Seedance 1.5 Pro: Un Gran Paso Hacia la Generación Nativa de Audio-Visual

Mientras que el video generativo se abre camino hacia la producción real, los elementos visuales por sí solos ya no son suficientes. Los flujos de trabajo modernos requieren cada vez más que el video y el audio se generen juntos —de forma nativa y sincronizados.
Seedance 1.5 Pro, el modelo de nueva generación de ByteDance para la co-generación nativa audiovisual, ahora está disponible en WaveSpeedAI. Construido desde cero para una sincronización confiable, controlable y lista para producción, marca un paso importante hacia una verdadera generación multimodal unificada.
En un próximo artículo de enfoque técnico, examinaremos más de cerca Seedance 1.5 Pro —explorando sus capacidades de modelo, casos de uso prácticos, perspectivas de evaluación comparativa, y la arquitectura multimodal detrás de él.
Capacidades Principales del Modelo (Características y Uso Práctico)
1. Generación Audiovisual Nativa con Sincronización de Alta Fidelidad
El avance más fundamental en Seedance 1.5 Pro es su paradigma de generación nativo audiovisual. En una única pasada de inferencia, el modelo produce tanto los fotogramas de video como la pista de audio correspondiente, manteniendo alineados el ritmo del habla, el movimiento labial, el movimiento de personajes y la dinámica de cámara dentro de la misma referencia temporal.
En múltiples rondas de evaluación, Seedance 1.5 Pro superó consistentemente los canales tradicionales de “video + TTS” —especialmente en diálogos largos, movimiento labial rápido, y escenarios de acción con sonido donde los enfoques tradicionales tienden a desincronizarse.
Prompts: Un hombre atractivo se encuentra en la cima de una cresta montañosa envuelta en niebla. Viste ropa outdoor práctica y elegante —una chaqueta cortavientos de color carbón oscuro, pantalones de escalada profesionales, y una mochila sobre ambos hombros. La brisa montañosa le alborota ligeramente el cabello; su expresión es tranquila y resuelta. Detrás de él, nubes y niebla arremolinadas se deslizan entre rocas dentadas, ocasionalmente abriéndose para revelar picos nevados distantes. La cámara se acerca lentamente desde atrás mientras él contempla el abismo de nubes rodantes debajo. En el aire gélido, su aliento se condensa en niebla blanca, añadiendo detalle atmosférico natural. Ligeramente se gira hacia la cámara, sus ojos afilados llenos de determinación inquebrantable, y dice con voz firme y poderosa: “Me gustan los desafíos”.
2. Generación Multilingüe, Multiactor y Consciente de Dialectos
Seedance 1.5 Pro soporta generación audiovisual a través de los principales idiomas globales y dialectos regionales. Preserva el tiempo específico del idioma, fonemas y expresiones, proporcionando sincronización labial precisa y alineación emocional natural —incluso a través de múltiples actores y cambios de idioma rápidos.
Prompts: Un cortometraje cinemático estilo anime japonés que retrata la grandiosidad de un festival de fuegos artificiales de verano. Se hace énfasis en texturas de alto detalle (tela de kimono, cabello, piel), micro-expresiones sutiles, movimiento natural y fluido, y narrativa delicada y emocionalmente rica. Los fuegos artificiales se asemejan a iluminación suave cinemática, mejorando la atmósfera emocional. (prompt omitido…) Ella dice suavemente en japonés: “Me gustas mucho”. El hombre se inclina ligeramente y se resuelve a hablar: “En realidad, tú también me gustas”. (prompt omitido…)
3. Movimiento Expresivo y Desempeño Emocional
Seedance 1.5 Pro va más allá de estrategias de movimiento conservadoras y de bajo riesgo. La animación de personajes muestra mayor amplitud, variación de tempo más rica e intención emocional más clara —manteniendo la estabilidad general.
Las expresiones faciales avanzan desde meramente reconocibles a genuinamente performativas: micro-expresiones, transiciones emocionales y lenguaje corporal se alinean naturalmente con el diálogo hablado. El resultado es movimiento que se siente notablemente más vivo.
Prompts: Un joven astronauta en un traje espacial gastado se sienta en la cabina oscura de una nave espacial. El visor del casco está cubierto de vaho y arañazos, y el panel de control parpadea con luces naranja-amarillas, creando una atmósfera tensa y solitaria. El video comienza con este fotograma de apertura estático. La cámara luego se acerca rápidamente al rostro del astronauta antes de cortar al exterior, revelando la nave espacial corriendo a través de una tormenta de escombros cósmicos similar a una ventisca. Estilo thriller de ciencia ficción. Música de fondo: sintetizadores electrónicos bajos emparejados con cuerdas que se hinchan rápidamente para construir tensión. Efectos de sonido: zumbidos de motor urgentes y ruido de tormenta espacial aullante. Diálogo: “En el vacío del espacio, un movimiento en falso…” seguido de un breve silencio, terminando con: “Mayday… sistemas fallando”.
4. Estética Visual Cinemática y Orientada a Fotorrealismo
Visualmente, Seedance 1.5 Pro se inclina hacia un look natural de acción en vivo en lugar de estilización pesada o efectos sobre-renderizados.
La iluminación, composición, armonía de colores, y profundidad de campo son consistentemente estables, produciendo resultados que se acercan a la cinematografía de grado comercial en lugar de imágenes sintéticas.
Prompts: POV en primera persona desde el asiento delantero de una montaña rusa de acero gigante. La montaña rusa llega a la cima y se sumerge directamente en un túnel oscuro. El paisaje circundante (un parque de diversiones al atardecer) está ligeramente borroso, mientras que el viento se representa como partículas de aire silbante.
5. Adaptación Automática de Duración de Video
Al establecer el parámetro de duración de video en -1, Seedance 1.5 Pro selecciona automáticamente la duración más apropiada dentro de un rango de 4–12 segundos (solo segundos enteros).
El modelo evalúa ritmo narrativo, completitud del movimiento y cierre audiovisual para elegir un punto final natural. Esto reduce generaciones desperdiciadas y sintonización manual causada por duraciones fijas mal elegidas.
Prompts: Estilo de arte de píxeles de 8 bits, un héroe corriendo y saltando bajo la puesta de sol, con efectos de línea de barrido y música de videojuego retro.
6. Efectos Integrados a través del Control de Prompts
Seedance 1.5 Pro incluye una gama de efectos integrados directamente en el modelo base. Estos pueden activarse a través de instrucciones de prompt en lugar de depender enteramente de composición post-producción.
Esto es particularmente valioso para contenido orientado a animación o estilizado —como cómics en movimiento— donde la densidad y tiempo de efectos son críticos.
Desempeño de Generación de Video
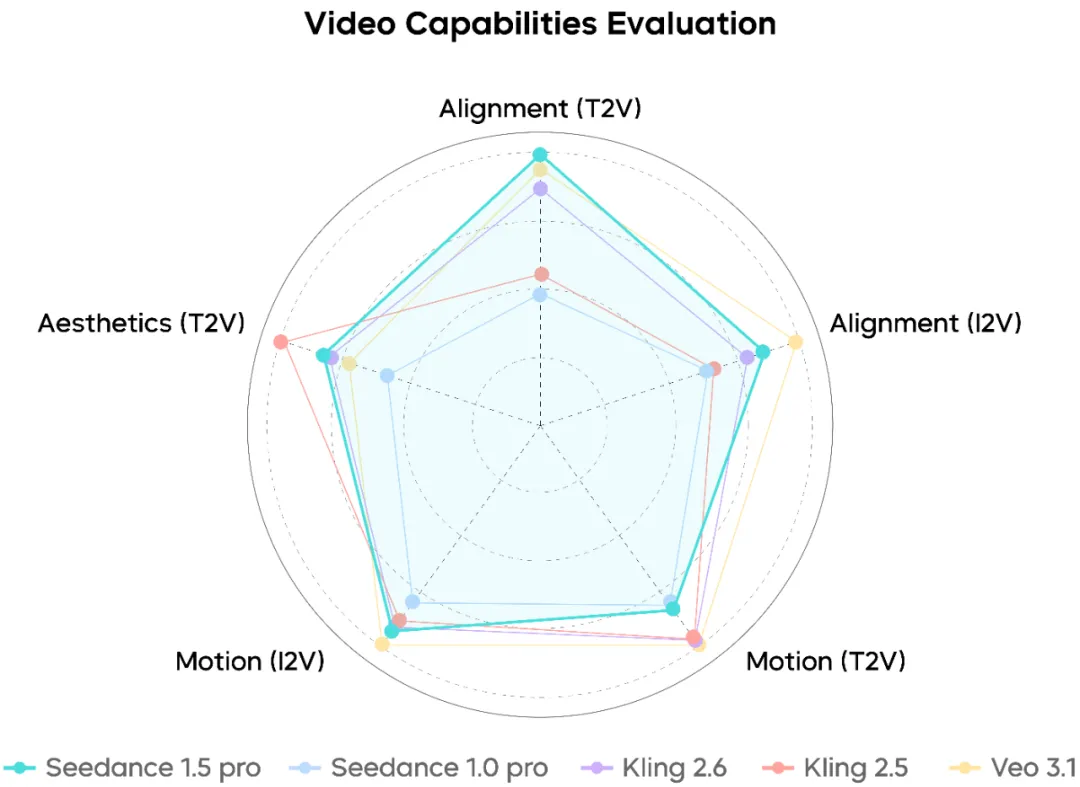
Seedance 1.5 Pro demuestra una fuerte comprensión de prompts complejos que involucran coreografía de cámara, secuenciación de acciones y ritmo narrativo. Los primeros planos faciales se ven naturales, mientras que las tomas largas y movimientos de cámara compuestos se mantienen relativamente suaves y coherentes.
Dicho esto, bajo escenarios de movimiento de intensidad extremadamente alta, todavía hay espacio para mejoras adicionales de estabilidad.
Desempeño de Generación de Audio
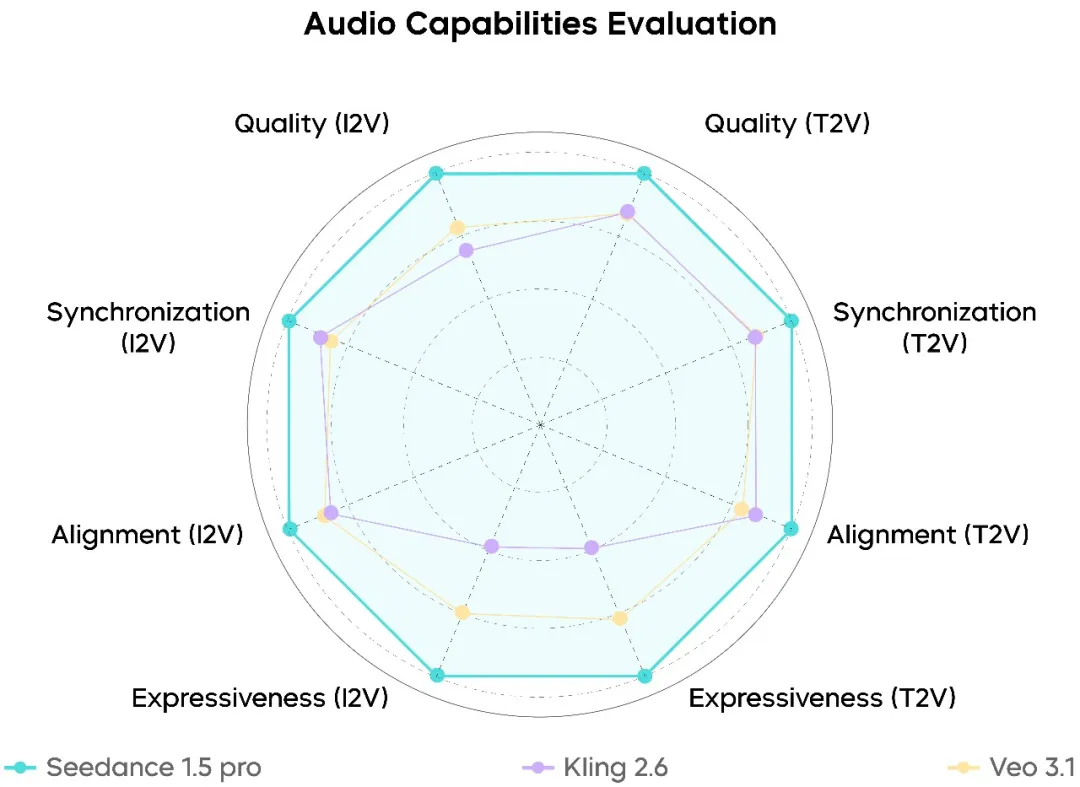
En el lado del audio, Seedance 1.5 Pro se ubica firmemente en el nivel superior de los modelos actuales:
- Voces humanas altamente naturales con artefactos mecánicos reducidos
- Características de audio espacial y reverberación más realistas
- Significativamente menos errores de alineación audiovisual
El desempeño es particularmente sólido en diálogos en chino y cargados de dialectos, donde la completitud de pronunciación y claridad ya cumplen requisitos de producción real.
Arquitectura de Co-Generación Multimodal: Cómo la Visión y el Audio se Mantienen Sincronizados
Seedance 1.5 Pro no es un parche de módulos independientes —su canalizamiento de entrenamiento e inferencia fue rediseñado de extremo a extremo.
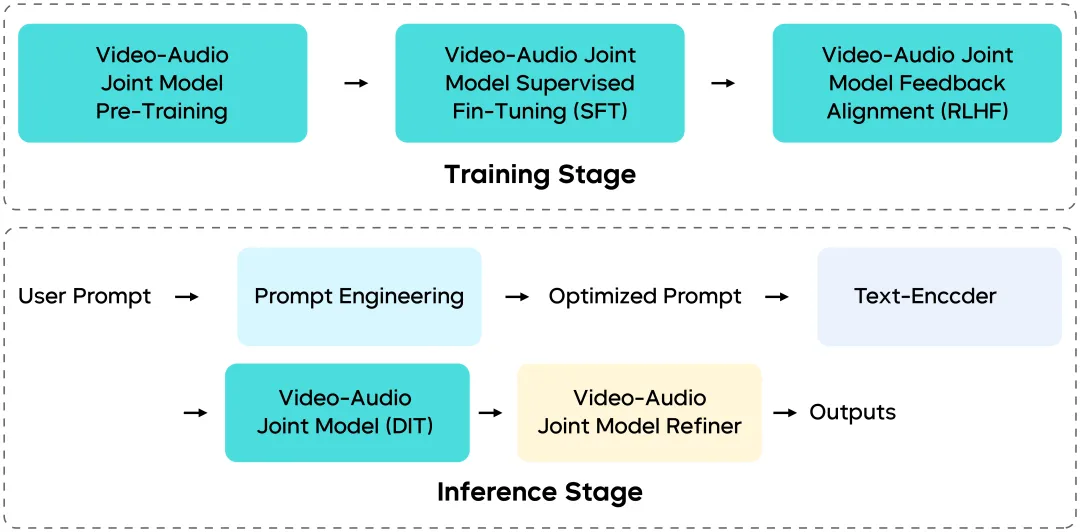
Arquitectura Multimodal Unificada (Basada en MMDiT)
Construida en una arquitectura de estilo MMDiT mejorado, el modelo permite interacción profunda entre flujos visuales y de audio dentro del mismo espacio temporal, asegurando:
- Sincronización temporal
- Consistencia semántica
- Emoción y ritmo coordinados
El entrenamiento multimodal a gran escala y multitarea mejora aún más la generalización a través de tareas descendentes.
Canalizamiento de Datos Multi-Etapa
El canalizamiento de datos está diseñado para equilibrar:
- Alineación audiovisual
- Expresividad del movimiento
- Calendarios de entrenamiento basados en currículum
Además de datos tradicionales de video-caption, descripciones de audio estructuradas se introducen sistemáticamente, permitiendo que el modelo internalice un espacio semántico audiovisual conjunto más rico.
Entrenamiento Posterior de Grano Fino e RLHF
Conjuntos de datos audiovisuales de alta calidad se utilizan para sintonización supervisada, junto con modelos RLHF específicamente diseñados para salida audiovisual, reforzando:
- Calidad del movimiento
- Estética visual
- Fidelidad de audio
Inferencia Eficiente y Preparación para Implementación
A través de destilación multietapa, cuantización y optimizaciones de inferencia paralela:
- El número de evaluaciones de función (NFE) se reduce significativamente
- La inferencia de extremo a extremo logra aceleraciones de 10×+ mientras mantiene la calidad
Esta eficiencia es una razón clave por la que Seedance 1.5 Pro puede implementarse de forma confiable en WaveSpeedAI.
Casos de Uso Listos para Producción
Seedance 1.5 Pro es particularmente adecuado para:
- E-comercio transfronterizo y publicidad localizada
- Contenido narrativo corto y episódico
- Cómics en movimiento y animación expresiva
- Narrativa de marca y marketing cinemático
- Pre-visualización de películas y validación de conceptos
Reflexiones Finales
El valor de Seedance 1.5 Pro no es sobre probar que los modelos pueden generar sonido —es sobre establecer el escenario para que la coordinación audiovisual se convierta en un predeterminado confiable.
Para equipos que persiguen producción de contenido escalable, este enfoque unificado, construido desde cero, promete menos correcciones post-producción, mayor libertad creativa, y un flujo de trabajo de video generativo diseñado para resistir en entornos de producción reales.
Artículos relacionados

Seedance 2.0 Próximamente: El Modelo de Video de Próxima Generación de ByteDance con Audio Nativo

Guía Completa de Seedance 2.0: Creación de Vídeo Multimodal

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: La Comparación Definitiva de Generación de Video

Guía Completa de Seedream 5.0-Preview: Generación Inteligente de Imágenes

Revisión de Vidu Q3: Cómo se compara con Sora 2, Wan 2.6, Seedance 1.5, Veo 3.1 y Grok Imagine Video
