Installer LTX-2 dans ComfyUI sur Windows : Guide CUDA & Premier Lancement

LTX-2 sur ComfyUI Windows : configuration étape par étape
Bonjour, je suis Dora. Ce jour-là, je voulais juste une passe rapide de texte en vidéo pour un croquis, et j’ai continué à voir LTX‑2 mentionné dans les discussions ComfyUI. À mi-chemin de la matinée, je fixais un graphique vide et un dossier appelé « ltx », en me demandant si je venais de m’inscrire à la roulette des pilotes une fois de plus.
J’ai pris des notes pendant la configuration sur Windows 11. Si vous recherchez « ltx‑2 comfyui windows » parce que vous êtes en pleine installation, j’y suis passée. Voici ce qui m’a aidée.
Checklist pré-installation (GPU / CUDA / versions du pilote)
Une vérification rapide avant de commencer vous évite l’heure que vous passerez à poursuivre les erreurs DLL plus tard :
- GPU : Une carte NVIDIA avec au moins 12 Go de VRAM a rendu LTX‑2 utilisable pour moi avec des paramètres modestes (largeur 512–768, clips courts). 8 Go peut fonctionner avec des paramètres très conservateurs, mais c’est serré et souvent frustrant.
- Pilotes : Mettez à jour vers un pilote Game Ready ou Studio récent (j’ai utilisé 552.xx).
- CUDA : Vous n’installez pas un kit CUDA complet pour ComfyUI portable. Vous avez juste besoin des DLL runtime qui sont livrées avec PyTorch. C’est pourquoi la correspondance avec la build PyTorch+CUDA est importante (cu121 ou cu122, etc.).
- Python : La build portable ComfyUI est livrée avec son propre Python. Si vous exécutez un venv personnalisé, gardez-le aligné avec la wheel PyTorch que vous choisissez.
- Redistributable VC++ : Installez/réparez le dernier Redistributable Microsoft Visual C++. C’est un correctif discret pour les erreurs DLL de style « point d’entrée de procédure ».
Deux vérifications de bon sens que j’effectue avant tout modèle lourd :
nvidia-smis’exécute dans un terminal et affiche proprement le pilote.python -c "import torch: print(torch.version, torch.cuda.is_available())"retourne True pour CUDA dans l’environnement que ComfyUI utilisera.
Rien de cela ne garantit une navigation en douceur, mais cela réduit les modes de défaillance.
Mettre à jour ComfyUI vers une version prête pour LTX-2
Ce que j’ai fait :
- Mettre à jour ComfyUI en premier. Si vous utilisez la build portable de GitHub, récupérez la dernière version ou git pull et exécutez les scripts de mise à jour.
- Ouvrez ComfyUI Manager (si vous l’utilisez) et mettez à jour les dépendances principales. J’ai laissé Manager reconstruire le venv lorsque demandé.
- Installez le pack de nœuds LTX‑2 à partir de son référentiel officiel. Le nom varie (j’ai vu des repos de style « ComfyUI-LTXVideo »/« LTX‑Video ») : j’ai utilisé celui lié depuis la page officielle du modèle. Si une description de repo indique qu’elle prend en charge LTX‑Video v2/LTX‑2, c’est celui que vous voulez.
Pourquoi cela a de l’importance en pratique :
- LTX‑2 s’appuie sur les fonctionnalités PyTorch 2.3+ et les builds CUDA 12.x. Le mélange d’anciens torch (cu118) avec de nouveaux nœuds est un moyen rapide de rencontrer des erreurs d’importation cryptiques.
- Certains packs exposent les bascules FP8/BF16 différemment. Faire correspondre le pack de nœuds et la version ComfyUI évite les entrées mal appariées et les graphiques sans issue.
J’ai d’abord résisté à une installation fraîche, cela semblait inutile. Puis j’ai comparé : la nouvelle build a commencé du premier coup ; l’ancienne continuait à demander des ops manquantes. Je n’ai pas regretté les conjectures.
Placement du fichier modèle (étape par étape)
C’est ici que j’ai généralement du mal. Différents nœuds s’attendent à différents dossiers. Voici ce qui a fonctionné pour moi avec le pack de nœuds LTX‑2 que j’ai installé, et le modèle général s’applique même si les noms de vos dossiers diffèrent.
-
Trouvez les chemins attendus du nœud.
Dans ComfyUI, ouvrez le nœud de chargeur LTX et survolez n’importe quelle entrée de fichier. La plupart des packs affichent le chemin relatif qu’ils scannent (par ex.models/ltx,models/checkpoints, ou un sous-dossier personnalisé commemodels/ltx_video).
En cas de doute, consultez le README du repo. Ils listent généralement le répertoire exact. -
Téléchargez les poids LTX‑2 depuis la source officielle (souvent Hugging Face, lié depuis la page du modèle).
Vous obtiendrez généralement un fichier.safetensorsou.pthprincipal plus des configurations. Certains repos divisent les encodeurs de texte/VAE séparément ; d’autres les regroupent. -
Placez les fichiers exactement où le nœud les cherche.
Pour mon pack :ComfyUI/models/ltx_video/contenait le fichier modèle principal. Si votre pack indiquemodels/checkpoints, utilisez cela à la place. Le nom devrait apparaître dans la liste déroulante du nœud après un redémarrage ou une nouvelle analyse. -
Optionnel : encodeur de texte / VAE.
Si le nœud expose des entrées séparées pour les encodeurs ou un VAE, suivez ses conseils. De nombreux nœuds LTX‑2 cachent cela et regroupent les composants en interne. S’il est exposé, mettez les fichiers CLIP/Tokenizer dansmodels/clipoumodels/text_encoderscomme instructé par le README. -
Redémarrez ComfyUI.
Je sais, c’est évident. Mais le rechargement à chaud ne rescanne pas toujours ces dossiers, et j’ai fixé une liste déroulante vide plus de fois que je ne l’admettrai.
Petite note : si Windows signale les fichiers téléchargés comme bloqués (clic droit > Propriétés > Débloquer), effacez cela. Python a refusé de toucher aux fichiers « téléchargés d’Internet » dans les configurations plus strictes.
Erreurs Windows courantes (DLL / permissions)
« DLL load failed while importing … » ou nvrtc64_X.dll manquant
- Cause : La build PyTorch ne correspondait pas au runtime CUDA attendu par le pack de nœuds, ou l’environnement mélangeait cu118 et cu12x.
- Correction : Réinstallez/confirmez PyTorch 2.3+ avec cu121/cu122 dans l’environnement ComfyUI. Si vous utilisez portable, laissez Manager s’en charger. La mise à jour des pilotes NVIDIA a aidé une fois.
 « L’accès est refusé » lors de l’écriture de cadres/vidéo
« L’accès est refusé » lors de l’écriture de cadres/vidéo - Cause : J’ai pointé le nœud SaveVideo vers un dossier synchronisé avec des permissions agressives (OneDrive).
- Correction : Écrivez d’abord vers un chemin local non synchronisé (par ex.
ComfyUI/output/ltx_test). Déplacez le fichier plus tard.
Problèmes de chemin long lors du décompactage
- Cause : Les limites de longueur de chemin Windows plus les sous-dossiers ComfyUI profonds.
- Correction : Activez les chemins longs dans Windows (Local Group Policy ou registre) ou décompactez plus près de
C:\.
L’antivirus scanne les cadres temporaires au milieu du rendu
- Symptôme : ComfyUI suspend ou gèle pendant l’encodage.
- Correction : Ajoutez une exclusion pour le dossier ComfyUI ou juste le chemin de sortie temporaire.
« Impossible de trouver le modèle » même si le dossier est correct
- Correction : Redémarrez ComfyUI. S’il ne s’affiche toujours pas, vérifiez le dossier exact attendu du nœud. Certains nœuds LTX‑2 cherchent dans un nom de répertoire personnalisé. Faites correspondre exactement.
J’ai aussi rencontré le classique « fonctionne une fois, échoue la prochaine fois ». Pour moi, cela se résumait à un onglet de navigateur essayant d’afficher un aperçu du MP4 partiel tandis que le nœud d’encodage écrivait toujours. J’ai changé pour écrire vers un nom de fichier frais à chaque exécution. L’instabilité a disparu.
Flux de travail de test d’inférence initial
J’ai gardé le premier graphique minuscule. Rien de sophistiqué, juste assez pour confirmer le pipeline.
Ce que j’ai construit :
- Un nœud Prompt avec une seule phrase (10–20 tokens). Gardez-le simple.
- Nœud de chargeur LTX‑2 pointant vers le modèle téléchargé.
- Un nœud LTX‑2 Sampler/Scheduler (quel que soit le nom de votre pack) avec peu d’étapes.
- Un chemin Video Decode/Assemble qui écrit les cadres vers un nœud SaveVideo (MP4, H.264 convient pour un test de fumée).
Paramètres qui ne m’ont pas combattue :
- Résolution : 512×288 ou 640×360
- Cadres : 8–16 cadres (0,5–1 seconde)
- Étapes : 6–12
- Guidance/CFG : terrain d’entente (5–7)
- Graine : nombre fixe (rend le dépannage moins bruyant)
- Précision : FP16 (par défaut) sauf si votre nœud suggère BF16 sur Ada : les deux ont fonctionné pour moi, FP16 utilisait moins de VRAM
Ce que je surveille à la première exécution :
- Pics VRAM dans
nvidia-smi. Si vous êtes épinglé à 99% de VRAM instantanément, baissez la résolution ou les cadres. - Temps jusqu’au premier cadre. Ma première exécution propre était ~25–40 secondes pour 16 cadres à 512×288 sur une 4070, steps=8. Tout ce qui était beaucoup plus long pointait généralement vers un encodage CPU ou un goulot d’étranglement E/S.
Si votre rendu se termine mais la vidéo est vide ou corrompue, essayez :
- D’abord écrire les cadres PNG, puis laisser un nœud séparé ou un outil externe assembler la vidéo.
- Passer à un encodeur différent (H.264 vs H.265) ou une valeur CRF.
La partie utile n’était pas la vitesse, c’était de voir un clip cohérent. C’est le moment où je me détends. Ensuite, j’augmente avec prudence.
Réglage des performances (batch / précision)
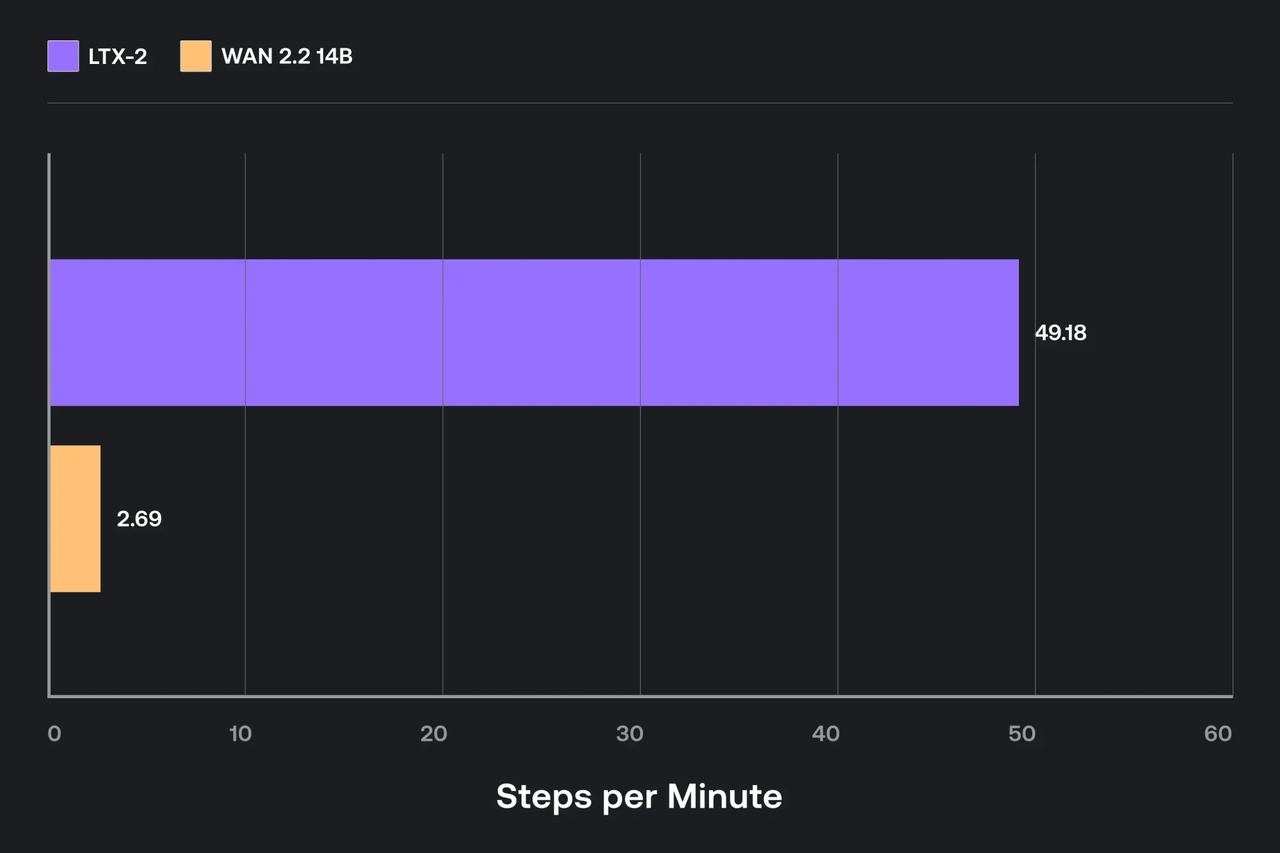 Je n’ai pas poursuivi la gloire des benchmarks. Je voulais juste des paramètres qui m’empêchaient de surveiller la mémoire.
Je n’ai pas poursuivi la gloire des benchmarks. Je voulais juste des paramètres qui m’empêchaient de surveiller la mémoire.
Ce qui a fait bouger l’aiguille :
- Cadres avant la largeur. Il était plus facile sur VRAM de garder 12–16 cadres et de augmenter la largeur à 640 que de passer à 24+ cadres. Les clips plus longs augmentent rapidement en mémoire.
- Précision : FP16 a fonctionné au mieux sur ma 4070. BF16 a aussi fonctionné mais utilisait un peu plus de mémoire. Je n’ai pas gagné de qualité visible de BF16 à ces tailles.
- Backend d’attention : Si votre pack expose une bascule pour
scaled_dot_product_attention(PyTorch natif) vs xFormers, essayez d’abord native sur les PyTorch récents. C’était plus stable pour moi sur Windows. - Taille du batch : Gardez-la à 1 pour la vidéo. Les mini-batches punissaient surtout VRAM sans économiser de temps mural sur ma configuration.
- Torch compile : Vaut le coup d’essayer, mais je n’ai vu que de petits gains pour les exécutions plus longues. Pour les tests courts de 8–16 cadres, le temps de compilation pourrait manger les économies.
- E/S mixte : L’écriture vers un SSD local rapide était plus importante que je ne l’aurais cru. Les dossiers réseau lents faisaient que la phase d’encodage ressemblait à un problème de modèle quand ce n’était pas le cas.
Une échelle simple qui n’a pas explosé VRAM pour moi :
- 512×288, 12 cadres, steps=8
- 640×360, 16 cadres, steps=10
- 768×432, 16–24 cadres, steps=12–14
Si vous frappez un manque de mémoire :
- Baissez les cadres de 4 avant de baisser la largeur.
- Réduisez d’abord les étapes si vous avez juste besoin d’une ébauche.
- Fermez les autres applications GPU (lecteurs vidéo, navigateur avec accélération matérielle). Fastidieux, mais cela fonctionne.
J’ai aussi essayé un petit mode tuile/patch que certains packs offrent. Cela a aidé à des largeurs plus élevées mais a parfois introduit des coutures. Bon pour les expériences : pas mon défaut.
Chemin WaveSpeed (aucun CUDA local nécessaire)
 J’ai testé une exécution via un chemin hébergé pour éviter le remaniement du GPU. L’idée : laissez ComfyUI parler à un worker distant qui exécute LTX‑2, pour que votre boîte Windows locale ne gère que l’interface utilisateur du graphique.
J’ai testé une exécution via un chemin hébergé pour éviter le remaniement du GPU. L’idée : laissez ComfyUI parler à un worker distant qui exécute LTX‑2, pour que votre boîte Windows locale ne gère que l’interface utilisateur du graphique.
À quoi cela ressemblait en pratique :
- Installez un connecteur/extension dans ComfyUI (celui que j’ai utilisé s’étiquetait « WaveSpeed » dans la liste Manager). Après l’installation, un nouvel ensemble de nœuds est apparu pour l’exécution à distance.
- Authentifiez-vous ou pointez-le vers un point de terminaison de travail. Le mien utilisait une clé de tableau de bord. La configuration a pris quelques minutes.
- Échangez les chargeur/sampler LTX‑2 locaux contre les équivalents WaveSpeed. Les mêmes invites, la même forme de graphique, juste des nœuds différents.
Ignorez les maux de tête de configuration : testez LTX‑2 instantanément sur WaveSpeed — pas de GPU local, pas de remaniement de pilote, entrez juste votre invite et commencez le rendu.
Si vous êtes curieux, consultez la documentation officielle du connecteur pour les étapes de configuration actuelles. Je ne reconstructirais pas mon flux de travail entier autour de cela, mais en tant que chemin sans CUDA, c’était rafraîchissamment ennuyeux, dans le bon sens.
Articles associés

Seedance 2.0 arrive bientôt : Le modèle vidéo nouvelle génération de ByteDance avec audio natif

Guide Complet Seedance 2.0 : Création Vidéo Multimodale

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1 : La Comparaison Ultime de la Génération Vidéo

Guide Complet Seedream 5.0-Preview : Génération d'Images Intelligente

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image : Comparaison Complète
