GLM-4.7-Flash vs GLM-4.7: ¿Cuál se adapta a tu proyecto?

Hola mis amigos. Soy Dora. Si esto suena familiar, no estás solo. He estado ahí: mirando una cola de pequeños y repetitivos prompts que solo necesitan una respuesta rápida y sólida—mientras que un par de tareas obstinadas de razonamiento multi-paso se sientan en la esquina, exigiendo silenciosamente mucha más potencia de cálculo.
Así que finalmente hice la pregunta en voz alta: ¿dónde brilla realmente el ligero y ultrarrápido GLM-4.7-Flash, y dónde necesitas traer el más pesado y deliberado GLM-4.7? Esta es la respuesta clara, sin exageraciones—fundamentada en ejecuciones reales, benchmarks cuando importan, y el objetivo tranquilo de hacer que tu stack diario se sienta notablemente más ligero. Si alguna vez te has pausado en “¿qué modelo debería usar aquí?”, esto es para ti.
Respuesta en 30 Segundos
Si la velocidad y el bajo costo son tus palancas principales, GLM-4.7-Flash probablemente se sienta correcto. Si tu trabajo se inclina hacia la profundidad del razonamiento, herramientas, o salidas de mayor fidelidad, GLM-4.7 es la opción más estable. El resto es matiz alrededor de presupuestos de latencia, tamaño del contexto, y cómo tus prompts se comportan bajo presión.
Elige Flash Si…
Flash no es “más débil”—es honesto sobre en qué es bueno.
- Estás despachando muchos trabajos pequeños: resúmenes, etiquetas, borradores, transformaciones rápidas.
- La latencia importa más que exprimir el último 10% de calidad.
- Estás experimentando, prototipando, o construyendo interacciones de UI que deberían sentirse instantáneas.
- Los ocasionales tambaleantes en pasos de razonamiento largo no te derribarán.
- Quieres un modelo predeterminado más barato y puedes escalar a GLM-4.7 solo cuando sea necesario.
Elige GLM-4.7 Si…
Este es tu modelo “no la arruines”.
- Te importa la confiabilidad del código, razonamiento multi-paso, o precisión en el uso de herramientas.
- Los prompts son largos, las instrucciones estrictas, o las salidas deben ser consistentes.
- Estás ejecutando evaluadores, pruebas, o flujos de trabajo donde un error es costoso.
- Necesitas resultados más sólidos en tareas de codificación y contexto largo.
- Puedes tolerar mayor costo y un poco más de latencia para mejores resultados.
Diferencias Arquitectónicas
 No persigo conteos de parámetros por deporte, pero la arquitectura explica mucho sobre el comportamiento: por qué un modelo se siente ágil y el otro se siente deliberado.
No persigo conteos de parámetros por deporte, pero la arquitectura explica mucho sobre el comportamiento: por qué un modelo se siente ágil y el otro se siente deliberado.
Conteo de Parámetros y Expertos Activos
GLM-4.7 parece ejecutar una columna vertebral más grande y (según notas públicas) utiliza enrutamiento de expertos que prioriza el razonamiento. Flash se ajusta para el rendimiento, enrutamiento más ligero, menos expertos activos por token, y configuraciones de eficiencia agresivas. En la práctica, eso tiende a mostrarse como:
- Flash: menor cálculo por token, tiempos rápidos de primer token, pero puede dejar caer cadenas de razonamiento bajo estrés.
- GLM-4.7: más cálculo por token, caminos de razonamiento más estables, mejores opciones de llamada de herramienta.
Si observas diagramas de proveedores, verás indicios de mezcla de expertos (MoE) y dispersión de activación. Los números exactos varían entre versiones, así que los trato como direccionales, no absolutos. La gran idea: Flash gasta menos “pensamiento” por token para que se mueva más rápido; GLM-4.7 piensa más y tropieza menos con casos límite.
Ventana de Contexto y Límite de Salida
Dos preguntas prácticas importan más que el número de contexto principal:
- ¿Hasta dónde en prompts largos se mantiene la calidad?
- Cuando las salidas se hacen largas, ¿pierde el hilo el modelo?
Flash generalmente anuncia una ventana de contexto saludable, pero la calidad tiende a disminuir antes con prompts muy largos o instrucciones densas. GLM-4.7 mantiene coherencia más profundamente en contextos largos y permanece más obediente a la estructura en salidas largas. Si estás empaquetando una base de conocimiento, GLM-4.7 es la opción predeterminada más segura. Si estás dividiendo entradas o usando recuperación para mantener los prompts delgados, Flash a menudo es suficiente—y mucho más rápido.
Comparación de Benchmarks
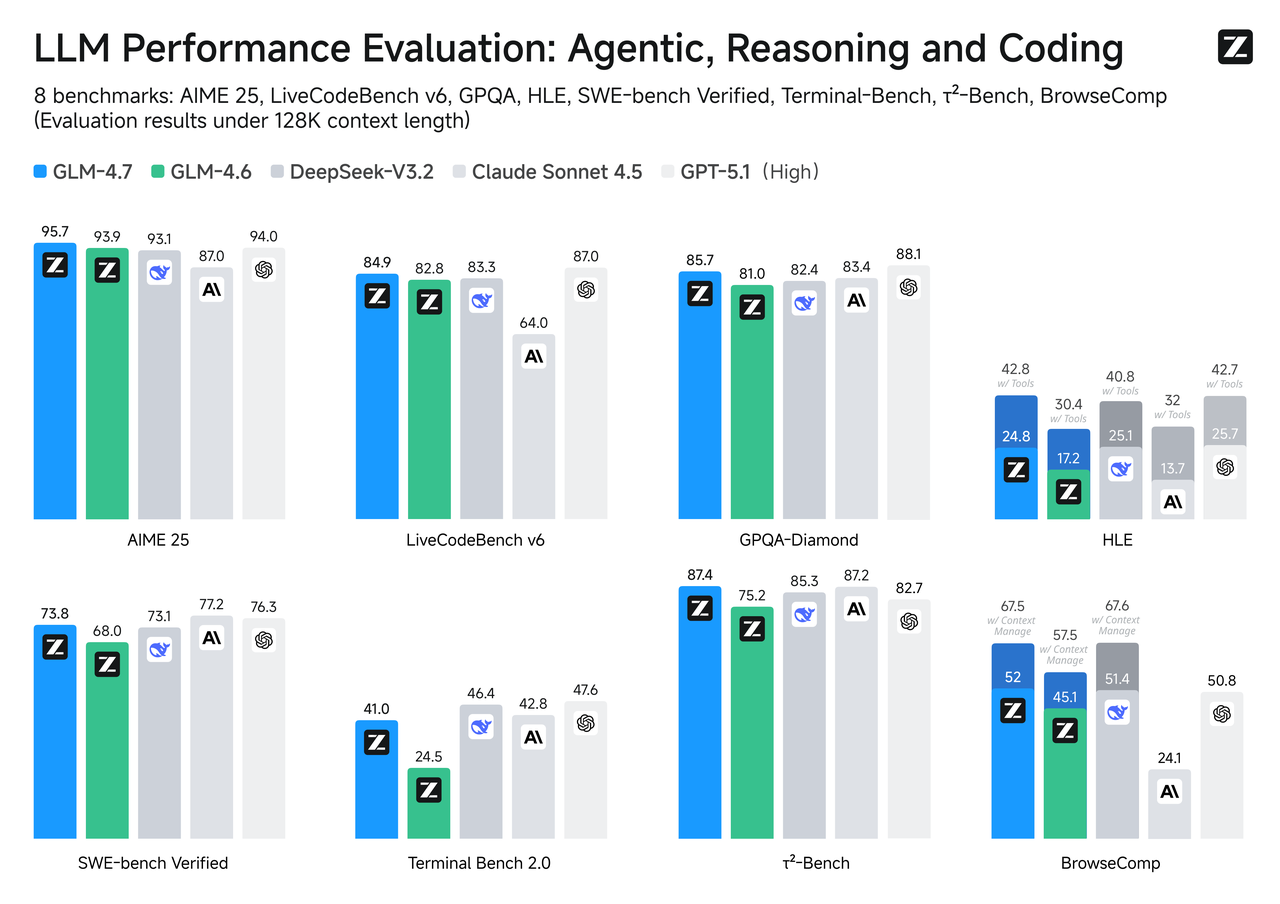 Los benchmarks no son toda la historia, pero son una brújula útil, especialmente cuando tu caso de uso se alinea con la tarea.
Los benchmarks no son toda la historia, pero son una brújula útil, especialmente cuando tu caso de uso se alinea con la tarea.
SWE-bench Verificado
Para cambios de código que deben compilar y pasar pruebas, GLM-4.7 tiende a ubicarse por encima de su hermano Flash. Eso coincide con lo que esperarías de un modelo ajustado para profundidad de razonamiento y uso de herramientas. Flash puede redactar correcciones y explicar código bien, pero cuando el parche necesita varios edits coordinados en archivos, GLM-4.7 es más probable que siga la cadena sin dejar pasos.
Si tu pipeline incluye auto-PR o bucles de reparación, vale la pena hacer una verificación de cordura con una pequeña muestra primero. La diferencia se muestra más en problemas multi-salto que en ajustes de archivo único.
LiveCodeBench / τ²-Bench
En benchmarks de codificación activos o que rotan en tiempo real, GLM-4.7 generalmente se mantiene más cerca del nivel superior dado su presupuesto de razonamiento más pesado. Flash, optimizado para velocidad, se sienta un nivel más bajo pero responde rápidamente. Si tu producto se basa más en la calidad de síntesis de código que en la velocidad de interacción, GLM-4.7 es la opción conservadora. Si el código es orientativo (lo revisarás de todos modos) y la responsividad importa, Flash puede ser el intercambio correcto.
Velocidad y Latencia
Aquí es donde la división se siente más clara. Flash a menudo devuelve el primer token notablemente más rápido, y el tiempo total hasta el último token se mantiene bajo para salidas cortas y medianas. Eso suma si estás ejecutando muchas llamadas pequeñas o transmitiendo a una UI.
GLM-4.7 comienza más lentamente y se ejecuta más pesadamente, pero es más estable en generaciones largas y secuencias complejas de llamada de herramienta. Verás menos bloqueos, menos desvíos extraños, y mejor adherencia a esquemas de función.
Si estás construyendo un sistema:
- Usa Flash para momentos UX de alto tráfico: autocompletado, resúmenes rápidos, ayuda en línea.
- Usa GLM-4.7 para el carril lento: evaluadores, acciones de código, verificaciones de política, pasadas finales.
Una regla de enrutamiento simple a menudo se paga por sí sola: comienza con Flash, escala a GLM-4.7 cuando la confianza baje o se crucen umbrales. Deja que las reglas decidan para que no tengas que hacerlo.
Desglose de Precios
Los precios cambian según la región y el proveedor, así que trato los números como objetivos móviles y mantengo la estructura estable.
Nivel Gratuito de Flash vs GLM-4.7 Pago por Token
-
Flash: Muchas plataformas exponen un nivel gratuito o de bajo costo para modelos tipo Flash, con límites de velocidad generosos en comparación con modelos insignia. Excelente para prototipos, tareas de fondo y pulido de UI.
-
GLM-4.7: Típicamente facturado por token a una tasa más alta. Mejor relación costo-valor en tareas serias, pero es fácil gastar demasiado si lo dejas como predeterminado.
 Consejos prácticos:
Consejos prácticos: -
Limita tokens de salida por defecto. Sube el límite solo en rutas que lo necesitan.
-
Usa recuperación para mantener los prompts cortos: no viertas todo el corpus en la ventana.
-
Cachea sub-resultados determinísticos (mapas regex, fragmentos de esquema, bloques few-shot) para que no pagues por ellos de nuevo.
-
Registra costos de token por ruta. El informe que realmente lees es el que se sienta en tu flujo de trabajo semanal, no el que tiene más gráficos.
En caso de duda, comienza barato, mide, luego escala. La escalada vence al optimismo.
Elige por Caso de Uso
Así es como los ubicaría cuando el objetivo es menos dolores de cabeza:
- Operaciones de contenido de alto cambio (fragmentos, líneas de asunto, metadatos): Flash. La ganancia es rendimiento y consistencia a bajo costo.
- Macros de soporte y triaje rápido: Flash primero, luego escala a GLM-4.7 si la detección señala complejidad o riesgo de política.
- Notas de investigación, síntesis, resúmenes estructurados: Flash para ojeadas; GLM-4.7 para la pasada que debe ser fiel a la fuente y bien andamiada.
- Asistencia de código: Flash para explicaciones y “¿qué hace esto?”; GLM-4.7 para edits multi-archivo, migraciones, y cambios conscientes de pruebas.
- Limpieza y transformación de datos: Flash es bueno para mapeo simple; GLM-4.7 para esquemas estrictos, validación, y uniones multi-paso.
- Agentes y uso de herramientas: GLM-4.7. Obtendrás argumentos de función más confiables y menos reintentos.
- Lectura de contexto largo o QA basada en documentos: GLM-4.7 si estás presionando la ventana; Flash si mantienes fragmentos delgados.
Algunas notas de campo que mantengo cercanas:
- Los prompts cortos esconden diferencias. La brecha se muestra cuando las instrucciones son densas o las salidas deben seguir una estructura.
- El enrutamiento ayuda. Incluso una regla simple, “Flash a menos que prompt > N tokens, entonces GLM-4.7”, ahorra dinero sin drama.
- Los guardarraíles importan más que la opción de modelo para tareas repetitivas. Validación, reintentos, y pequeños verificadores previenen desorden aguas abajo.
- No fetichices la velocidad. Menos de un segundo se siente “instantáneo” para la mayoría de usuarios. Pasado eso, el comportamiento estable vence a ahorrar 100 ms.
Por qué importa: las herramientas envejecen bien cuando reducen la carga mental. Flash mantiene el pequeño material ligero. GLM-4.7 lleva las cajas pesadas sin dejarlas caer. La mayoría de stacks necesitan ambos.
Si no estás seguro, comienza con Flash como tu predeterminado y crea un carril claro para GLM-4.7. Deja que las rutas, no los estados de ánimo, decidan. Tu experiencia puede variar, y eso está bien.
Todavía noto, en días tranquilos, cómo esta división reduce la fatiga de decisión. Nada vistoso—solo menos dolores de cabeza.
Cómo realmente ejecuto esta división en la práctica
 Cuando necesito enrutar trabajos rápidos a Flash y escalar los más pesados a GLM-4.7 sin cuidar scripts, uso WaveSpeed—nuestra propia plataforma.
Cuando necesito enrutar trabajos rápidos a Flash y escalar los más pesados a GLM-4.7 sin cuidar scripts, uso WaveSpeed—nuestra propia plataforma.
La construimos para manejar cambio de modelos, concurrencia, y llamadas de lote limpiamente, así que el patrón “Flash primero, escala cuando sea necesario” se mantiene simple en lugar de frágil.
Si estás ejecutando muchas llamadas pequeñas y no quieres que la lógica de enrutamiento se convierta en otra cosa que mantener, ¡prueba Wavespeed!
FAQ: GLM-4.7-Flash vs GLM-4.7
1. ¿Cuáles son las principales diferencias entre GLM-4.7-Flash y GLM-4.7?
GLM-4.7-Flash es una variante ligera y optimizada de GLM-4.7. Logra inferencia más rápida y menor costo al reducir el número de expertos activos, simplificar el enrutamiento, y aplicar ajustes de eficiencia. GLM-4.7 retiene una columna vertebral más grande y capacidades de razonamiento más fuertes, destacando en razonamiento multi-paso complejo, coherencia de contexto largo, y llamada precisa de herramientas.
En resumen: Flash negocia algo de inteligencia por velocidad; GLM-4.7 prioriza profundidad y confiabilidad.
2. ¿Cuál modelo es más rápido, y en qué escenarios es más notoria la diferencia de velocidad?
GLM-4.7-Flash tiene significativamente menor tiempo-hasta-primer-token (TTFT) y latencia por token. Brilla en casos de uso de alto rendimiento y baja latencia como interacciones UI en tiempo real, resumen de contenido, generación de metadatos, y prototipado rápido.
GLM-4.7 tiene mayor sobrecarga de inicio y cálculo más pesado pero permanece más estable para salidas largas o secuencias complejas de llamada de herramienta. En la práctica, Flash es notablemente más rápido para salidas cortas a medianas (menos de 500 tokens).
3. ¿Cuál modelo es más fuerte en inteligencia y razonamiento?
GLM-4.7 supera a Flash en razonamiento multi-paso, confiabilidad de código, uso de herramientas, y tareas de contexto largo. Ejemplos:
- SWE-bench Verificado: GLM-4.7 lidera en edición de código multi-archivo y parches coordinados.
- LiveCodeBench / τ²-Bench: GLM-4.7 entrega código de mayor calidad, especialmente para escenarios de razonamiento profundo.
Flash es adecuado para edits de archivo único o tareas asistidas que toleran revisión humana, pero se degrada más rápido en cadenas de razonamiento largo o prompts densos.
4. ¿Cómo se comparan la longitud del contexto y los límites de salida?
Ambos modelos comparten ventanas de contexto similares, pero GLM-4.7 mantiene mejor coherencia y seguimiento de instrucciones en contextos muy largos (>32k tokens) o prompts densos. Flash se degrada más rápidamente bajo longitud o densidad extrema de prompt—emparéjalo con división o RAG para mejores resultados.
5. ¿Cómo debería elegir basándome en precios y control de costos?
GLM-4.7-Flash típicamente ofrece cuotas gratuitas más altas y precios por token más bajos (o incluso cero), haciéndolo ideal para prototipos, tareas de fondo, y llamadas de alto volumen bajo riesgo. GLM-4.7 tiene costos por token más altos pero mejor valor para tareas críticas.
Recomendación: por defecto usa Flash, escala a GLM-4.7 para trabajo complejo, y siempre establece límites de token y cacheo para prevenir gasto excesivo.
Artículos relacionados

Seedance 2.0 Próximamente: El Modelo de Video de Próxima Generación de ByteDance con Audio Nativo

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: La Comparación Definitiva de Generación de Video

Guía Completa de Seedance 2.0: Creación de Vídeo Multimodal

Guía Completa de Seedream 5.0-Preview: Generación Inteligente de Imágenes

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Comparación Completa
