Contexte de 1M de Tokens DeepSeek V4 : Comment Interroger des Bases de Code Complètes

Je vais traduire cet article en français pour vous.
Hé mes amis. Je m’appelle Dora. La première fois que j’ai jeté un projet complet dans la fenêtre de 1M tokens de DeepSeek V4, je ne me suis pas sentie puissante. Je me suis sentie prudente. Un million de tokens semble être du café sans fin, mais quiconque a essayé de réfléchir pendant des heures sous l’effet de la caféine sait que les limites s’estompent. Je voulais voir si cette nouvelle taille de contexte changerait vraiment ma façon de travailler, ou si elle m’encouragerait simplement à coller plus de code.
J’ai passé quelques jours (27-30 janvier 2026) à utiliser DeepSeek V4 avec 1M tokens sur trois tâches que je rencontre souvent :
- lire un monorepo de taille moyenne sans le configurer localement,
- tracer un bug à travers des services qui se parlent trop,
- et demander des suggestions de refactoring qui ne cassent pas les tests.
Ce que j’ai appris : on peut mettre beaucoup de choses, mais le modèle a toujours besoin que tu lui montres la carte. Les gains ne venaient pas du fait de fourrer plus de fichiers : ils venaient de la façon dont j’ai structuré le prompt et de la façon dont j’ai demandé au modèle de progresser.
Ce que 1M tokens signifie vraiment
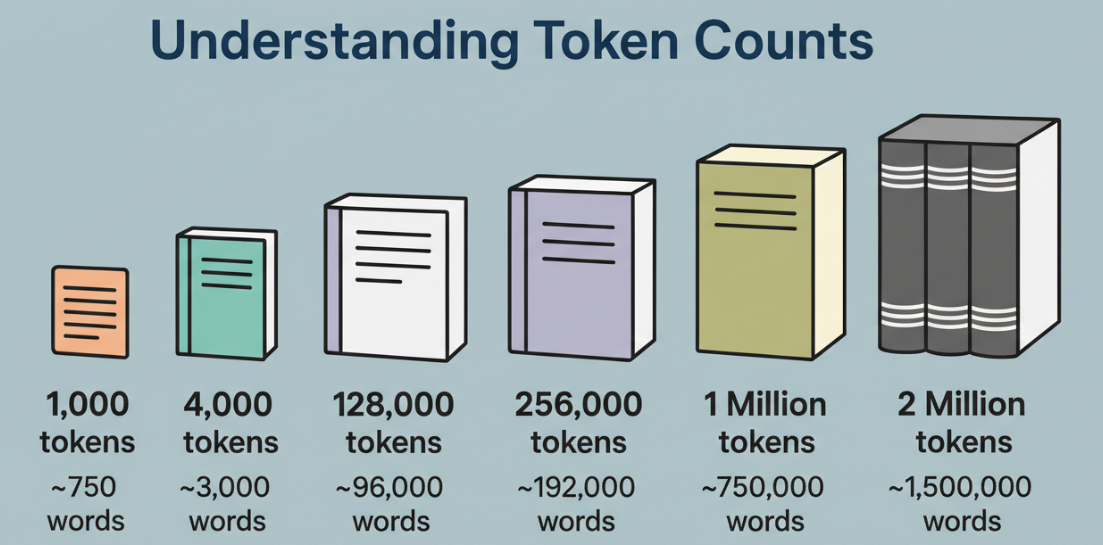 Le nombre en soi ne m’intéresse pas. Ce qui m’intéresse, c’est ce qu’il peut contenir avec un esprit lucide.
Le nombre en soi ne m’intéresse pas. Ce qui m’intéresse, c’est ce qu’il peut contenir avec un esprit lucide.
Un token n’est pas un mot. C’est un chunk, parfois un mot complet, parfois une partie, parfois de la ponctuation. Dans les textes en anglais, j’ai l’habitude de traiter 1 token comme ~0,75 mots pour la planification. Pour le code, les tokens arrivent vite : accolades, points, noms de méthodes, tout découpé. Un million de tokens, c’est beaucoup de territoire, mais ce n’est pas une attention infinie.
Ce qui a changé pour moi cette semaine : j’ai arrêté de réduire aussi agressivement. Avec des contextes de 128K, j’aurais résumé agressivement et gardé seulement le chemin chaud. Avec 1M, j’ai pu garder le chemin chaud plus les fichiers “froids” qui tendent à me surprendre plus tard (config, migrations, scripts de build, glue de workflow). Cela dit, si j’avais tout jeté d’un coup, les réponses auraient été vagues. Quand j’ai alimenté le modèle par étapes, avec des jalons clairs, les résultats se sont sentis ancrés.
Équivalent en lignes de code
Les calculs approximatifs que j’ai utilisés en travaillant :
- Beaucoup de repos mélangent code et docs. Dans les dossiers lourds en code, j’ai vu ~2-3 tokens par caractère dans les langages denses, mais un raccourci pratique : pense à ~4 tokens par ligne pour les lignes simples, ~8-12 pour les vraies lignes du monde réel avec indentation, noms et commentaires.
- À ce rythme, 1M tokens tient quelque part autour de 80K-150K lignes de code, selon le style et la langue. Un service TypeScript avec commentaires et nommage respectueux des linters se situe du côté supérieur. Les bundles minifiés font exploser le compte et ne valent pas la peine d’être inclus.
En pratique, mon “ajustement sûr” était ~60K lignes de source significative + docs et tests ciblés. Je pouvais aller plus haut, mais la latence grimpait et les réponses s’amollissaient. Vos résultats varieront selon les règles du tokenizer et le mélange de langues.
vs les modèles actuels (128K)
Passer de 128K à 1M ressemble moins à un sac à dos plus grand et plus à apporter un chariot. Tu peux porter plus, mais tu ne courras pas.
Ce que j’ai remarqué :
- Latence : Les prompts de contexte complet ont pris notablement plus de temps. Quand j’ai segmenté la session (étape par étape), la latence s’est sentie gérable.
- Rappel : Avec 128K, le modèle “oubliait” souvent les fichiers antérieurs sauf si je répétais la partie clé. Avec 1M, il n’a pas oublié, mais il a parfois généralisé au lieu de citer les spécificités. J’ai eu de meilleurs résultats quand je lui ai demandé de citer les chemins de fichiers et les plages de lignes si possible.
- Précision : Plus le contexte est grand, plus tu as besoin de comportements d’indexation dans ton prompt. Sinon, tu obtiens des résumés compétents qui esquivent les cas limites désordonnés qui t’intéressent vraiment.
Si tu espères que 1M tokens signifie “plus d’engineering de prompt”, je ne compterais pas dessus. Cela change le type de direction que tu fais.
Structure de prompt pour les grandes bases de code
 J’ai arrêté de penser au prompt comme un message et j’ai commencé à le traiter comme un plan de lecture. Le modèle peut lire beaucoup maintenant, mais il bénéficie toujours d’une table des matières et d’une piste.
J’ai arrêté de penser au prompt comme un message et j’ai commencé à le traiter comme un plan de lecture. Le modèle peut lire beaucoup maintenant, mais il bénéficie toujours d’une table des matières et d’une piste.
Ce qui a fonctionné au mieux pour moi ressemblait à ceci : un cadrage du système court, un index de projet concis, un ordre d’exploration déclaré, puis une tâche spécifique. Et puis j’ai maintenu la conversation en tours, pas en un méga-prompt.
Ordre des fichiers
J’ai obtenu des réponses plus fiables quand j’ai dit au modèle quoi ouvrir en premier, deuxième, troisième. Une seule liste en haut l’a aidé à construire une pile mentale :
- Commencer par les points d’entrée (CLI, gestionnaires HTTP, jobs). Cela ancre le flux.
- Puis la couche de composition (conteneur DI, main.ts, app.py) où les dépendances s’assemblent.
- Ensuite, les modules de domaine core et leurs interfaces.
- Seulement après : les helpers, les utils et les pièces transversales (logging, telemetry, config).
- Les tests en dernier, sauf si je débogue une défaillance spécifique, dans ce cas, commencer par la spec défaillante pour fixer les attentes.
J’ai aussi inclus des notes “ne pas lire” pour les dossiers qui semblent importants mais ne le sont pas : code généré, assets compilés, snapshots. Cela a économisé des tokens et a gardé l’attention du modèle sur le code vivant.
Une petite astuce : j’ai demandé au modèle de maintenir une liste roulante de “fichiers actifs” (chemins et courts résumés) et de la mettre à jour au fur et à mesure que nous avancions. Quand il dérivait, je pouvais pointer vers cette liste et dire : “Reste à l’intérieur de cet ensemble pour l’instant.” Cela a gardé les réponses concrètes.
Cartographie des dépendances
L’un des passages les plus utiles était de demander une carte des dépendances tôt, pas comme un diagramme mais comme un simple tableau d’arêtes : le module A importe B, B utilise C, C frappe les variables env, et ainsi de suite. Je l’ai gardé textuel et succinct.
Ce que cela a fait en pratique :
- Cela a exposé des dépendances égarées (le genre qui saigne les préoccupations à travers les dossiers).
- Cela m’a donné une liste de “points de pression” à examiner avant tout refactoring.
- Cela a aidé le modèle à référencer le bon endroit quand j’ai demandé des changements.
J’ai aussi fait énoncer au modèle les hypothèses, ce qu’il avait déduit du nommage, des commentaires ou des tests. Quand une hypothèse était fausse, je la corrigeais une fois, et les étapes suivantes restaient plus propres.
Un avertissement : demander une carte des dépendances complète sur un grand repo en un seul coup a mené à des timeouts et des graphiques vagues. J’ai obtenu de meilleurs résultats en la scop par couche (par exemple, seulement data-access, seulement HTTP handlers) puis en fusionnant les notes moi-même. Cela m’a pris 10 minutes supplémentaires mais a payé en précision.
Stratégies de chunking quand c’est nécessaire
 Même avec une fenêtre de 1M tokens, j’ai toujours segmenté. Non pas parce que ça ne pouvait pas tenir, mais parce que ma réflexion était meilleure par étapes, et le modèle répondait plus précisément quand je réduisais son champ de vision.
Même avec une fenêtre de 1M tokens, j’ai toujours segmenté. Non pas parce que ça ne pouvait pas tenir, mais parce que ma réflexion était meilleure par étapes, et le modèle répondait plus précisément quand je réduisais son champ de vision.
Quelques modèles qui se sont maintenus cette semaine :
- Mettre en scène le brief : j’ai commencé avec un petit contexte, un index de projet, une tâche, des contraintes connues, puis j’ai demandé un plan de lecture et de vérification. C’est seulement après cela que j’ai alimenté le code dans l’ordre sur lequel nous nous étions mis d’accord.
- Limiter l’ensemble actif : Pour un refactoring, j’ai gardé juste les 5-12 fichiers en jeu et j’ai demandé des changements avec des chemins explicites. Si une édition touchait un util partagé, j’ajoutais ce fichier au tour suivant. Le modèle restait plus serré.
- Résumer aux bords : Avant de passer à un nouveau dossier, j’ai demandé un court résumé de ce que nous avions appris et de toute incertitude. Ces résumés agissaient comme des miettes de pain à travers les tours sans re-paster chaque fichier.
- Utiliser la retrieval de manière intentionnelle : Pour les repos qui ne s’ajustaient pas confortablement, j’ai utilisé des embeddings pour appeler les fichiers par requête (“normalisation d’ID de paiement”, “retry backoff”). J’ai gardé l’ensemble récupéré petit par tour, généralement moins de 40K tokens, pour que les réponses ne se brouillent pas.
- Vérifier en avant, pas en arrière : Au lieu de demander, “Avez-vous utilisé tout ce que j’ai collé ?” j’ai demandé, “Pointez les fonctions et lignes spécifiques sur lesquelles votre suggestion dépend.” Cela a forcé des références concrètes et a rendu les erreurs évidentes.
Les frictions que j’ai rencontrées :
- La latence augmente quand tu envoies des messages de contexte complet à chaque tour. La mise en scène a réduit mon temps de réponse moyen de 70-90s à 20-40s sur les mêmes tâches.
- Le coût compte. Les gros prompts s’additionnent. J’ai économisé des tokens en coupant les commentaires qui restaientait l’évident, en supprimant les artefacts compilés et en sautant les bundles de fournisseurs.
- Les effets de position sont réels. Le contenu au tout début ou à la fin d’un énorme prompt tend à être plus “disponible”. J’ai contré cela en répétant les petites contraintes critiques près de la fin de chaque tour.
Qui bénéficie de la fenêtre 1M ?

- Si tu vis dans des monorepos, traites des audits ou fais des refactorings transversales, cela t’achète moins d’étapes de configuration et moins de frais généraux d’indexation locaux. C’est un point de départ plus calme.
- Si ton travail est surtout des corrections de bugs focalisées dans les petits services, la capacité supplémentaire ne t’aidera pas beaucoup. Un contexte plus petit plus un pipeline de retrieval serré se sentira plus rapide.
Une note sur la confiance : j’ai demandé au modèle de citer les lignes de code exactes pour les changements risqués (migrations, auth). Quand il hésitait ou paraphrasait, je traitais cela comme un drapeau pour réduire le scope ou repaster le fichier spécifique. Cette petite habitude a prévenu quelques près-ratés.
Si tu veux la description formelle des limites du modèle ou du comportement du tokenizer, consulte la docs du fournisseur. Quand j’avais besoin de spécificités, je revenais à la carte de modèle officielle et aux notes de fenêtre de contexte. Cela m’a gardée honnête sur ce que je demandais au modèle de faire.
Ce n’est pas de la magie. C’est juste une plus grande table. Utile, si tu arranges les chaises.
Je n’arrête pas de penser à une petite chose de mardi : j’ai demandé une correction, et le modèle a suggéré de changer une fonction qui avait l’air correcte à première vue. Ce n’était pas ça. Le bug vivait dans un helper deux couches plus bas. Un million de tokens n’a pas changé ça. Mes notes ont changé ça.
Articles associés

Seedance 2.0 arrive bientôt : Le modèle vidéo nouvelle génération de ByteDance avec audio natif

Guide Complet Seedance 2.0 : Création Vidéo Multimodale

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1 : La Comparaison Ultime de la Génération Vidéo

Guide Complet Seedream 5.0-Preview : Génération d'Images Intelligente

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image : Comparaison Complète
