–10 à la fois) déclenchaient parfois un 429. C’est arrivé plus dans la première minute d’une clé fraîche.
Ce qui a aidé:
- Backoff: délai exponentiel jittered (par exemple, 200 ms, 400 ms, 800 ms, jusqu’à ~3 s) a dégagé les pics sans que je ne les supervise.
- Queues: coalescer les invitations quasi-identiques dans une fenêtre de lot courte (100–200 ms) a coupé mon taux de pointe d’environ 30% sans changer l’UX.
- Vérifications du tableau de bord: le panneau d’utilisation a confirmé quand j’étais le problème. Aucun mystère là, ce que j’ai apprécié.
Qui cela déclenche: équipes câblant GLM-4.7-Flash dans les aperçus UI et les crochets serveur en même temps. Si cela compte, demandez à votre fournisseur des plafonds par minute plus élevés ou utilisez une file d’attente légère en mémoire.
Réponse JSON Invalide
Ce que j’ai vu:
- Quand le streaming est activé, certains clients essaient d’analyser chaque frame
data:en tant que JSON complet. Ce n’est pas ainsi que fonctionne SSE. Les frames sont partiels. - Une fois, avec une connexion bruyante, j’ai obtenu une ligne d’événement tronquée qui cassait les parseurs stricts.
Ce qui a aidé:
- Gardez votre parseur: analysez seulement le JSON après
data:et attendez-vous à ce qu’il contienne un petit delta, pas le message complet. Arrêtez-vous à[DONE]. - Timeouts: gardez un délai d’attente raisonnable mais évitez de tuer un stream pour un seul frame malformé.
- Si vous avez besoin d’un JSON non-stream : désactivez le stream et vous obtiendrez généralement un objet JSON unique et propre. Dans mes exécutions, le mode non-stream n’a jamais produit de JSON malformé.
Un autre petit accroc mineur : si votre proxy ou serveur injecte des journaux dans stdout, cela peut polluer le stream. Gardez les journaux séparés des pipes de réponse.
Après tout ce test, la raison pour laquelle j’ai adhéré à WaveSpeed est assez simple : je ne voulais pas penser à la tuyauterie.
 Nous avons construit WaveSpeed pour être la couche ennuyeuse et fiable entre votre code et des modèles rapides comme GLM-4.7-Flash. Des points de terminaison propres, un comportement prévisible et un tableau de bord qui vous dit ce qui s’est réellement passé quand quelque chose s’est mal passé—limites de débit, erreurs, utilisation—sans conjecture.
Nous avons construit WaveSpeed pour être la couche ennuyeuse et fiable entre votre code et des modèles rapides comme GLM-4.7-Flash. Des points de terminaison propres, un comportement prévisible et un tableau de bord qui vous dit ce qui s’est réellement passé quand quelque chose s’est mal passé—limites de débit, erreurs, utilisation—sans conjecture.
Si vous câblez Flash dans des résumés, des brouillons, des aperçus UI ou des tâches en arrière-plan et que vous voulez juste qu’il reste en dehors du chemin, c’est exactement l’écart que nous essayons de combler. → Cliquez ici!
Articles associés

Seedance 2.0 arrive bientôt : Le modèle vidéo nouvelle génération de ByteDance avec audio natif

Guide Complet Seedance 2.0 : Création Vidéo Multimodale

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1 : La Comparaison Ultime de la Génération Vidéo

Guide Complet Seedream 5.0-Preview : Génération d'Images Intelligente

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image : Comparaison Complète
