Qu'est-ce que Z-Image-Turbo ? Le modèle texte-vers-image ultra-rapide de 6B expliqué

Salut, les gars. Je m’appelle Dora. Ce jour-là, je suis tombée sur Z-Image-Turbo après un petit problème : j’avais besoin d’un texte propre et lisible à l’intérieur d’une image, et ma configuration habituelle me donnait toujours des lettres ondulées. Pas inutilisable, mais toujours un peu décalé, comme un panneau peint à la hâte. J’ai continué à voir des notes sur un modèle qui gérait le texte nativement et fonctionnait sur une carte 16 Go sans problème. Alors la semaine dernière (février 2026), j’ai essayé Z-Image-Turbo sur ma propre machine et via une API. En résumé : c’est rapide, c’est pratique, et ce n’est pas un spectacle. Cette combinaison a retenu mon attention.
Qu’est-ce que Z-Image-Turbo ?
 Z-Image-Turbo est un modèle de génération d’images open-source avec 6 milliards de paramètres, conçu pour une itération rapide et un rendu de texte lisible. Il vise le point doux que beaucoup d’entre nous recherchent réellement : des visuels assez bons, une typographie fiable, et une configuration qui ne force pas un poste de travail complet. Il prend en charge les invites bilingues (anglais et chinois), et il est réglé pour les courts calendriers d’échantillonnage, c’est ainsi qu’il maintient la latence basse.
Z-Image-Turbo est un modèle de génération d’images open-source avec 6 milliards de paramètres, conçu pour une itération rapide et un rendu de texte lisible. Il vise le point doux que beaucoup d’entre nous recherchent réellement : des visuels assez bons, une typographie fiable, et une configuration qui ne force pas un poste de travail complet. Il prend en charge les invites bilingues (anglais et chinois), et il est réglé pour les courts calendriers d’échantillonnage, c’est ainsi qu’il maintient la latence basse.
Je l’ai testé localement et via un point de terminaison hébergé. Localement, il fonctionnait sur un GPU 16 Go sans jugglerie d’appareils. Via l’API, je pouvais pousser des images uniques à un taux régulier par image sans me soucier de l’ajustement des lots. Ce n’est pas un modèle qui essaie de surpasser les modèles les plus cinématiques : c’est pour obtenir une image solide avec des mots lisibles, rapidement.
L’architecture à 6 milliards de paramètres
Je ne choisis pas les modèles par nombre de paramètres, mais cela explique certains des comportements. À 6B, Z-Image-Turbo se sent intentionnellement contraint : plus léger que les variantes de diffusion géantes, plus lourd que les plus petits modèles axés sur les mobiles. En pratique, cela signifiait deux choses pour moi. Premièrement, la mémoire est restée prévisible, pas de perte hors limites tardive lorsque je poussais la résolution. Deuxièmement, les invites répondaient de manière cohérente. Je n’ai pas eu à sur-concevoir les conseils pour maintenir la typographie intacte.
Le détail architectural qui importait le plus : il est entraîné pour traiter le texte en image comme un objectif de première classe, pas un accident heureux. Vous pouvez voir cela quand vous demandez des panneaux, des maquettes d’interface utilisateur, ou des photos de produits avec des étiquettes. Les lettres ne fondent pas dès que vous ajoutez du style. Elles ne sont pas parfaites, mais elles sont assez stables pour que j’arrête de faire du baby-sitting du prompt.
Échantillonnage en 8 étapes, pourquoi c’est si rapide
 La plupart de mes générations se situaient entre 6 et 10 étapes, avec 8 comme défaut. C’est là que la vitesse apparaît. Les calendriers à faible nombre d’étapes s’effondrent souvent sur les détails fins, mais ici les résultats ont conservé leur forme, et le texte est resté lisible plus souvent que non. Sur mon GPU de portable 16 Go, les images 512×512 se terminaient régulièrement en quelques secondes : sur l’API hébergée, la latence est restée rapide même avec une légère concurrence.
La plupart de mes générations se situaient entre 6 et 10 étapes, avec 8 comme défaut. C’est là que la vitesse apparaît. Les calendriers à faible nombre d’étapes s’effondrent souvent sur les détails fins, mais ici les résultats ont conservé leur forme, et le texte est resté lisible plus souvent que non. Sur mon GPU de portable 16 Go, les images 512×512 se terminaient régulièrement en quelques secondes : sur l’API hébergée, la latence est restée rapide même avec une légère concurrence.
Cela ne m’a pas fait gagner du temps au début, je me suis toujours tracassé avec le libellé du prompt. Mais après quelques exécutions, j’ai remarqué que la charge mentale diminuait. Moins de tentatives. Moins d’impulsions « une graine de plus ». Si vous travaillez en boucles courtes (brouillon → retouche → livraison), le petit nombre d’étapes s’additionne rapidement.
Les caractéristiques qui comptent
J’essaie d’éviter les listes de fonctionnalités, mais quelques choix ici ont façonné la façon dont j’ai utilisé le modèle.
Support d’invite bilingue (EN/ZH)
J’ai testé les invites en anglais et en chinois simple côte à côte, étiquettes, panneaux, légendes courtes. Le modèle a géré les deux sans que j’aie besoin de changer quoi que ce soit dans les paramètres. Ce qui s’est démarqué, c’est que l’intention du prompt a été conservée dans les deux langues. Quand j’ai demandé « un tableau de menu propre avec trois sections » en chinois, j’ai obtenu la même structure que le prompt en anglais, pas une réinterprétation lâche. Si vous travaillez dans des équipes ou des marchés différents, cela réduit les frottements, pas de fine-tuning supplémentaire, pas de bidouilles spécifiques à la langue.
Limites : les invites multilingues à l’intérieur d’une seule image parfois penchaient vers une langue pour le texte rendu. Je pouvais la diriger avec des instructions explicites (par exemple, « titre en EN, sous-titre en ZH »), mais ce n’est pas parfait. Néanmoins, pour les flux de travail bilingues, c’est l’une des expériences les plus simples que j’ai eues.
Rendu de texte natif dans les images
 C’est pour ça que je suis restée. Le texte ressemble à du texte la plupart du temps, des lignes de base droites, des polices reconnaissables, et des caractères qui survivent aux changements de style modérés. J’ai jeté des cas d’échec courants dessus : signalisation courbe, petits pieds de page, faux étiquettes d’interface utilisateur. Il a tenu mieux que les modèles ouverts usuels que j’utilise, surtout à des tailles modestes. Pas une typographie de couverture de magazine, mais assez bien pour que j’arrête de masquer et de composer chaque fois.
C’est pour ça que je suis restée. Le texte ressemble à du texte la plupart du temps, des lignes de base droites, des polices reconnaissables, et des caractères qui survivent aux changements de style modérés. J’ai jeté des cas d’échec courants dessus : signalisation courbe, petits pieds de page, faux étiquettes d’interface utilisateur. Il a tenu mieux que les modèles ouverts usuels que j’utilise, surtout à des tailles modestes. Pas une typographie de couverture de magazine, mais assez bien pour que j’arrête de masquer et de composer chaque fois.
Une petite note pratique : les invites de texte courtes et précises fonctionnaient mieux. Les longs paragraphes sont toujours flous. Si vous concevez une copie lourde dans une image, vous voudrez probablement un outil de mise en page. Mais pour les logos, les étiquettes, les bannières, et les maquettes d’interface utilisateur simples, Z-Image-Turbo a rendu le chemin « juste le rendre ici » viable.
Compatibilité VRAM 16 Go
J’ai lancé sur un GPU 16 Go sans sharding ou une demi-journée de bingo de dépendances. Les images carrées 768px fonctionnaient : 1024px avait besoin d’un peu plus de patience et des bons paramètres de précision, mais c’était quand même correct. Pour moi, cela compte plus qu’une démonstration fantaisiste. Si le modèle se comporte bien sur un GPU de portable courant, je peux le garder dans ma boucle quotidienne au lieu de lancer un équipement séparé.
Si vous êtes à 8-12 Go, vous devrez peut-être réduire la résolution ou vous appuyer sur l’API. Si vous avez 24 Go ou plus, vous aurez plus de place pour les grands formats, mais la valeur principale du modèle, résultats rapides et stables en texte, apparaît même à des tailles plus petites.
Performance de référence
Les benchmarks ne sont pas le travail, mais ils aident à faire un contrôle de la cohérence des impressions.
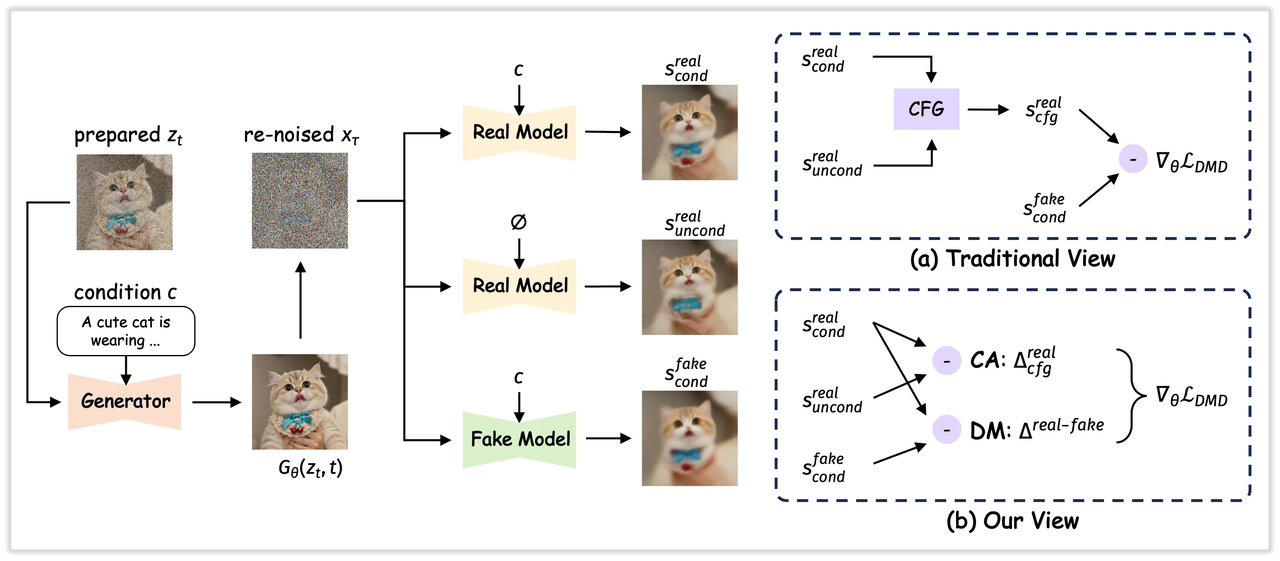
#1 Open-Source au classement Artificial Analysis
 Au début du février 2026, Z-Image-Turbo est listé au-dessus ou près du haut parmi les modèles d’images open-source sur le classement Artificial Analysis (les classements changent, alors traitez cela comme un instantané). Cela correspond à ce que j’ai ressenti : la vitesse et la fidélité du texte semblent être ses points forts. Les classements ne mesurent pas tout, mais ils sont un proxy utile pour la façon dont un modèle se généralise au-delà d’une démo soignée.
Au début du février 2026, Z-Image-Turbo est listé au-dessus ou près du haut parmi les modèles d’images open-source sur le classement Artificial Analysis (les classements changent, alors traitez cela comme un instantané). Cela correspond à ce que j’ai ressenti : la vitesse et la fidélité du texte semblent être ses points forts. Les classements ne mesurent pas tout, mais ils sont un proxy utile pour la façon dont un modèle se généralise au-delà d’une démo soignée.
Comment cela se compare aux modèles propriétaires
Comparé aux grands modèles hébergés, Z-Image-Turbo échange le photorréalisme de pointe pour la vitesse, le coût, et le texte contrôlable. Si vous voulez des scènes brillantes et cinématiques avec un éclairage complexe, certaines options propriétaires le surpassent encore. Si vous voulez un graphique propre avec des mots lisibles en deux minutes, celui-ci tient bon. J’ai aussi remarqué que moins de contorsions de prompt étaient nécessaires pour maintenir la typographie intacte, moins d’essais, plus de résultats. Pour les petites équipes ou les créateurs en solo, cet équilibre est généralement la différence entre « agréable expérience » et « c’est livré aujourd’hui ».
Qui devrait utiliser Z-Image-Turbo ?
Cas d’utilisation idéaux
- Graphiques sociaux avec texte court et lisible (annonces, bannières, miniatures)
- Maquettes de produits et scènes d’interface utilisateur simples où les étiquettes doivent survivre
- Docs internes et diapositives qui bénéficient de visuels rapides sans détour de conception
- Actifs bilingues où la flexibilité de la langue d’invite économise les allers-retours
- Itération rapide dans les sprints, quand vous voulez 3-5 variantes décentes rapidement et poursuivez
Dans mes tests, la victoire n’était pas juste la vitesse brute. C’était la prévisibilité. Je pouvais ajuster le style ou la mise en page sans perdre le texte entièrement, ce qui signifiait moins de redémarrages.
Quand choisir d’autres modèles à la place
- Photorréalisme haut de gamme pour les impressions grand format ou les publicités, certains modèles propriétaires livrent toujours une finition plus soignée.
- Longs paragraphes ou systèmes de typographie complexes, utilisez un outil de mise en page ou post-traitez.
- Compositing lourd ou cohérence entre plusieurs images (même caractère dans plusieurs scènes), vous voudrez un modèle avec une identité forte et des contrôles multi-shots.
Si votre travail tend vers le storytelling cinématique ou les études d’éclairage complexes, vous préférez peut-être un outil différent. Z-Image-Turbo est plus un pilote quotidien qu’une voiture de spectacle.
Comment démarrer
Démarrage rapide de l’API WaveSpeed
J’ai d’abord essayé l’API WaveSpeed pour éviter la dérive de configuration. L’authentification était standard, et le corps de la requête était simple : prompt, étapes (je me suis tenu à 8), taille, et une graine si vous voulez la reproductibilité. Les défauts étaient sensibles. Si vous testez le rendu de texte, commencez par des phrases courtes et une résolution moyenne, puis agrandissez une fois que vous aimez l’apparence. Je suis passée de l’idée à la première image utilisable en moins de cinq minutes, la partie la plus rapide de cette expérience.
Si vous préférez local, le modèle fonctionnait proprement sur un GPU 16 Go avec les paramètres de précision typiques. Gardez un œil sur VRAM en franchissant 768px. Si vous atteignez des limites, réduisez les étapes avant de réduire les conseils : l’échantillonnage en 8 étapes est le point ici.
Aperçu de la tarification ($0,005/image)
 Via WaveSpeed, la tarification est sortie à environ 0,005 $ par image avec les paramètres standard. C’est difficile de se plaindre pour les brouillons, les actifs sociaux, ou les expériences rapides. Si vous générez à grande échelle, surveillez les bouchons de concurrence, la latence est restée basse pour moi avec de petites rafales, mais je n’ai pas fait de tests de stress au-delà d’une poignée de tâches parallèles.
Via WaveSpeed, la tarification est sortie à environ 0,005 $ par image avec les paramètres standard. C’est difficile de se plaindre pour les brouillons, les actifs sociaux, ou les expériences rapides. Si vous générez à grande échelle, surveillez les bouchons de concurrence, la latence est restée basse pour moi avec de petites rafales, mais je n’ai pas fait de tests de stress au-delà d’une poignée de tâches parallèles.
C’est ce qui a fonctionné pour moi, votre kilométrage peut varier. Si vous jongler avec des invites bilingues ou juste vouloir du texte qui ressemble à sa place dans l’image, cela vaut le coup de regarder. La dernière chose que j’ai remarquée, presque par accident : j’ai arrêté de faire des captures d’écran et d’éditer encore et encore. Moins de détours. C’est ça qui semblait être le point.
Articles associés

Seedance 2.0 arrive bientôt : Le modèle vidéo nouvelle génération de ByteDance avec audio natif

Guide Complet Seedance 2.0 : Création Vidéo Multimodale

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1 : La Comparaison Ultime de la Génération Vidéo

Guide Complet Seedream 5.0-Preview : Génération d'Images Intelligente

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image : Comparaison Complète
