Demo en Línea de TranslateGemma + Guía de Inicio Rápido

Hola, soy Dora. ¿Has oído hablar de “TranslateGemma”?
El impulso para esto fue pequeño: un cliente envió texto con inglés y español mezclados más algunos marcadores de posición traviesos, y no quería supervisar un modelo de traducción línea por línea. Ya sabes el tipo: un paso en falso y los marcadores de posición implosionan. Seguía viendo “TranslateGemma” aparecer en hilos de discusión, así que lo probé, no porque fuera nuevo, sino porque quería una forma más tranquila de obtener traducciones fieles sin arruinar el formato. Spoiler: entregó principalmente lo que prometía. Lo probé durante enero de 2026 en varios demostradores en línea y una configuración local. Aquí está lo que realmente ayudó, dónde se tambaleó, y cómo terminé estructurando los prompts para mantenerlo estable.
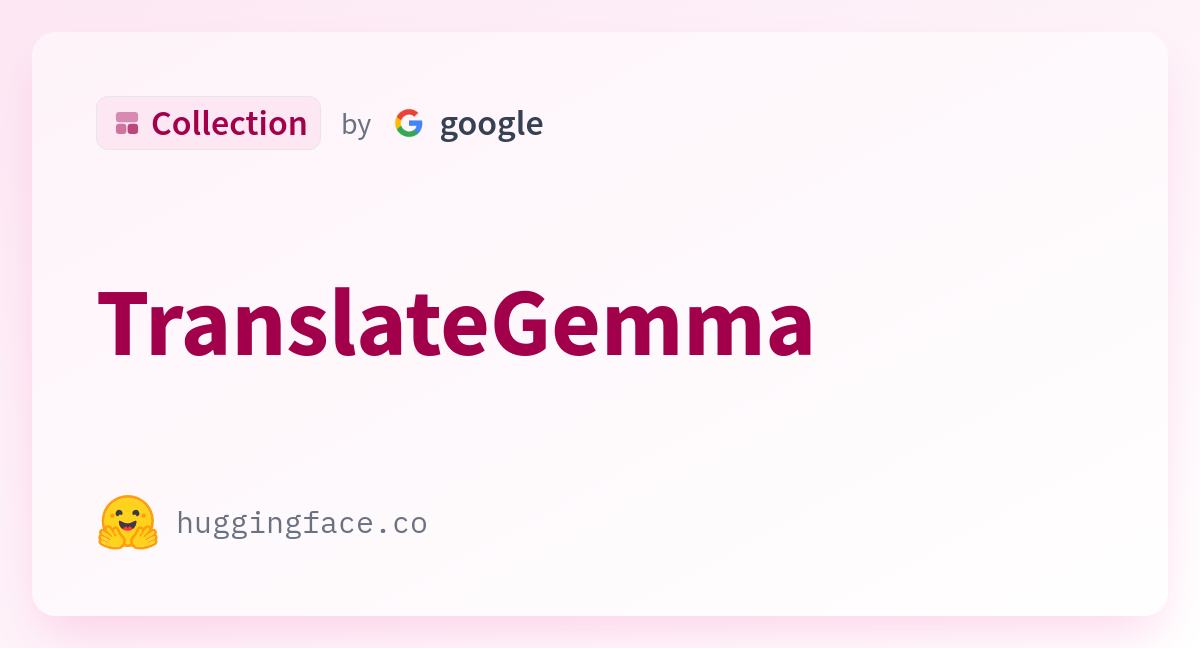
Prueba TranslateGemma en Línea (Sin Configuración)
No me encanta instalar cosas solo para ver si son útiles. Así que comencé con TranslateGemma en línea. Si buscas “TranslateGemma online”, encontrarás un puñado de campos de pruebas alojados: Hugging Face Spaces, demostradores de Replicate, y algunas interfaces web ligeras que envuelven puntos de control basados en Gemma ajustados para traducción. Algunos requieren un inicio de sesión gratuito; otros no. De cualquier forma, normalmente puedes pegar texto y seleccionar idiomas.
Lo que me sorprendió: la velocidad era buena incluso en demostradores compartidos. Los párrafos cortos regresaban en uno o dos segundos; las páginas más largas tardaban un poco más, pero no lo suficiente como para empujarme hacia el café. Seguía mirando la pantalla de todas formas. Un hábito antiguo, supongo. La mayor diferencia no era la velocidad, sino cómo estructuraba el prompt.
Un simple “Traducir al francés” funcionó, pero los resultados se desviaban cuando el texto mezclaba tonos, contenía código en línea, o usaba variables como {{first_name}}. La solución fue un conjunto de instrucciones corto y explícito. Cuando el demostrador exponía un campo “system prompt”, lo usaba. Cuando no lo hacía, ponía la instrucción al inicio del mensaje del usuario.
Aquí está el prompt mínimo que consistentemente redujo la limpieza para mí:
- Nombra los idiomas de origen y destino.
- Dile al modelo qué mantener sin cambios (marcadores de posición, bloques de código, etiquetas).
- Delimita el texto para que el modelo sepa dónde comienza y termina.
- Pide traducción pura sin comentarios.
Ejemplo que usé en línea:
Ejemplo que usé en línea:
Traduce lo siguiente del inglés al español. Mantén marcadores de posición como {{first_name}}, {{price}}, y etiquetas HTML sin cambios. Preserva saltos de línea y puntuación. Devuelve solo el texto traducido, nada más.
<<<
Subject: Welcome, {{first_name}}.
Your total is {{price}}.
Click <a href="/start">here</a> to begin.
>>>Esto no ahorró tiempo la primera vez. Después de dos ejecuciones, lo hizo, principalmente porque dejé de arreglar marcadores de posición rotos. Si solo estás verificando TranslateGemma en línea, prueba un pasaje corto con y sin esa estructura. La diferencia se muestra rápidamente.
Formato de Plantilla de Chat que Debes Seguir
 Los modelos de chat al estilo Gemma responden mejor cuando respetas los marcadores de turno. Algunas interfaces los añaden automáticamente. Otras esperan texto sin procesar. Si envías prompts directamente (API, Python, o una interfaz básica), una plantilla clara y repetible ayuda.
Los modelos de chat al estilo Gemma responden mejor cuando respetas los marcadores de turno. Algunas interfaces los añaden automáticamente. Otras esperan texto sin procesar. Si envías prompts directamente (API, Python, o una interfaz básica), una plantilla clara y repetible ayuda.
Dos patrones confiables funcionaron para mí:
1. Plantilla de texto plano (funciona en la mayoría de demostradores web)
Eres un asistente de traducción preciso.
- Idioma de origen: inglés
- Idioma de destino: español
- Mantén marcadores de posición como {{...}}, acentos graves de markdown, y etiquetas HTML sin cambios.
- Preserva puntuación y saltos de línea. No agregues explicaciones.
Texto a traducir:
<<<
[PEGA TU TEXTO]
>>>2. Estilo de turno de chat Gemma (útil en bibliotecas que exponen la plantilla de chat)
<start_of_turn>user
Eres un asistente de traducción preciso.
Origen: inglés
Destino: español
Reglas: mantén {{placeholders}}, bloques de código, y HTML intactos: preserva saltos de línea: solo resultado de traducción.
Texto:
<<<
[PEGA TU TEXTO]
>>>
<end_of_turn>
<start_of_turn>modelNo esperaba que los marcadores de turno importaran tanto, pero lo hacen. Sin ellos, vi más “parafraseo útil” (el modelo intentando mejorar la redacción). Con ellos, y con entrada delimitada, el modelo se mantuvo más cerca de la tarea.
Detalles diminutos que marcaron una gran diferencia:
- Nombra los idiomas explícitamente. “Del inglés al español” funcionó mejor que “Traducir al español”.
- Pon las reglas antes del texto. Si terminas las reglas después del texto, es más fácil ignorarlas.
- Delimita el texto con un inicio/parada distinto (
<<<y>>>o triple acentos graves). Esto redujo el recorte accidental al principio o al final.
Ejecuta TranslateGemma Localmente (Python)
 Me gusta tener una alternativa local para trabajos más largos o borradores sensibles. Llámame paranoica, pero a veces la nube se siente demasiado… locuaz. En mi máquina (32 GB de RAM, GPU de consumidor), un punto de control de traducción más pequeño basado en Gemma funcionaba cómodamente: los más grandes necesitaban más VRAM o cuantización. Si solo tienes CPU, es lento pero posible con configuraciones cuidadosas.
Me gusta tener una alternativa local para trabajos más largos o borradores sensibles. Llámame paranoica, pero a veces la nube se siente demasiado… locuaz. En mi máquina (32 GB de RAM, GPU de consumidor), un punto de control de traducción más pequeño basado en Gemma funcionaba cómodamente: los más grandes necesitaban más VRAM o cuantización. Si solo tienes CPU, es lento pero posible con configuraciones cuidadosas.
Aquí hay un patrón simple con Hugging Face Transformers. He mantenido el model_id genérico a propósito, elige un modelo de traducción basado en Gemma o derivado de Gemma en el que confíes desde el Hub, idealmente uno documentado para traducción. La plantilla a continuación refleja los prompts en línea.
# Probado en enero de 2026 con transformers >= 4.40
from transformers import AutoTokenizer, AutoModelForCausalLM, TextStreamer
import torch
model_id = "<your-gemma-translation-checkpoint>" # p.ej., un modelo de chat Gemma o ajustado para traducción
device = "cuda" if torch.cuda.is_available() else "cpu"
dtype = torch.float16 if device == "cuda" else torch.float32
# Cargar
tokenizer = AutoTokenizer.from_pretrained(model_id, use_fast=True)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=dtype,
device_map="auto" if device == "cuda" else None
)
# Plantilla de prompt (texto plano). Cambia por turnos de chat si tu modelo lo requiere.
prompt = (
"Eres un asistente de traducción preciso.\n"
"Idioma de origen: inglés\n"
"Idioma de destino: español\n"
"Reglas: mantén marcadores de posición como {{...}}, bloques de código, y etiquetas HTML sin cambios: "
"preserva puntuación y saltos de línea: solo resultado de traducción.\n\n"
"Texto:\n<<<\n"
"Subject: Welcome, {{first_name}}.\nYour total is {{price}}.\n"
"<p>Click <a href=\"/start\">here</a> to begin.</p>\n"
">>>\n"
)
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
gen = model.generate(
**inputs,
max_new_tokens=300,
temperature=0.3,
top_p=0.9,
repetition_penalty=1.02,
do_sample=True,
eos_token_id=tokenizer.eos_token_id,
)
output = tokenizer.decode(gen[0][inputs["input_ids"].shape[1]:], skip_special_tokens=True)
print(output)Algunas notas de las pruebas
- Si tu punto de control incluye una plantilla de chat, usa la utilidad
apply_chat_template()de la biblioteca en lugar de cadenas manuales. Corta comportamientos extraños a la mitad. - Para entradas largas, establece
max_new_tokenslo suficientemente alto y manténtemperaturebaja (0.2–0.4). El muestreo más cálido invitaba “mejoras”. Algunas útiles, otras… no tanto. - La cuantización ayuda en GPUs más pequeñas. 4-bit (bitsandbytes) se mantuvo bien para traducción directa.
- Si necesitas traducción por lotes, envuelve el prompt en una función pequeña y canaliza líneas. Encontré que fragmentar por párrafo era más seguro que bloques gigantes, menos posibilidad de perder estructura.
¿Necesitas ejecutar cargas de trabajo de traducción sin administrar infraestructura de GPU o configuraciones locales?
Construimos WaveSpeed para que nuestro equipo pueda llamar modelos a través de una API unificada y manejar tareas por lotes sin girar servidores o luchar con controladores → Pruébalo!
Errores Comunes y Soluciones
 Estos fueron los patrones que encontré más frecuentemente mientras probaba TranslateGemma en línea y localmente, más lo que realmente redujo la fricción para mí.
Estos fueron los patrones que encontré más frecuentemente mientras probaba TranslateGemma en línea y localmente, más lo que realmente redujo la fricción para mí.
Salida No en Idioma Destino
Vi esto principalmente cuando no declaré el idioma de origen. Las entradas en idioma mixto lo confundieron lo suficiente como para mantener frases en inglés alrededor. Las soluciones que funcionaron:
- Nombra ambos idiomas: “Traduce del inglés al español”. No confíes en la detección cuando la precisión importa.
- Baja la temperatura (0.2–0.4) y usa una
repetition_penaltyligera (alrededor de 1.02). Empujó al modelo lejos de reescrituras creativas. - Añade una línea de guardia final: “Si el texto ya está en español, devuélvelo sin cambios”. Esto redujo la sobretraducción en fragmentos bilingües.
Formato o Marcadores de Posición Perdidos
Este era el grande con correos electrónicos de marketing y cadenas de producto. Las ejecuciones tempranas rompieron {{variables}} o reordenaron HTML. Lo que ayudó:
- Sé explícito: “Mantén marcadores de posición como
{{...}}y etiquetas HTML sin cambios. No traduzcas dentro de cercas de código”. - Delimita la entrada y preserva saltos de línea. El patrón
<<<y>>>funcionó mejor que confiar en líneas en blanco. - Para contenido frágil, rodea marcadores de posición con marcadores en el prompt: “Los marcadores de posición están protegidos con llaves dobles como
{{esto}}. No los alteres”. Si un demostrador seguía soltando llaves, temporalmente reemplazaba{{con[[[y}}con]]]antes de la traducción, luego intercambiaba de vuelta. No es elegante, pero es más seguro para trabajos en lotes.
Modelo Reescribe en Lugar de Traducir
A veces la salida leía como una reescritura del editor, no una traducción. Útil en algunos contextos, molesto en la mayoría. Mis soluciones prácticas:
- Declara el rol y la restricción arriba: “Eres un asistente de traducción. Solo salida de una traducción fiel. Sin resúmenes, sin explicaciones”.
- Baja la temperatura y evita
max_new_tokenslargo en entradas cortas: espacio extra alentó comentarios en algunos puntos de control. - Si el modelo aún se adorna, intenta la plantilla de turno de chat con parada clara. En código local, establece secuencias de parada a tus marcadores de turno (p.ej.,
<end_of_turn>). En demostradores alojados sin soporte de parada, añadir “Devuelve solo el texto traducido” redujo la paja sobre el 80% del tiempo.
Una nota más tranquila: algunos puntos de control comunitarios etiquetados para traducción son en realidad modelos generales ajustados por instrucción. Traducirán, pero son más locuaces. Si estás golpeando los tres problemas a la vez, intenta un punto de control diferente o uno más pequeño y más estricto. Menos ingenioso a menudo significa más fiel en este carril. Y honestamente, eso era todo lo que necesitaba.
¿Ya has probado TranslateGemma? ¿Cuál es tu prompt favorito para mantener marcadores de posición intactos, o el texto más difícil que lo hizo tropezar? ¡Comparte tus victorias, fracasos, o trucos favoritos abajo!
Artículos relacionados

Seedance 2.0 Próximamente: El Modelo de Video de Próxima Generación de ByteDance con Audio Nativo

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: La Comparación Definitiva de Generación de Video

Guía Completa de Seedance 2.0: Creación de Vídeo Multimodal

Guía Completa de Seedream 5.0-Preview: Generación Inteligente de Imágenes

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Comparación Completa
