¿Qué es TranslateGemma? Modelo de Traducción Open AI Explicado

¡Hola, a todos! Soy Dora. Ese día, estaba editando un boletín bilingüe y no paraba de pasar entre borradores, capturas de pantalla y pestañas de Google Translate. Nada de eso era terrible. Solo era… ruidoso. Sabes de qué tipo. Quería algo tranquilo que pudiera estar dentro de mi flujo de trabajo, no al lado de él.
Así que a principios de esta semana (enero de 2026), probé TranslateGemma. No esperaba mucho al principio, otro modelo “abierto” con un nombre reluciente. Pero después de algunas pruebas dentro de un cuaderno y luego una pequeña herramienta interna, noté algo sutil: la carga mental bajó. No estaba jugando con pestañas. No estaba vigilando tanto la redacción. Se sentía como un traductor que podía tener en mi escritorio, no al otro lado de la sala.
Qué es TranslateGemma
 TranslateGemma es una familia de modelos de traducción abiertos construida sobre la arquitectura Gemma de Google. En términos simples: es un conjunto de modelos de lenguaje ajustados específicamente para tareas de traducción, con tamaños que realmente puedes ejecutar localmente o escalar en la nube.
TranslateGemma es una familia de modelos de traducción abiertos construida sobre la arquitectura Gemma de Google. En términos simples: es un conjunto de modelos de lenguaje ajustados específicamente para tareas de traducción, con tamaños que realmente puedes ejecutar localmente o escalar en la nube.
Algunas cosas me llamaron la atención mientras realmente lo estaba usando:
- Está ajustado específicamente para traducción. No tienes que obligar a un LLM general a comportarse. Los indicadores permanecen limpios.
- Maneja el contexto mejor que una simple API de oración por oración. Los párrafos con modismos, nombres de productos y pistas de tono ligero pasaron con menos “parches planos”.
- Es tranquilo. El resultado no es llamativo ni adicto a la paráfrasis. Para documentos de trabajo, eso es un alivio.
En papel, TranslateGemma se sitúa entre asistentes completamente generativos y traductores clásicos basados en frases. En la práctica, es un traductor que respeta el significado de la fuente mientras suaviza el idioma de destino. Cuando le pasé una nota de lanzamiento corta con una mezcla de etiquetas de interfaz de usuario y líneas conversacionales, mantuvo las etiquetas intactas y aun así hizo que la copia se leyera naturalmente. Ese equilibrio fue lo que me hizo seguir probando.
La licencia está en la familia Gemma: permisiva para muchos usos comerciales con restricciones de IA responsable. Si la estás integrando en un producto, lee la licencia en el repositorio oficial o en la entrada de Model Garden. Es la parte aburrida, pero importa.
Tamaños de Modelo: 4B, 12B y 27B
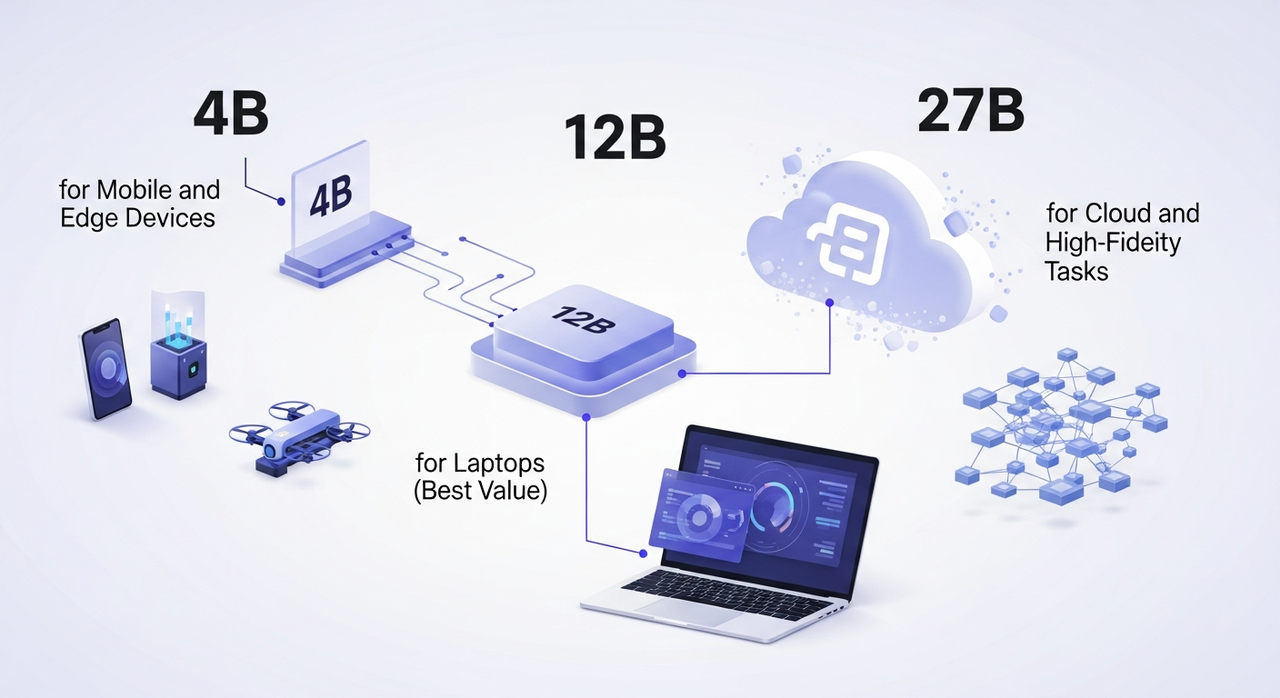 TranslateGemma viene en tres tamaños. Misma familia, diferentes compensaciones. Hice pequeñas pruebas en cada uno durante dos días, unas pocas páginas de producto, una secuencia de correo electrónico y un resumen de investigación en español, francés y japonés.
TranslateGemma viene en tres tamaños. Misma familia, diferentes compensaciones. Hice pequeñas pruebas en cada uno durante dos días, unas pocas páginas de producto, una secuencia de correo electrónico y un resumen de investigación en español, francés y japonés.
4B para Dispositivos Móviles y Edge
Probé una compilación de 4B cuantizado de 4 bits en un teléfono Android reciente y una Raspberry Pi 5 (solo para ver). La latencia en el teléfono fue aceptable para oraciones cortas (menos de un segundo por línea), y los resultados fueron limpios para copias directas: cadenas de interfaz de usuario, texto de ayuda, títulos cortos. Cualquier cosa con tono en capas o cláusulas anidadas comenzó a tambalear. Esa fue mi señal para dejar de forzarlo.
Lo que funcionó:
- Traducción en el dispositivo de cadenas de aplicaciones sin enviar datos a un servidor.
- Borradores rápidos para títulos de redes sociales en un segundo idioma.
Límites que encontré:
- Los párrafos más largos adquirieron rigidez. Mantuvo el significado, perdió la música.
- El texto de código mixto (EN + un segundo idioma) a veces se normalizó demasiado.
Si necesitas traducción en el borde, quioscos, aplicaciones sin conexión, flujos de trabajo sensibles a la privacidad, 4B es el pequeño martillo que cabe en tu bolsillo. Para la escritura diaria, lo trataría como un primer paso, no como el borrador final.
12B para Portátiles (Mejor Relación Calidad-Precio)
Este es al que seguí volviendo. En mi portátil (32 GB de RAM, GPU de consumidor), el modelo 12B en 4–8 bits funcionó cómodamente con indicadores a nivel de párrafo. Latencia promedio: 1–2 segundos para unas pocas oraciones, tal vez 5–8 segundos para un párrafo denso. Eso está en el rango “no interrumpe el pensamiento”.
La calidad se sintió equilibrada: menos literal que 4B, menos ornamental que LLMs más grandes que aman reformular. Cuando traduje un pequeño caso de estudio del francés al inglés, preservó la estructura e espejeó el énfasis de la oración sin agrupar todo en un solo tono. Los nombres, términos de productos y citas se mantuvieron en su lugar.
Donde brilla:
- Correos electrónicos de marketing que necesitan tono pero no poesía.
- Documentación, notas de lanzamiento y copia de interfaz de usuario donde la claridad vence al adorno.
- Trabajos por lotes en un portátil: 50–200 párrafos a la vez sin factura de nube.
Donde todavía lo ajusto:
- Las líneas adyacentes a la poesía (líneas de gancho, eslóganes) a veces se leen seguras. Un paso rápido lo arregla.
- Los artículos altamente técnicos pueden volverse literales. Agregar “mantener registro académico formal” en el indicador ayudó.
27B para Tareas en la Nube y de Alta Fidelidad
Giré el modelo 27B en una A100 individual en la nube. Es la opción para equipos que se preocupan por los matices y pueden justificar infraestructura. La latencia fue buena para uso interactivo pero obviamente no amigable con dispositivos móviles.
Lo que noté:
- Mantuvo pistas estilísticas en secciones más largas. En texto legal de japonés a inglés, mantuvo formalidad sin sonar afectado.
- Manejó mejor los pronombres ambiguos. Menos referentes incompatibles en los párrafos.
- Para pares de idiomas de bajo recursos, no hizo milagros, pero falló de manera más elegante, menos términos alucinados.
Para ser honesto, si estás traduciendo contenido de larga extensión para publicación, o necesitas consistencia en miles de segmentos, 27B se justifica. Para equipos pequeños, solo lo usaría cuando la fidelidad del tono es innegociable o necesitas estandarizar resultados a escala.
TranslateGemma vs Google Translate
 No estoy aquí para reemplazar Google Translate apresuradamente. Es rápido, está en todas partes, y para búsquedas rápidas sigue siendo el camino más rápido de “¿qué significa esto?” a “entendido.” Pero las compensaciones son diferentes.
No estoy aquí para reemplazar Google Translate apresuradamente. Es rápido, está en todas partes, y para búsquedas rápidas sigue siendo el camino más rápido de “¿qué significa esto?” a “entendido.” Pero las compensaciones son diferentes.
Donde TranslateGemma se sintió mejor en mis pruebas:
- Ventanas de contexto: Podría soltar un párrafo o dos completos y mantener tono y referencias intactos. Google Translate a menudo acierta en el significado pero aplana el estilo cuando el contexto es desordenado.
- Personalización: Una instrucción de una línea como “preservar nombres de productos, mantener contracciones” formó de manera confiable el resultado. Con Google Translate, obtienes lo que obtienes.
- Privacidad/control: Ejecutar localmente (4B/12B) o en una nube privada reduce la exposición de datos. Sin cambio de pestañas, sin llamadas externas si no las quieres.
Donde Google Translate sigue ganando:
- Amplitud y conveniencia: Más de 100 idiomas, acceso web instantáneo, OCR, entrada de cámara móvil. Es la navaja suiza.
- Velocidad a escala para uso casual: Si solo necesito una oración rápida, TranslateGemma es excesivo a menos que ya esté integrado en mi editor.
- Colaboración sin fricción: Es fácil compartir a alguien una página de Google Translate y decir “¿está cerca?”
En términos de costo, TranslateGemma cambia el gasto de tarifas de API por solicitud a computación. Si ya tienes una GPU decente o una configuración modesta en la nube, puede ser más barato para uso sostenido. Si no, el nivel gratuito de Google Translate es difícil de argumentar.
La calidad está más cerca de lo que esperaba. TranslateGemma fue menos literal de manera buena, modesto, no llamativo. Google Translate ha mejorado el manejo del tono, pero aún se lee como un diccionario que fue a escuela de buenos modales. Si escribes para personas, esa brecha importa.
Mi regla de oro después de una semana: Todavía recurro a Google Translate para verificar una línea en un idioma que apenas conozco. Recurro a TranslateGemma cuando me importa cómo suena, no solo qué dice.
Una vez que decidí que TranslateGemma era el ajuste correcto, la siguiente pregunta fue dónde realmente ejecutarlo sin convertir la configuración en un proyecto en sí mismo.
Es exactamente por eso que construimos WaveSpeed. Nuestro equipo lo usa para girar ambientes GPU limpios, ejecutar trabajos de traducción por lotes y seguir adelante, sin vigilar controladores, colas o scripts temporales.
Dónde Obtener TranslateGemma
Extraje modelos de los lugares habituales:
- Hugging Face: Lo más fácil para pruebas rápidas con Transformers o Text Generation Inference. Busca “TranslateGemma” y verifica la tarjeta para licencia y variantes cuantizados.
- Model Garden de Google (Vertex AI): Implementación gestionada, autoescalado, puntos finales privados. Si tu equipo ya vive en GCP, es el camino más suave.
- Modelos de Kaggle: Útil para notebooks de un clic y evaluación rápida si no quieres preparar infraestructura todavía.
- GitHub + Colab: Los andamios comunitarios aparecen rápidamente, cargadores, plantillas de indicadores y scripts básicos de evaluación.
Notas de configuración de mi ejecución:
- La cuantización ayuda. 4–8 bits hizo que el modelo 12B fuera cómodo en una GPU de consumidor sin destrozar el resultado. No perdí los bits extra.
- Los indicadores permanecen cortos. “Traducir al inglés. Preservar nombres de productos. Mantener contracciones.” Eso es suficiente la mayoría de las veces.
- Lotes con cuidado. Divide por párrafos o grupos de viñetas. La oración por oración funciona, pero pierdes el pegamento del tono.
Si necesitas barandillas o control de glosario, agrega un paso ligero de preprocesamiento/posprocesamiento:
- Pre-marca nombres de productos con etiquetas (por ejemplo, ) y pide al modelo que los preserve.
- Post-verifica con un comparador de glosario para detectar desviaciones en términos como “Sign in” vs “Log in”.
Quién creo que le gustará TranslateGemma
- Escritores y comercializadores que quieren borradores locales de calidad decente sin cambiar de herramientas.
- Equipos de productos que agregan traducción silenciosamente dentro de una aplicación, no externalizando a otro servicio más.
- Investigadores que se preocupan por que párrafos largos y referencias se mantengan intactos.
Quién probablemente no
- Cualquiera que necesite traducción instantánea de cámara en vacaciones, usa Google Translate.
- Equipos que no quieren gestionar ninguna computación. Una API pagada con SLA puede ser más tranquila.
No esperaba mantenerlo. Pero ha estado en mi flujo de trabajo toda la semana porque me pide menos: menos pestañas, menos recordatorios, menos pequeñas decisiones. Esa es usualmente mi señal. ¿Y la pequeña sorpresa? Confío en él con el tono de un párrafo, no solo con las palabras. Tu experiencia puede variar, pero si estás sintiendo el ruido de demasiadas herramientas, esta se mantiene tranquila. Por eso se quedó conmigo.
Artículos relacionados

Seedance 2.0 Próximamente: El Modelo de Video de Próxima Generación de ByteDance con Audio Nativo

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: La Comparación Definitiva de Generación de Video

Guía Completa de Seedance 2.0: Creación de Vídeo Multimodal

Guía Completa de Seedream 5.0-Preview: Generación Inteligente de Imágenes

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Comparación Completa
