GLM-4.7-Flash: Fecha de lanzamiento, nivel gratuito y características clave (2026)

Oye, soy Dora.
Recientemente, GLM-4.7-Flash seguía apareciendo en conversaciones de gente en la que confío, generalmente mencionado con un pequeño encogimiento de hombros: “lo suficientemente rápido para no meterse en el camino.” Esa frase se quedó conmigo. No estoy buscando modelos brillantes en este momento: estoy buscando herramientas que hagan que el trabajo diario se sienta más ligero. ¿Me entiendes?
Así que le di a GLM-4.7-Flash unos días en mi stack (20-21 de enero de 2026). Prompts cortos, pequeños scripts de API, un par de trabajos por lotes. Nada dramático. La pregunta que mantuve fue simple: ¿es esto una adición práctica, o simplemente otro nombre de modelo pasando por el timeline?
¿Qué es GLM-4.7-Flash?
GLM-4.7-Flash es una variante enfocada en velocidad de la familia GLM-4.7 de Zhipu AI. Piénsalo como el modelo al que recurres cuando quieres generaciones responsivas y de baja latencia sin la sobrecarga del razonamiento pesado. No intenta ganar benchmarks de formato largo ni debatir filosofía: busca devolver respuestas decentes rápidamente y a bajo costo.
Quién lo hizo (Zhipu AI / Z.ai)
 Zhipu AI (también conocido como Z.ai) es el equipo detrás de la serie GLM. Si has probado modelos GLM anteriores, la nomenclatura te resultará familiar: el número refleja la generación, y el sufijo (Flash, Standard, etc.) sugiere los compromisos. Su documentación es directa y se actualiza regularmente: si estás integrando, agrega un marcador a la documentación oficial de API en el portal de desarrolladores de Zhipu.
Zhipu AI (también conocido como Z.ai) es el equipo detrás de la serie GLM. Si has probado modelos GLM anteriores, la nomenclatura te resultará familiar: el número refleja la generación, y el sufijo (Flash, Standard, etc.) sugiere los compromisos. Su documentación es directa y se actualiza regularmente: si estás integrando, agrega un marcador a la documentación oficial de API en el portal de desarrolladores de Zhipu.
He usado modelos de Zhipu de vez en cuando durante el último año cuando necesitaba cobertura multilingüe y salidas estables y predecibles. GLM-4.7-Flash continúa ese patrón, solo con más énfasis en velocidad y rendimiento.
Flash vs Standard, Posicionamiento
Así es como sentí las diferencias en la práctica:
- Flash: optimizado para velocidad, menor cómputo por solicitud, excelente para endpoints de alto volumen, asistentes de UI y clasificación o etiquetado por lotes. Noté que era más feliz con prompts concisos y estructura clara.
- Standard (sin Flash): más lento pero más estable en tareas que requieren razonamiento. Si le lanzaba análisis multietapa a Flash, lo intentaba, pero podía ver que comprimía pasos para mantener la latencia baja.
Si estás eligiendo entre ellos, una regla suave: si la latencia y el costo determinan tu día a día, comienza con Flash. Si la corrección en razonamiento de múltiples pasos es tu restricción principal, Standard (o un hermano sintonizado para razonamiento más grande) probablemente funcionará mejor. Ya sabes, elige tu luchador.
Lanzamiento oficial: 19 de enero de 2026
Zhipu AI anunció GLM-4.7-Flash el 19 de enero de 2026. Comencé a probar al día siguiente. El contexto de versión importa con estos modelos: los primeros días a menudo vienen con iteración rápida. Si estás leyendo esto más tarde, verifica las notas de lanzamiento en la documentación oficial para confirmar cualquier cambio en los límites o comportamiento.
Arquitectura de un vistazo
No necesito conocer los detalles internos de un modelo para usarlo, pero ciertos detalles me ayudan a estimar costos y dónde sobresaldrá.
30B MoE, 3B Parámetros Activos
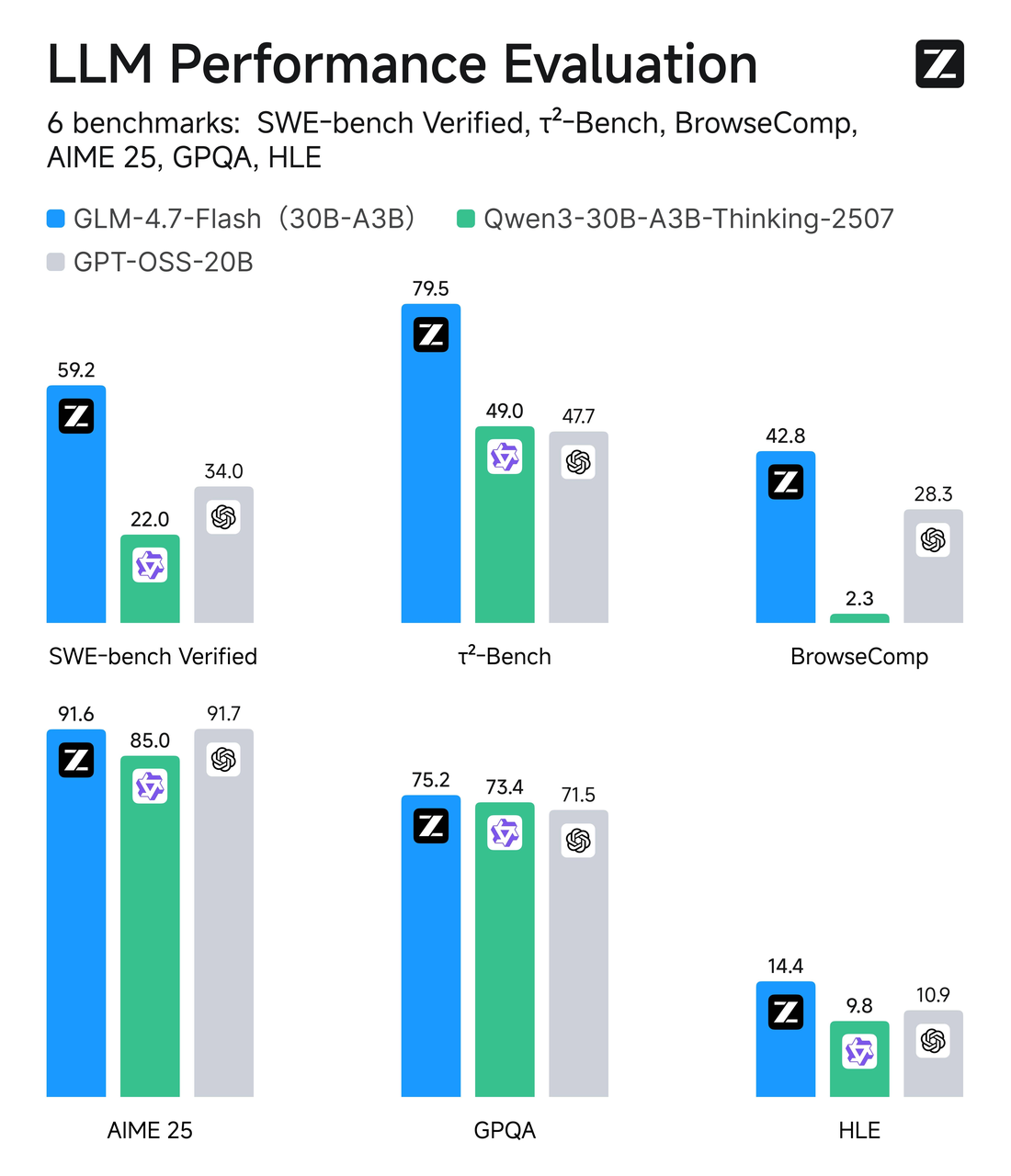 GLM-4.7-Flash utiliza un diseño de Mixture-of-Experts (MoE) con un número total de parámetros alrededor de 30B, pero solo ~3B expertos están activos por token. En términos simples: es un modelo amplio con enrutamiento selectivo. La mayoría del tiempo, solo una pequeña parte de la red funciona en tu token, lo que mantiene la inferencia ágil.
GLM-4.7-Flash utiliza un diseño de Mixture-of-Experts (MoE) con un número total de parámetros alrededor de 30B, pero solo ~3B expertos están activos por token. En términos simples: es un modelo amplio con enrutamiento selectivo. La mayoría del tiempo, solo una pequeña parte de la red funciona en tu token, lo que mantiene la inferencia ágil.
En la práctica, MoE a menudo te da una sensación de “cerebro más grande cuando sea necesario” sin siempre pagar el precio total de cómputo. Durante mis pruebas, eso se tradujo en salidas responsivas incluso bajo carga, y latencia más consistente que los modelos densos de escala similar reportada. No es magia, solo una forma inteligente de equilibrar capacidad y velocidad.
MLA (Atención de Latencia Múltiple)
Los documentos mencionan MLA (Multi-Headed Latent Attention). Mi conclusión como usuario: es una estrategia de atención dirigida a ser más eficiente que la autoatención clásica completa, especialmente bajo contextos más largos. No empujé los límites de contexto largo aquí: mis ejecuciones fueron principalmente bajo algunos miles de tokens. Aún así, el consumo de memoria se mantuvo razonable, y no vi el usual deslizamiento lento de latencia conforme los prompts crecieron de “corto” a “medio”.
Si estás planeando flujos de trabajo retrieval-heavy o bucles de agentes, MLA más MoE es una señal útil: este modelo está diseñado para mantener el rendimiento elevado en lugar de perseguir la máxima profundidad de razonamiento de una sola pasada.
API Gratuita — Qué está incluido
El acceso gratuito se destacó. Soy cuidadoso aquí porque los niveles gratuitos cambian, a veces semanalmente. Lo que comparto es lo que observé el 20-21 de enero de 2026, y lo que los documentos de Zhipu sugirieron en el lanzamiento. Siempre verifica los límites antes de incorporar esto en producción.
 En resumen: la API gratuita me permitió hacer solicitudes reales con valores por defecto sensatos. Ejecuté trabajos pequeños sin golpear un muro de pago a mitad de la prueba. Eso redujo la fricción para probarla en un script en vivo en lugar de desde un playground.
En resumen: la API gratuita me permitió hacer solicitudes reales con valores por defecto sensatos. Ejecuté trabajos pequeños sin golpear un muro de pago a mitad de la prueba. Eso redujo la fricción para probarla en un script en vivo en lugar de desde un playground.
Límites de tasa y concurrencia
Lo que vi:
- Concurrencia: Podría ejecutar cómodamente múltiples solicitudes paralelas desde un pequeño trabajador sin activar errores. En mis pruebas, 5-10 llamadas concurrentes se mantuvieron estables. Cuando pasé más alto, comencé a ver limitación, lo cual es esperado en un nivel gratuito.
- Rendimiento: Prompts cortos (clasificación, pequeñas transformaciones) devolvieron en rango de subsegundo a bajo-segundos. En promedio, vi 300-900 ms para respuestas muy cortas y 1.5-3 s para salidas modestas. La varianza de red aplica.
- Seguridad: La API respondió con códigos de error claros cuando excedí límites. Solo eso me ahorró tiempo, no tuve que adivinar qué salió mal.
No perseguí límites exactos de TPS: mi objetivo era ver si pequeños pipelines podrían ejecutarse sin cuidado. Lo hicieron. Se siente como libertad, honestamente. Si estás planeando cargas de trabajo picos, prueba con concurrencia realista y construye reintentos/retroceso simples. Los niveles gratuitos son generosos hasta que no lo son.
Nivel de pago FlashX
Zhipu menciona una opción de pago “FlashX” dirigida a mayor rendimiento y un rendimiento más predecible. No moví mis pruebas a FlashX durante esta ejecución, pero aquí está lo que típicamente cambia cuando subes de nivel con proveedores como este:
- Límites de tasa más altos y garantizados con menos limitación.
- Más solicitudes concurrentes por clave, útil para trabajos por lotes y asistentes orientados al usuario.
- Enrutamiento prioritario (latencia de cola más baja). Esto importa cuando te importa el peor 5% de solicitudes, no solo la mediana.
Si estás lanzando una característica orientada al cliente, FlashX es la ruta más segura. Si estás experimentando, el nivel gratuito es lo suficientemente bueno para sentir la estabilidad y el trabajo de integración. Tu experiencia dependerá de tu presupuesto de latencia y con qué frecuencia hagas lotes.
Mejores casos de uso
Intenté un puñado de tareas reales. Nada glamoroso, solo lo que aparece en mi semana.
- Asistentes de interfaz donde el retraso mata el ambiente. Piensa: reescrituras en línea, pequeñas aclaraciones, pequeños seguimientos. GLM-4.7-Flash mantuvo la interfaz sintiéndose inmediata.
- Transformaciones de texto por lotes. Ejecuté un pequeño CSV (un par de miles de filas) para ajustes de tono y etiquetas de categoría. El modelo se mantuvo consistente y no derivó a mitad de camino.
- Scaffolds de borrador. Esquemas, expansiones punto a punto, breves simples. Manejó bien la estructura cuando le di instrucciones claras. Como tener un mini-ayudante al que no tienes que sobornar.
- Resúmenes de recuperación con ventanas de contexto cortas. Cuando pasé 2-4 fragmentos, respondió limpiamente sin alucinar puentes raros. Con contexto largo y desordenado, intentó ser útil pero a veces comprimía demasiado agresivamente.
- “Primer paso” comentarios de código o docstrings. No refactores profundos. Solo aclarar intención y nombres, rápido y útil.
Dónde no lo usaría:
- Análisis multietapa con casos límite donde la precisión importa más que la velocidad. Recurriría a un modelo de razonamiento más pesado.
- Generación de formato largo donde necesitas tono constante y unión de hechos profunda durante miles de tokens. Flash puede hacerlo, pero se siente fuera de lugar.
Por qué esto importa: modelos rápidos que no destruyen tu presupuesto abren características que de otro modo cortarías. Si tu producto necesita docenas de pequeñas llamadas de modelo por sesión, la latencia reducida y el cómputo más bajo por llamada se suman. Pequeñas ganancias, gran recompensa.
💡 Para hacer que ejecutar modelos como GLM-4.7-Flash sea más fácil y confiable en flujos de trabajo reales, uso WaveSpeed — nuestra propia plataforma que maneja solicitudes de API, concurrencia y trabajos por lotes sin problemas, para que puedas enfocarte en resultados en lugar de cuidar scripts.
Prueba WaveSpeed →
 Una pequeña nota de las trincheras: mi primera hora no fue más rápida. Jugué con estructura de prompt, temperatura y max tokens. Después de algunas ejecuciones, encontré un patrón, prompt del sistema corto, formato de salida explícito, restricciones claras. Eso redujo tanto el tiempo como el esfuerzo mental. No fue magia: fue configuración.
Una pequeña nota de las trincheras: mi primera hora no fue más rápida. Jugué con estructura de prompt, temperatura y max tokens. Después de algunas ejecuciones, encontré un patrón, prompt del sistema corto, formato de salida explícito, restricciones claras. Eso redujo tanto el tiempo como el esfuerzo mental. No fue magia: fue configuración.
¿Quién más comenzó una prueba “rápida de 10 minutos” de GLM-4.7-Flash (o cualquier modelo Flash) y parpadeó para encontrar el reloj diciendo medianoche? Deja tu récord personal — y el cambio de un prompt que finalmente lo hizo comportarse — en los comentarios.
Artículos relacionados

Seedance 2.0 Próximamente: El Modelo de Video de Próxima Generación de ByteDance con Audio Nativo

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: La Comparación Definitiva de Generación de Video

Guía Completa de Seedance 2.0: Creación de Vídeo Multimodal

Guía Completa de Seedream 5.0-Preview: Generación Inteligente de Imágenes

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Comparación Completa
