Télécharger le modèle LTX-2 : fichiers Hugging Face, tailles et structure de dossiers

Traduction de l’article en français
La première fois que j’ai cherché à télécharger LTX-2, ce n’était pas un grand plan. Je voulais juste faire passer un petit lot dans ComfyUI et je continuais à buter sur les mêmes deux frictions : des téléchargements lents qui s’arrêtaient à 92%, et un message cryptique « Model not found » une fois que j’avais enfin les fichiers. Rien de dramatique. Juste le genre d’accroc répété qui vous pousse à vous arrêter et à organiser le flux de travail.
J’ai passé quelques soirées en début janvier 2026 à tester différentes sources, formats (NVFP4 vs NVFP8), et dispositions de dossiers sur une boîte avec GPU 24GB. Rien de flashy, juste assez de runs pour voir ce qui était solide par rapport à ce qui était fragile. Voici le chemin qui a réduit le désordre pour moi, avec des notes que vous pouvez parcourir et adapter.
Sources de téléchargement officielles de LTX-2 (Hugging Face Model Card)
 Je ne chasse pas les miroirs. Si un modèle importe pour mon flux de travail, je veux que le chemin soit ennuyeux et fiable. Pour LTX-2, cela signifie commencer par la carte de modèle officielle Hugging Face.
Je ne chasse pas les miroirs. Si un modèle importe pour mon flux de travail, je veux que le chemin soit ennuyeux et fiable. Pour LTX-2, cela signifie commencer par la carte de modèle officielle Hugging Face.
Ce que je cherche avant de cliquer sur télécharger :
- Éditeur : Est-ce l’organisation vérifiée ou l’auteur lié à LTX-2 ? Je vérifie le badge org et que les autres repos dans cet espace semblent actifs et cohérents.
- Licence et conditions : Certaines variantes de LTX-2 sont gâtées ou ont des limites d’utilisation. Si accepter les conditions nécessite un token, je préfère le faire une seule fois plutôt que de déboguer les erreurs d’authentification plus tard.
- Liste des artefacts : Je parcours le modèle principal, tous les encodeurs, et une variante distillée ou quantifiée. Les noms de fichiers clairs battent les noms malins.
- Instructions : Si la carte renvoie à ComfyUI ou à des docs spécifiques aux nœuds, je les suis d’abord. Une ligne sur les dossiers attendus peut gagner une demi-heure de devinettes.
Conseil pratique : utilisez le CLI Hugging Face avec les identifiants définis. Un repo gâté ne sera pas extrait sur git-lfs brut sans un token, et c’est le moyen le plus rapide de se retrouver avec des fichiers partiels et pas d’erreur jusqu’à ce que vous essayiez de les charger.
pip install huggingface_hub git-lfs
huggingface-cli login # collez votre tokenJe sais, c’est évident. Mais le nombre de fois où j’ai vu un 403 silencieux se transformer en « model not found » en aval est… non-zéro.
Liste des fichiers et tailles (modèle principal / encodeur / distillé)
Je ne mémorise pas les tailles de fichiers. J’ai juste besoin d’un ordre de grandeur pour planifier le disque et décider quelle variante récupérer en premier. Voici ce que j’ai réellement vu dans les récentes versions de LTX-2. Votre repo peut différer, faites toujours confiance à la carte de modèle plutôt qu’à mes notes.
Artefacts typiques que vous verrez :
- Point de contrôle du modèle principal (souvent
.safetensorsou un format spécifique au runtime) : ~2,5–6,0 GB. Plus grand s’il inclut des têtes supplémentaires ou une multi-précision ; plus petit s’il est quantifié. - Encodeur texte/image (CLIP ou similaire) : ~400 MB–1,5 GB. Certaines versions le regroupent ; d’autres l’expédient en tant que fichier séparé.
- VAE ou adaptateur latent (le cas échéant) : ~100–500 MB.
- Variante distillée : ~1–3 GB. Plus rapide et plus léger, parfois avec des sorties légèrement plus douces. Bon pour le prototypage.
- Variantes quantifiées (NVFP8/NVFP4) : la taille varie, mais attendez-vous à 30–60% moins de disque qu’à pleine précision.
Motifs de nommage que je surveille :
ltx-2.safetensors(principal)ltx-2-encoder.safetensorsouopen_clip-vit-…(encodeur)ltx-2-vae.safetensors(s’il est séparé)ltx-2-distilled-…(plus petit, plus rapide)ltx-2-nvfp8/ltx-2-nvfp4(spécifique au format)
Si le disque est serré, je récupère d’abord le distillé, je valide mon pipeline, puis j’extrais le modèle complet. Ce n’est pas seulement une question de vitesse : réduire la charge cognitive de la première exécution m’aide à tester les prompts et les nœuds sans combattre la VRAM immédiatement.
Structure des dossiers ComfyUI pour LTX-2 (Chemins exacts)
C’est là que je me suis trippé le premier jour : mes fichiers allaient bien, mais ComfyUI ne savait pas où chercher. Les différents nœuds personnalisés attendent des emplacements légèrement différents, mais les valeurs par défaut ci-dessous ont été sûres pour moi.
Sur une installation ComfyUI standard (pas de surcharges de nœuds personnalisés) :
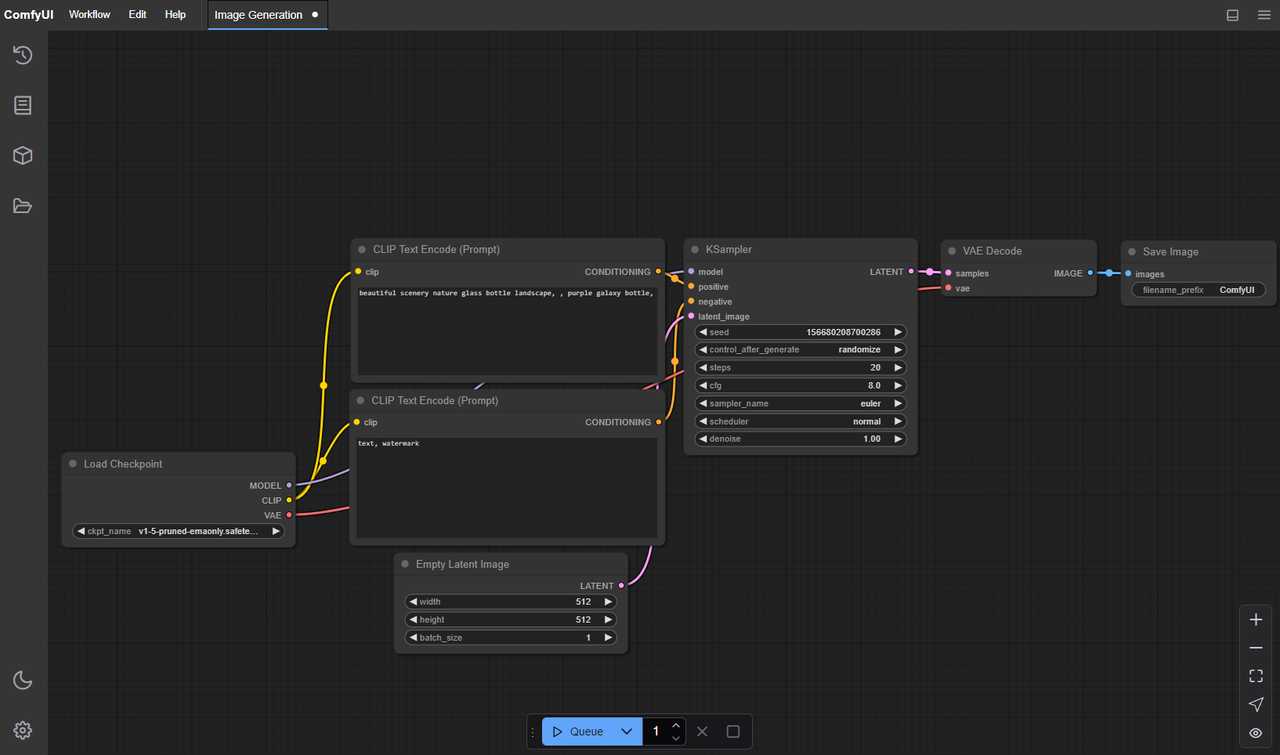
- Point de contrôle du modèle principal :
ComfyUI/models/checkpoints/LTX-2.safetensors - Encodeur texte/image (CLIP ou similaire) :
ComfyUI/models/clip/LTX-2-encoder.safetensors- Certaines versions utilisent la dénomination open_clip : placez-les dans
models/clip/aussi.
- Certaines versions utilisent la dénomination open_clip : placez-les dans
- VAE (s’il est séparé) :
ComfyUI/models/vae/LTX-2-vae.safetensors - LoRA/patchs (si vous les utilisez) :
ComfyUI/models/loras/
Si vous utilisez des nœuds qui reposent sur les fichiers TensorRT ou engine :
ComfyUI/models/trt/ltx-2/*.engineComfyUI/models/unet/ltx-2/*.engine
Deux habitudes ennuyeuses mais utiles :
- Faites correspondre exactement les noms de fichiers à ce que votre nœud attend. Je garde les noms courts et je supprime les espaces.
- Après avoir déplacé les fichiers, utilisez l’actualisation du modèle ComfyUI ou redémarrez. Le rechargement à chaud fonctionne parfois : un redémarrage complet est plus cohérent.
Si vous utilisez un disque externe ou un dossier de modèles partagé, définissez les chemins de modèles supplémentaires de ComfyUI pour qu’il ne scanne pas silencieusement le mauvais lecteur. La sensibilité à la casse sous Linux m’a mordu plus d’une fois.
Poids NVFP4 vs NVFP8 : lequel télécharger
 J’étais curieux de savoir si NVFP4 valait la compression supplémentaire. Réponse courte : peut-être, si vous êtes serré à la VRAM et que vos nœuds le supportent réellement.
J’étais curieux de savoir si NVFP4 valait la compression supplémentaire. Réponse courte : peut-être, si vous êtes serré à la VRAM et que vos nœuds le supportent réellement.
Voici comment cela s’est senti en pratique sur ma boîte (GPU classe Hopper, versions janvier 2026) :
NVFP8
- Équilibre : bon compromis. Notablement moins de mémoire qu’à pleine précision avec une dérive de sortie minimale.
- Compatibilité : meilleure. Plus de nœuds et d’exécutions acceptent FP8 que FP4 en ce moment.
- Quand je le choisis : les runs quotidiens où je veux la stabilité plutôt que l’empreinte mémoire la plus petite.
NVFP4
- Empreinte : plus petite. Cela m’a permis d’augmenter la résolution ou le contexte d’un cran où FP8 ne pouvait pas.
- Dérive : légèrement plus d’artefacts ou de mollesse sur les cas limites. Pas toujours, mais juste assez pour que je le remarque.
- Compatibilité : plus exigeante. Certains chargeurs reviennent ou échouent s’ils ne détectent pas les bons noyaux.
- Quand je le choisis : les brouillons rapides, les recherches en grille, ou quand le flux de travail est strictement supporté par le chemin FP4 du nœud.
Une chose de plus : ces formats supposent généralement que vous êtes sur une pile NVIDIA qui peut les accélérer correctement. Si votre nœud ne dit pas explicitement « NVFP4/NVFP8 supporté », je reviens à la pleine précision ou une version distillée .safetensors. Chasser les gains marginaux ne vaut pas le plantage mystérieux au milieu du rendu.
Conseils d’accélération du téléchargement de LTX-2 et vérification de la somme de contrôle
Je traite les gros tirages de modèles comme n’importe quel autre travail de fichier volumineux : accélérez-le, puis vérifiez.
L’accélération qui a réellement aidé :
- Accélération du transfert Hugging Face : définissez la variable d’environnement
HF_HUB_ENABLE_HF_TRANSFER=1avant d’utiliserhuggingface_hub. Cela active leur backend accéléré où disponible.
aria2c pour les chunks parallèles :
aria2c -x 16 -s 16 -k 1M -cLe drapeau -c reprend les téléchargements partiels proprement quand ma connexion s’arrête à 97%.
Tirages git-lfs accordés
git lfs installpuisgit clone.- En suivant le guide d’installation Git LFS, si c’est un énorme repo, j’utilise parfois sparse-checkout pour éviter de tirer les exemples que je n’utiliserai pas.
Vérification que je fais réellement (et que je ne saute plus)
Comparez SHA256 à partir de la carte de modèle (ou des fichiers .sha256 du repo) par rapport à votre fichier local.
- macOS/Linux :
shasum -a 256 - Windows :
certutil -hashfile SHA256
Vérification simple de la taille du fichier
- Si la taille attendue est 4,2 GB et que j’en vois 3,3 GB, je m’arrête là. Les fichiers partiels se chargent occasionnellement, puis lancent des erreurs de garbage plus tard.
Petite habitude qui économise du temps : je garde un petit README.txt à côté des fichiers de modèle avec l’URL d’origine, la date et le hachis. Quand je reviens trois mois plus tard, je n’ai pas besoin de rétro-ingéniérer les choix de mon moi passé.
Correctifs « Model Not Found »
Cette erreur a mangé une heure que je n’aurai pas. Voici les correctifs qui ont réellement bougé l’aiguille pour moi :
- Mauvais dossier : ComfyUI attend des points de contrôle dans
models/checkpoints/, des encodeurs dansmodels/clip/, et des VAE dansmodels/vae/. Mettez-les ailleurs et le scanner peut les ignorer. - Décalage de nom de fichier : Certains nœuds cherchent un nom de base spécifique. Si le nœud dit
ltx-2.safetensors, ne l’appelez pasLTX-2 (final).safetensors. Je renomme agressivement. - Sensibilité à la casse :
ltx-2.safetensors≠LTX-2.safetensorssous Linux. Demandez-moi comment je le sais. - Indexation du cache : Actualisez les modèles ou redémarrez ComfyUI après le déplacement des fichiers. L’index n’est pas toujours en temps réel.
- Dépendance manquante : Si le nœud attend un encodeur externe et que vous n’avez téléchargé que le modèle principal, vous aurez une erreur vague. Tirez l’encodeur listé sur la carte de modèle et réessayez.
- Modèle gâté sans token : Si vous avez cloné sans vous connecter (ou votre token a expiré), les fichiers locaux peuvent être des stubs. Reconnectez-vous avec
huggingface-cli loginet re-tirez. - Nœuds personnalisés et chemins alternatifs : Certains nœuds remplacent les dossiers par défaut. Vérifiez leur README pour les chemins attendus ou les variables d’environnement. En cas de doute, déposez un lien symbolique de votre répertoire de modèles partagé vers le chemin local attendu.
Quand je suis bloqué, je dirige temporairement le nœud vers un petit modèle connu et bon juste pour confirmer que le chargeur fonctionne. Si le petit se charge, le bug vit dans les fichiers LTX-2, pas mon environnement.
Ignorer les téléchargements de LTX-2 en utilisant WaveSpeed
J’ai essayé un itinéraire différent sur un ordinateur portable de voyage : ignorer complètement les téléchargements locaux et exécuter LTX-2 via WaveSpeed. Il diffuse ou héberge les poids à distance pour que vous puissiez câbler un graphique de type ComfyUI sans garer 10+ GB sur votre disque.
 Ce qui a fonctionné pour moi :
Ce qui a fonctionné pour moi :
- L’intégration était légère. J’ai pointé le graphique vers leur endpoint LTX-2 et je n’ai pas touché aux dossiers locaux.
- Les démarrages à froid étaient plus lents (la première exécution lance une session), mais les runs chauds semblaient normaux pour les petits lots.
- Cela a empêché le ventilateur de mon ordinateur portable de hurler. Cela seul l’a rendu utile en déplacement.
Les compromis que j’ai remarqués :
- Latence : Il y a un petit surcharge, plus évidente avec beaucoup de courtes exécutions. Pour les longs rendus, j’ai arrêté de remarquer.
- Contrôle : Vous abandonnez une certaine épingle de version. Ils gardent les modèles patchés, ce qui est agréable, jusqu’à ce que vous vouliez reproduire un résultat plus ancien.
- Coût/quotas : Ce n’est pas « gratuit comme un téléchargement ». Si vous êtes sur un budget serré ou avez besoin d’un travail de batch lourd, le local gagne toujours.
- Confidentialité : Je garde les prompts et les actifs sensibles locaux. Pour le travail public ou de test, je suis d’accord.
Qui pourrait aimer cela : les gens testant LTX-2 sur des machines sous-alimentées, ou quiconque veut esquisser un flux de travail avant de s’engager dans une configuration locale complète. Si vous êtes riche en VRAM et que vous vous souciez de la reproductibilité exacte, les installations locales semblent toujours meilleures.
Je ne m’attendais pas à l’aimer, mais pour les expériences rapides, sauter le téléchargement était un petit soulagement.
Articles associés

Seedance 2.0 arrive bientôt : Le modèle vidéo nouvelle génération de ByteDance avec audio natif

Guide Complet Seedance 2.0 : Création Vidéo Multimodale

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1 : La Comparaison Ultime de la Génération Vidéo

Guide Complet Seedream 5.0-Preview : Génération d'Images Intelligente

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image : Comparaison Complète
