Crea un Presentador de IA en 5 Minutos: Una Guía para Principiantes sobre Humanos Digitales

Un tutorial paso a paso para construir un humano digital en WaveSpeedAI.
Prólogo
No todos nacen oradores naturales, y no todos se sienten cómodos hablando frente a una multitud.
Ponerse de pie para hablar puede ser angustioso, pero ¿y si un “tú virtual” pudiera hacer la presentación, transmitir en directo o grabar tu promoción por ti? ¿Seguirías teniendo miedo?
¡En WaveSpeedAI, eso ya no es solo una idea! Puedes construir tu propio humano digital desde cero y hacer que hable tus palabras con voz realista y expresiones naturales.
No sufre pánico escénico, nunca se cansa, y puedes refinarlo y reutilizarlo todas las veces que quieras. Es tu socio confiable en el trabajo y en la vida.
En este tutorial, te guiaremos de cero a uno mientras construyes un humano digital simple paso a paso. Los modelos que usamos aquí son solo el comienzo: siéntete libre de explorar más capacidades y estilos para hacer que tu humano digital sea realmente único.
En WaveSpeedAI, nuestros modelos producen visuales claros y estables con bordes naturales y están listos para ser mostrados. Funcionan bien para segmentos de cabeza parlante formales, conversaciones casuales y explicadores de productos por igual.
Generación de Imagen
Un humano digital atractivo, adorable y de aspecto natural proporciona a los espectadores una mejor experiencia. También atraerá más atención y tráfico a tu canal.
También puedes crear uno directamente desde una foto personal. Si ya tienes una foto adecuada lista, siéntete libre de omitir esta parte.
Usaré bytedance/seedream-v4 como ejemplo para ayudarte a crear un avatar virtual que sea únicamente tuyo.
En WaveSpeedAI, busca bytedance/seedream-v4: es un modelo de texto a imagen. Ahora, introduzcamos un prompt para crear tu propio humano digital:
Half-length portrait of a young female digital human (22–28),
natural makeup, white shirt and light gray blazer,
looking at camera, soft studio light,
plain light-gray background, ultra realistic, 4k, 85mm, f/2.8
Puedes personalizar elementos como género, atuendo y fondo para adaptarse a tus necesidades, creando varios estilos y ambientes para que tu humano digital se sienta más atractivo y acorde con tu marca.
Generación de Voz
Ahora que tu humano digital está listo, el siguiente paso es redactar un guion de voz en off claro para que puedan “hablar” de manera natural.
En WaveSpeedAI, ve a Categoría > Texto a Audio para explorar varios modelos. Ofrecemos modelos para voces en off naturales, clonación de voz e incluso composición de canciones.
En esta sección, usaremos minimax/speech-02-hd como nuestro ejemplo. Siéntete libre de probar otros modelos para explorar diferentes estilos y efectos vocales.
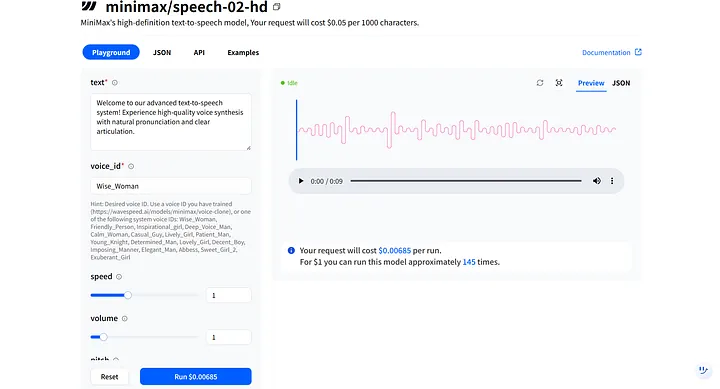
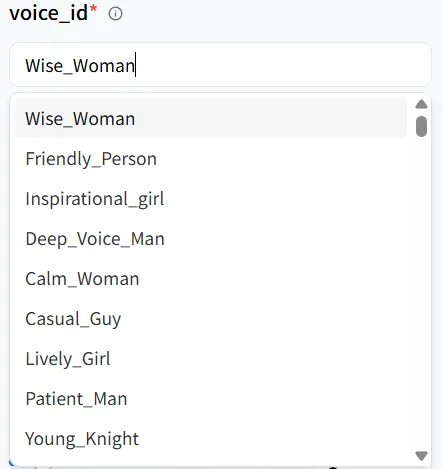
En el Playground del modelo, verás parámetros clave como text y voice_id. Estos funcionan juntos para dar forma al tono y timbre de tu humano digital, y puedes ajustarlos para diferentes escenarios. Por ejemplo, el humano digital que creé es femenino, así que puedo seleccionar la primera opción de voz, Wise_Woman.
Parámetros Clave
Velocidad
speed controla qué tan rápido habla tu humano digital. Elige un ritmo que se adapte a la escena; por ejemplo, ralentiza un poco para introducciones de productos y acelera para conversaciones casuales. Un valor de 1 indica velocidad normal.

Volumen
volume establece la loudness. Si tu humano digital está narrando una historia para dormir, puedes reducir speed para ralentizar las cosas y disminuir el volume para una entrega más suave. Un valor de 1 es el volumen por defecto.
Tono
pitch ajusta el tono de la voz. Ajusta esto para que la voz suene más brillante y aguda, o más profunda y completa. Un valor de 0 es el tono por defecto.

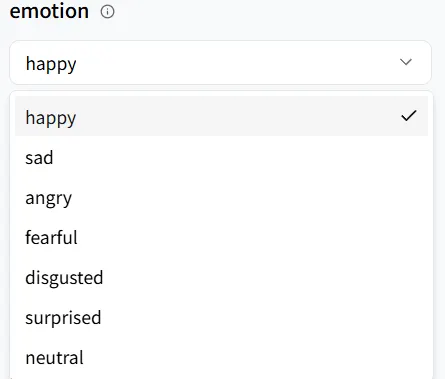
Emoción
emotion controla el estilo de habla de tu humano digital. Elige un tono que coincida con la escena; aquí, seleccionaremos happy.
Normalización de Inglés
La opción english_normalization, cuando está habilitada, hace que los números y símbolos en inglés suenen naturales en el habla. Sin ella, el sistema podría leer dígitos uno por uno (por ejemplo, “uno dos tres” para “123”) en lugar de “ciento veintitrés”.

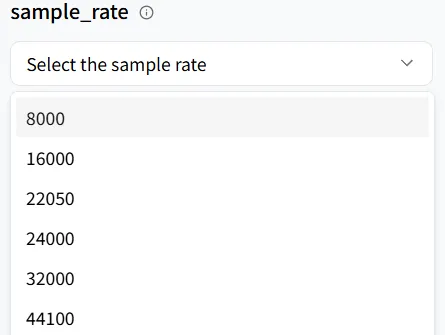
Frecuencia de Muestreo
sample_rate determina la calidad del audio (resolución). Si estás produciendo contenido de estilo ASMR, apunta a una frecuencia de muestreo más alta para mayor detalle. Para este ejemplo del tutorial, no es crítico: mantener el valor por defecto está perfectamente bien.
Tasa de Bits
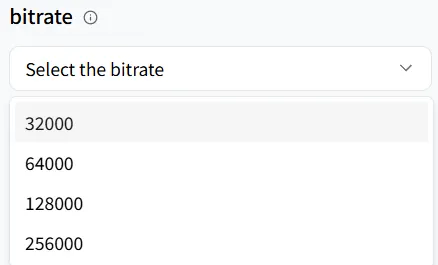
bitrate determina tanto la calidad como el tamaño de tu archivo de audio. Representa el número de bits procesados por segundo. Una tasa de bits más baja crea un archivo más pequeño pero puede perder detalle; una tasa de bits más alta resulta en un archivo más grande con un sonido más claro.
Canal
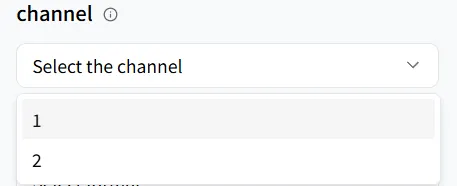
El parámetro channel determina el número de canales de audio generados.
- channel = 1 (mono): Todo el sonido se mezcla en un solo canal; ideal para voz de teléfono, grabaciones de llamadas o contenido enfocado en diálogos donde el ancho espacial no es necesario.
- channel = 2 (estéreo): El sonido se divide en canales izquierdo y derecho, creando ancho y una sensación de espacio para una experiencia más inmersiva y en capas; perfecto para música, películas, juegos y voces en off de video que requieren mayor calidad de escucha.
Formato
format te permite seleccionar el tipo de archivo de audio de salida (aquí omitiremos los detalles específicos).
Impulso de Idioma
language_boost mejora la comprensión del modelo sobre tu idioma seleccionado. Para este tutorial, elige English.
Generar Audio
A continuación, pega tu guion y haz clic en Run para generar el audio.
Welcome to WaveSpeedAI’s Digital Human Tutorial. We’ll spark fresh ideas in AIGC and show you practical steps. Let’s unleash your creativity together!
Descarga el archivo de audio: ¡esta es la pieza crucial que permitirá que tu humano digital hable más adelante!
Hacer que el Humano Digital Hable
Finalmente, el momento emocionante: ¡vamos a hacer que tu humano digital realmente hable!
En WaveSpeedAI, busca wavespeed-ai/infinitetalk: nuestro modelo de alta calidad diseñado específicamente para voces en off de humanos digitales.
En el Playground del modelo, verás dos entradas requeridas: audio e image.
- audio: Carga el archivo de voz en off que acabas de descargar.
- image: Carga la imagen del humano digital que generaste anteriormente.
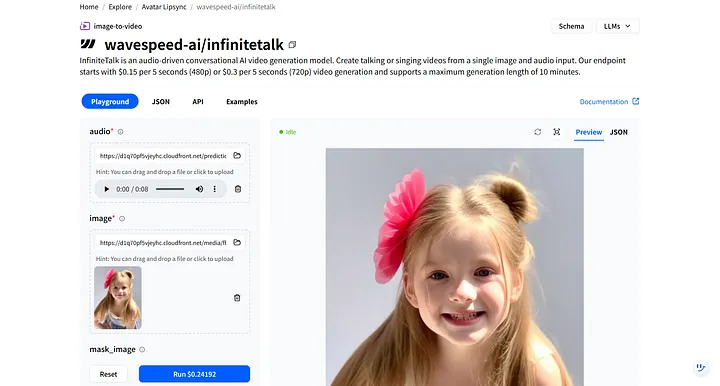
Después de hacer clic en Run, el humano digital responde al audio y sincroniza automáticamente los movimientos de los labios y las expresiones faciales.
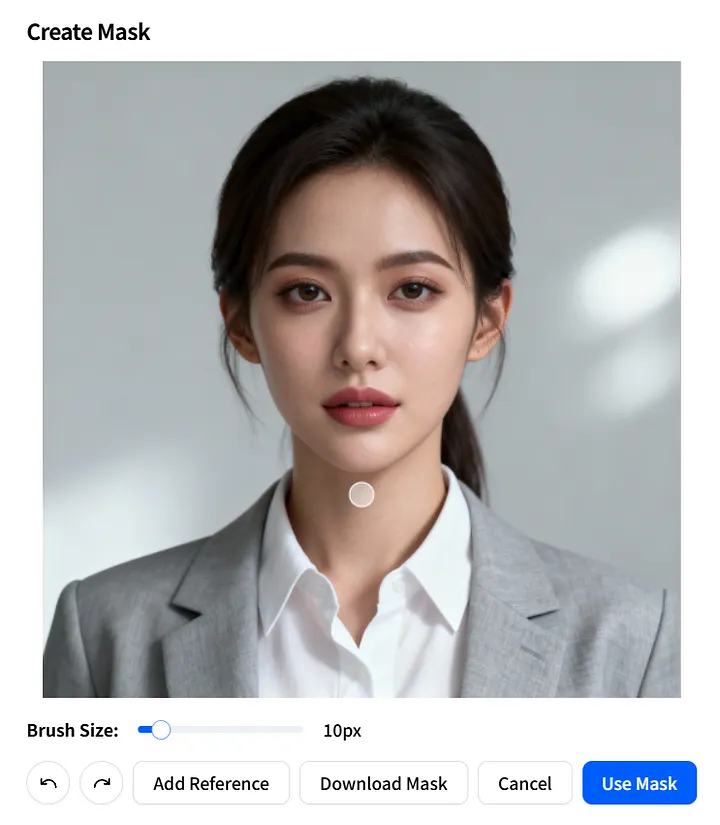
Parámetro de Imagen de Máscara
A continuación, veamos el parámetro mask_image. Te permite especificar exactamente qué partes de la imagen deben ser animadas.
En la página Create Mask, define con precisión el área móvil: ajusta el Brush Size, pinta sobre las regiones que deseas animar, luego haz clic en Use Mask para aplicar.
También puedes hacer clic en Download Mask para guardar la mask_image como plantilla para reutilización rápida en proyectos futuros.
Personalización Adicional
Si tienes necesidades adicionales, como especificar una pose, gestos con las manos o dirección de la mirada, añade instrucciones más específicas en el prompt.
Para una replicación fácil, establece un valor seed fijo. Esto asegura que la aleatoriedad sea consistente para que puedas reproducir los mismos resultados más adelante.
Finalmente, haz clic en Run y ¡miremos hacia adelante el resultado final!
¡Felicidades! ¡Tienes tu propio humano digital!
¿Listo para avanzar a escenas de múltiples personas? WaveSpeedAI también proporciona modelos dedicados para eso. ¡Explorémoslos juntos!
Generación de Múltiples Hablantes
En WaveSpeedAI, busca wavespeed-ai/infinitetalk/multi. Sus pasos son básicamente los mismos que el modelo de una sola persona.
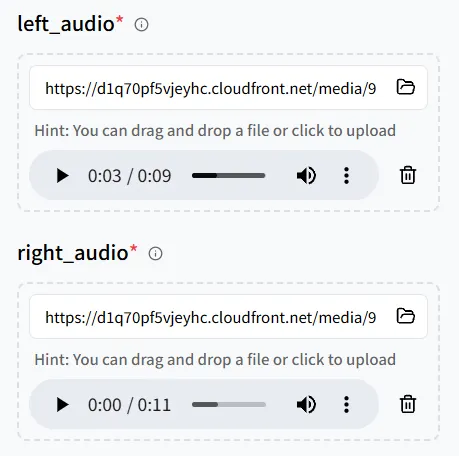
Esta vez, añade dos archivos de audio, luego carga una imagen con dos humanos digitales para que ambos personajes puedan decir sus líneas.
Presta mucha atención al emparejamiento entre el audio y las posiciones en la imagen:
- left_audio → la persona en el lado izquierdo en la imagen
- right_audio → la persona en el lado derecho en la imagen
Revisa el mapeo cuidadosamente; de lo contrario, las voces podrían estar vinculadas a los personajes equivocados.
Modos de Habla
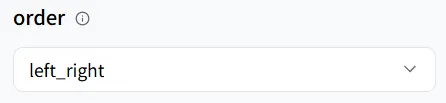
En el modelo wavespeed-ai/infinitetalk/multi, admite tres modos de habla:
- left_right (izquierda a derecha)
- right_left (derecha a izquierda)
- meanwhile (habla simultánea)
De manera similar, con este modelo, puedes añadir los detalles que desees a través del prompt y establecer un seed para fácil reproducibilidad.
¡Y así, tienes un show de voz en off para dos personas!
Otros Modelos
En WaveSpeedAI, también te proporcionamos muchos modelos adicionales:
- wavespeed-ai/multitalk: Perfecto para “humanos digitales de estilo canción”, permitiendo vocales multiparte y actuaciones más expresivas.
- wavespeed-ai/infinitetalk/video-to-video: Añade voz en off o narración a videos existentes para que los visuales y el audio se mantengan naturalmente sincronizados.
- wavespeed-ai/song-generation: Crea música desde cero para diseñar una banda sonora personalizada y una atmósfera para tu contenido.
Estos modelos también ofrecen experiencias únicas que son difíciles de replicar en otras plataformas. Sé atrevido: ¡pruébalos y comparte tu trabajo! ¡Puedes publicar en la sección de Inspiration para conectar e interactuar con otros creadores!

Reflexiones Finales
Nuestro mundo está cambiando rápidamente, y la IA está influyendo cada vez más en nuestras vidas diarias. Adherirse a métodos antiguos solo aumenta los costos, ralentiza el progreso y arriesga perder nuevas oportunidades.
Ahora es el momento perfecto para adoptar nueva tecnología y disfrutar de la conveniencia y eficiencia que ofrece. WaveSpeedAI proporciona soporte a largo plazo para tu creación de contenido con tecnología confiable y un ecosistema en constante crecimiento.
Dondequiera que tu creatividad te lleve, WaveSpeedAI estará allí como tu base confiable y socio de confianza.
Artículos relacionados

Seedance 2.0 Próximamente: El Modelo de Video de Próxima Generación de ByteDance con Audio Nativo

Guía Completa de Seedance 2.0: Creación de Vídeo Multimodal

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Comparación Completa

Guía Completa de Seedream 5.0-Preview: Generación Inteligente de Imágenes

Revisión de Vidu Q3: Cómo se compara con Sora 2, Wan 2.6, Seedance 1.5, Veo 3.1 y Grok Imagine Video
