GLM-4.7-Flash : Date de sortie, niveau gratuit et fonctionnalités clés (2026)

Salut, je suis Dora.
Récemment, GLM-4.7-Flash n’arrêtait pas d’apparaître dans les discussions de gens en qui j’ai confiance, généralement mentionné avec un petit haussement d’épaules : « assez rapide pour ne pas vous ralentir ». Cette phrase m’a marquée. Je ne chasse pas les modèles à la mode en ce moment : je chasse les outils qui rendent le travail quotidien plus léger. Tu me comprends ?
J’ai donc donné à GLM-4.7-Flash quelques jours d’essai dans mon stack (20-21 janvier 2026). Des prompts courts, de petits scripts API, quelques tâches par lot. Rien de dramatique. La question que je me posais était simple : est-ce un complément pratique, ou juste un autre nom de modèle qui passe dans la chronologie ?
Qu’est-ce que GLM-4.7-Flash ?
GLM-4.7-Flash est une variante axée sur la vitesse de la famille GLM-4.7 de Zhipu AI. Pensez-y comme le modèle vers lequel vous vous tournez quand vous voulez des générations réactives et à faible latence sans surcharge de raisonnement lourd. Il ne cherche pas à dominer les benchmarks longs ou à débattre de philosophie : il vise à fournir de bonnes réponses rapidement et à bas coût.
Qui l’a créé (Zhipu AI / Z.ai)
 Zhipu AI (également connu sous le nom Z.ai) est l’équipe derrière la série GLM. Si vous avez essayé les anciens modèles GLM, la nomenclature vous sera familière : le numéro reflète la génération, et le suffixe (Flash, Standard, etc.) indique les compromis. Leur documentation est directe et régulièrement mise à jour : si vous intégrez, mettez un marque-page sur la documentation API officielle du portail développeur de Zhipu.
Zhipu AI (également connu sous le nom Z.ai) est l’équipe derrière la série GLM. Si vous avez essayé les anciens modèles GLM, la nomenclature vous sera familière : le numéro reflète la génération, et le suffixe (Flash, Standard, etc.) indique les compromis. Leur documentation est directe et régulièrement mise à jour : si vous intégrez, mettez un marque-page sur la documentation API officielle du portail développeur de Zhipu.
J’ai utilisé les modèles Zhipu de temps en temps au cours de l’année écoulée quand j’avais besoin d’une couverture multilingue et de résultats stables et prévisibles. GLM-4.7-Flash poursuit cette tendance, avec simplement plus d’attention portée à la vitesse et au débit.
Flash vs Standard, positionnement
Voici comment j’ai senti les différences en pratique :
- Flash : optimisé pour la vitesse, calcul inférieur par requête, excellent pour les points de terminaison à haut volume, les assistants UI et la classification ou l’étiquetage par lot. J’ai remarqué qu’il était plus heureux avec des prompts concis et une structure claire.
- Standard (non-Flash) : plus lent mais plus stable sur les tâches nécessitant du raisonnement. Si je lançais une analyse multi-étapes sur Flash, il essayait, mais je pouvais voir qu’il compressait les étapes pour maintenir une faible latence.
Si vous faites un choix entre les deux, une règle simple : si la latence et le coût façonnent votre quotidien, commencez par Flash. Si la précision sur le raisonnement multi-saut est votre contrainte principale, Standard (ou une variante sœur plus grande orientée vers le raisonnement) donnera probablement de meilleurs résultats. Vous savez, choisissez votre combattant.
Lancement officiel : 19 janvier 2026
Zhipu AI a annoncé GLM-4.7-Flash le 19 janvier 2026. J’ai commencé à le tester le jour suivant. Le contexte de version compte avec ces modèles : les débuts sont souvent accompagnés d’itérations rapides. Si vous lisez ceci plus tard, vérifiez les notes de version dans la documentation officielle pour confirmer les éventuels changements de limites ou de comportement.
Architecture en un coup d’œil
Je n’ai pas besoin de connaître les détails internes d’un modèle pour l’utiliser, mais certains détails m’aident à estimer les coûts et où il excellera.
30B MoE, 3B paramètres actifs
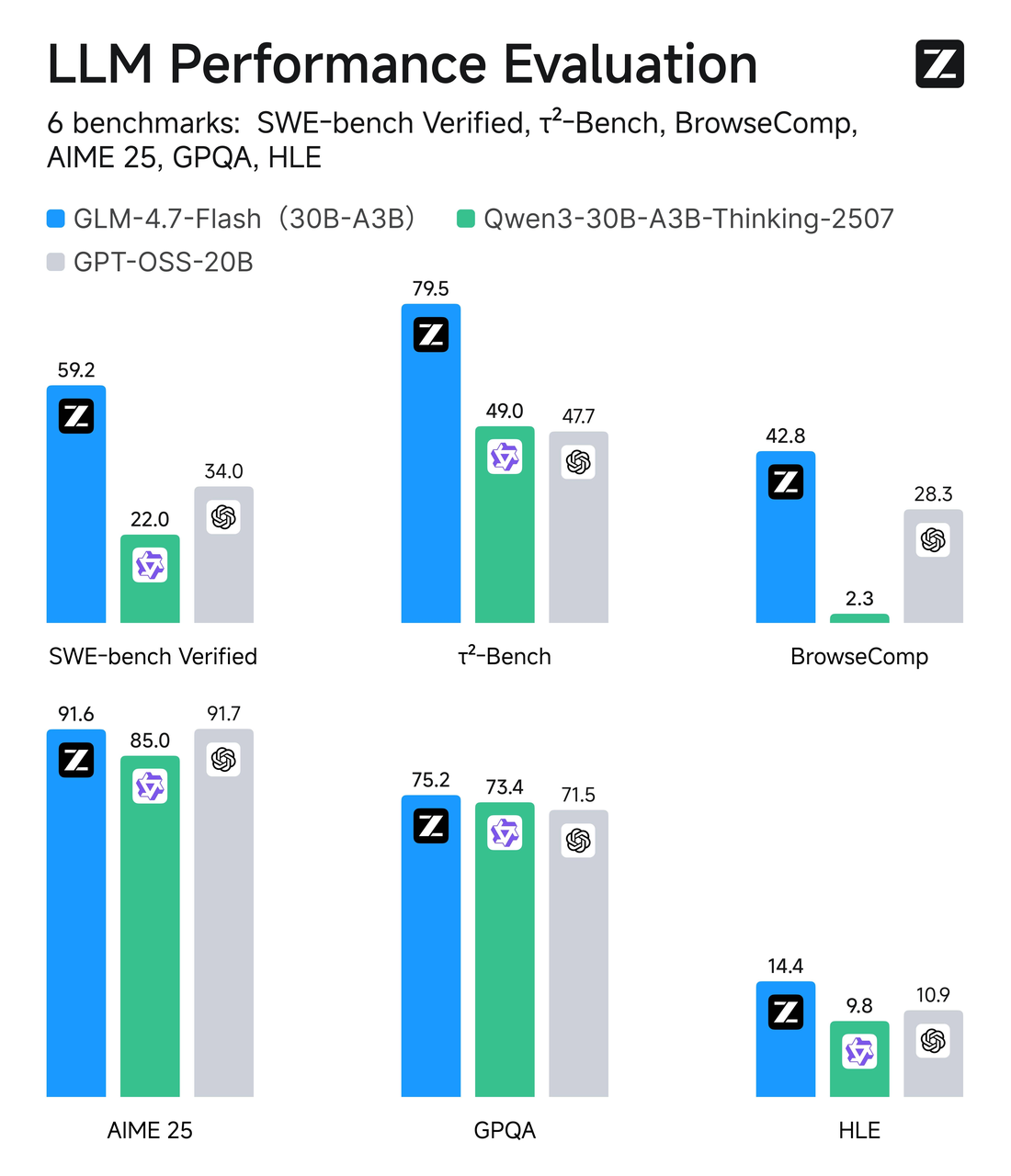 GLM-4.7-Flash utilise une conception Mixture-of-Experts (MoE) avec un nombre de paramètres total d’environ 30B, mais seuls ~3B experts sont actifs par token. En termes simples : c’est un modèle large avec routage sélectif. La plupart du temps, seule une petite tranche du réseau travaille sur votre token, ce qui maintient l’inférence légère.
GLM-4.7-Flash utilise une conception Mixture-of-Experts (MoE) avec un nombre de paramètres total d’environ 30B, mais seuls ~3B experts sont actifs par token. En termes simples : c’est un modèle large avec routage sélectif. La plupart du temps, seule une petite tranche du réseau travaille sur votre token, ce qui maintient l’inférence légère.
En pratique, MoE vous donne souvent une sensation de « cerveau plus grand en cas de besoin » sans toujours payer le prix total du calcul. Lors de mes tests, cela s’est traduit par des résultats réactifs même en cas de charge, et une latence plus cohérente que les modèles denses d’échelle rapportée similaire. Ce n’est pas de la magie, juste un moyen intelligent d’équilibrer la capacité et la vitesse.
MLA (Multi-Headed Latent Attention)
La documentation mentionne MLA (Multi-Headed Latent Attention). Ma conclusion en tant qu’utilisateur : c’est une stratégie d’attention visant à être plus efficace que l’auto-attention complète classique, en particulier dans les contextes plus longs. Je n’ai pas poussé les limites du contexte long ici : mes exécutions étaient principalement en dessous de quelques milliers de tokens. Pourtant, l’empreinte mémoire est restée raisonnable, et je n’ai pas vu la baisse lente habituelle de la latence à mesure que les prompts passaient de « court » à « moyen ».
Si vous planifiez des flux de travail lourds en récupération ou des boucles d’agents, MLA plus MoE est un signal utile : ce modèle est conçu pour maintenir le débit élevé plutôt que de poursuivre la profondeur maximale de raisonnement à un seul coup.
API gratuite — Ce qui est inclus
L’accès gratuit était remarquable. Je suis prudent ici parce que les niveaux gratuits changent, parfois hebdomadairement. Ce que je partage, c’est ce que j’ai observé le 20-21 janvier 2026, et ce que la documentation de Zhipu suggérait au lancement. Vérifiez toujours les limites avant de l’intégrer à la production.
 En bref : l’API gratuite m’a permis de faire de vraies requêtes avec des paramètres raisonnables. J’ai exécuté de petits travaux sans frapper un mur de paiement au milieu du test. Cela a réduit les frictions pour l’essayer dans un script en direct plutôt que dans un terrain de jeu.
En bref : l’API gratuite m’a permis de faire de vraies requêtes avec des paramètres raisonnables. J’ai exécuté de petits travaux sans frapper un mur de paiement au milieu du test. Cela a réduit les frictions pour l’essayer dans un script en direct plutôt que dans un terrain de jeu.
Limites de débit et concurrence
Ce que j’ai observé :
- Concurrence : j’ai pu confortablement exécuter plusieurs requêtes parallèles à partir d’un petit worker sans déclencher d’erreurs. Dans mes tests, 5-10 appels simultanés sont restés stables. Quand j’ai pics plus haut, j’ai commencé à voir des limitations, ce qui est attendu sur un niveau gratuit.
- Débit : les prompts courts (classification, petites transformations) ont renvoyé en moins d’une seconde à quelques secondes. En moyenne, j’ai vu 300-900 ms pour des réponses très courtes et 1,5-3 s pour des résultats modestes. La variance du réseau s’applique.
- Sécurité : l’API a répondu avec des codes d’erreur clairs quand j’ai dépassé les limites. Rien que pour cela, j’ai gagné du temps, je n’ai pas eu à deviner ce qui s’était mal passé.
Je n’ai pas poursuivi les plafonds TPS exacts : mon objectif était de voir si les petits pipelines pouvaient s’exécuter sans surveillance. C’était le cas. C’est une sensation de liberté, honnêtement. Si vous planifiez des charges de travail imprévisibles, testez avec une concurrence réaliste et construisez une logique simple de retry/backoff. Les niveaux gratuits sont généreux jusqu’à ce qu’ils ne le soient plus.
Niveau payant FlashX
Zhipu mentionne une option payante « FlashX » visant un débit plus élevé et une performance plus prévisible. Je n’ai pas déplacé mes tests vers FlashX lors de cette exécution, mais voici ce qui change généralement quand vous montez en niveau avec des fournisseurs comme celui-ci :
- Limites de débit plus élevées et garanties avec moins de limitations.
- Plus de requêtes simultanées par clé, utile pour les travaux par lot et les assistants orientés utilisateur.
- Routage prioritaire (latence de queue plus faible). C’est important quand vous vous souciez du pire 5 % des requêtes, pas seulement de la médiane.
Si vous expédiez une fonctionnalité orientée client, FlashX est le chemin plus sûr. Si vous bricolez, le niveau gratuit est suffisant pour avoir une sensation de stabilité et de travail d’intégration. Vos résultats dépendront de votre budget de latence et de la fréquence à laquelle vous faites des lots.
Meilleurs cas d’utilisation
J’ai essayé quelques tâches réelles. Rien de glamour, juste ce qui se présente dans ma semaine.
- Assistants d’interface où le décalage tue l’ambiance. Pensez : relectures en ligne, petites clarifications, brefs suivi. GLM-4.7-Flash a maintenu l’interface immédiate.
- Transformations de texte par lot. J’ai exécuté un petit CSV (quelques milliers de lignes) pour des ajustements de ton et des étiquettes de catégorie. Le modèle est resté cohérent et ne s’est pas dérivé au milieu du chemin.
- Scaffolds de rédaction. Contours, expansions point par point, brefs résumés. Il a bien géré la structure quand je lui ai donné des instructions claires. Comme avoir un mini-assistant que vous n’avez pas besoin de soudoyer.
- Résumés de récupération avec des fenêtres de contexte courtes. Quand j’ai injecté 2-4 extraits, il a répondu proprement sans halluciner des ponts bizarres. Avec un contexte long et désordre, il a essayé d’être utile mais a parfois compressé trop agressivement.
- Commentaires de code « premier passage » ou docstrings. Pas de refactorisation profonde. Juste clarifier l’intention et le nommage, rapidement et utilement.
Où je ne l’utiliserais pas :
- Analyse multi-saut avec des cas limites où la précision importe plus que la vitesse. Je me tournerais vers un modèle de raisonnement plus lourd.
- Génération longue où vous avez besoin de ton stable et de couture factuelle profonde sur des milliers de tokens. Flash peut le faire, mais cela semble déplacé.
Pourquoi c’est important : les modèles rapides qui ne détruisent pas votre budget ouvrent des fonctionnalités que vous coupiriez autrement. Si votre produit a besoin de douzaines de petits appels de modèle par session, la latence rasée et le calcul inférieur par appel s’ajoutent. De petits gains, grand bénéfice.
💡 Pour rendre le fonctionnement de modèles comme GLM-4.7-Flash plus facile et plus fiable dans les flux de travail réels, j’utilise WaveSpeed — notre propre plateforme qui gère les requêtes API, la concurrence et les travaux par lot en douceur, afin que vous puissiez vous concentrer sur les résultats au lieu de surveiller les scripts.
Essayez WaveSpeed →
 Une petite note des tranchées : ma première heure n’a pas été plus rapide. J’ai joué avec la structure du prompt, la température et les tokens max. Après quelques exécutions, j’ai trouvé un motif : prompt système court, format de sortie explicite, contraintes claires. Cela a réduit à la fois le temps et l’effort mental. Ce n’était pas de la magie : c’était de la mise en place.
Une petite note des tranchées : ma première heure n’a pas été plus rapide. J’ai joué avec la structure du prompt, la température et les tokens max. Après quelques exécutions, j’ai trouvé un motif : prompt système court, format de sortie explicite, contraintes claires. Cela a réduit à la fois le temps et l’effort mental. Ce n’était pas de la magie : c’était de la mise en place.
Qui d’autre a lancé un test « rapide de 10 minutes » de GLM-4.7-Flash (ou tout modèle Flash) et a cligné des yeux pour trouver l’horloge disant minuit ? Déposez votre record personnel — et le changement d’une seule demande qui l’a finalement fait se comporter — dans les commentaires.
Articles associés

Seedance 2.0 arrive bientôt : Le modèle vidéo nouvelle génération de ByteDance avec audio natif

Guide Complet Seedance 2.0 : Création Vidéo Multimodale

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1 : La Comparaison Ultime de la Génération Vidéo

Guide Complet Seedream 5.0-Preview : Génération d'Images Intelligente

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image : Comparaison Complète
