Descargar modelo LTX-2: archivos de Hugging Face, tamaños y estructura de carpetas

I’ll translate this article to Spanish now.
La primera vez que fui en busca de una descarga de LTX-2, no fue un gran plan. Solo quería ejecutar un pequeño lote a través de ComfyUI y seguía tropezando con las mismas dos fricciones: descargas lentas que se estancaban en el 92%, y un mensaje críptico “Model not found” una vez que finalmente tenía los archivos. Nada dramático. Solo el tipo de problema repetido que te impulsa a detenerte y ordenar el flujo de trabajo.
Pasé algunos anocheceres a principios de enero de 2026 probando diferentes fuentes, formatos (NVFP4 vs NVFP8), y disposiciones de carpetas en una caja de GPU de 24GB. Nada llamativo, solo suficientes ejecuciones para ver qué era sólido versus frágil. Aquí está el camino que redujo el desorden para mí, con notas que puedes revisar y tomar prestadas.
Fuentes Oficiales de Descarga de LTX-2 (Tarjeta de Modelo de Hugging Face)
 No persigo espejos. Si un modelo importa para mi flujo de trabajo, quiero que el rastro sea aburrido y confiable. Para LTX-2, eso significa comenzar en la tarjeta de modelo oficial de Hugging Face.
No persigo espejos. Si un modelo importa para mi flujo de trabajo, quiero que el rastro sea aburrido y confiable. Para LTX-2, eso significa comenzar en la tarjeta de modelo oficial de Hugging Face.
Lo que busco antes de hacer clic en descargar:
- Publicador: ¿Es la organización verificada o el autor vinculado a LTX-2? Verifico el distintivo de la organización y que otros repositorios en el espacio de nombres se vean vivos y consistentes.
- Licencia y términos: Algunas variantes de LTX-2 están bloqueadas o tienen límites de uso. Si aceptar términos requiere un token, prefiero hacerlo una vez que depurar errores de autenticación más tarde.
- Lista de artefactos: Examino el modelo principal, cualquier codificador, y una variante destilada o cuantificada. Los nombres de archivo claros superan a los ingeniosos.
- Instrucciones: Si la tarjeta enlaza a ComfyUI o documentos específicos de nodos, sigo esos primero. Una línea sobre carpetas esperadas puede ahorrar media hora de adivinanzas.
Consejo práctico: utiliza la CLI de Hugging Face con credenciales configuradas. Un repositorio bloqueado no se descargará sobre git-lfs sin token, y esa es la forma más rápida de terminar con archivos parciales y sin error hasta que intentes cargarlos.
pip install huggingface_hub git-lfs
huggingface-cli login # pega tu tokenLo sé, obvio. Pero la cantidad de veces que he visto un 403 silencioso convertirse en “model not found” más adelante es… no cero.
Lista de Archivos y Tamaños (modelo principal / codificador / destilado)
No memorizo tamaños de archivos. Solo necesito un aproximado para planificar disco y decidir qué variante descargar primero. Aquí está lo que realmente he visto en caídas recientes de LTX-2. Tu repositorio puede diferir, siempre confía en la tarjeta del modelo sobre mis notas.
Artefactos típicos que verás:
- Punto de control del modelo principal (a menudo
.safetensorso un formato específico del tiempo de ejecución): ~2.5–6.0 GB. Más grande si incluye cabezas adicionales o precisión múltiple; más pequeño si está cuantificado. - Codificador de texto/imagen (CLIP o similar): ~400 MB–1.5 GB. Algunas compilaciones incluyen esto; otras lo envían como un archivo separado.
- VAE o adaptador latente (si aplica): ~100–500 MB.
- Variante destilada: ~1–3 GB. Más rápido y más ligero, a veces con salidas ligeramente más suaves. Bueno para prototipado.
- Variantes cuantificadas (NVFP8/NVFP4): el tamaño varía, pero espera 30–60% menos disco que precisión completa.
Patrones de nombres que observo:
ltx-2.safetensors(principal)ltx-2-encoder.safetensorsoopen_clip-vit-…(codificador)ltx-2-vae.safetensors(si está separado)ltx-2-distilled-…(más pequeño, más rápido)ltx-2-nvfp8/ltx-2-nvfp4(específico del formato)
Si el disco es limitado, descargo primero la destilada, valido mi canalización, luego descargo el modelo completo. No se trata solo de velocidad: reducir la carga cognitiva de la primera ejecución me ayuda a probar indicaciones y nodos sin luchar con VRAM inmediatamente.
Estructura de Carpetas de ComfyUI para LTX-2 (Rutas Exactas)
Aquí es donde tropecé el primer día: mis archivos estaban bien, pero ComfyUI no sabía dónde buscar. Los diferentes nodos personalizados esperan ubicaciones ligeramente diferentes, pero los valores predeterminados a continuación han sido seguros para mí.
En una instalación estándar de ComfyUI (sin anulaciones de nodos personalizados):
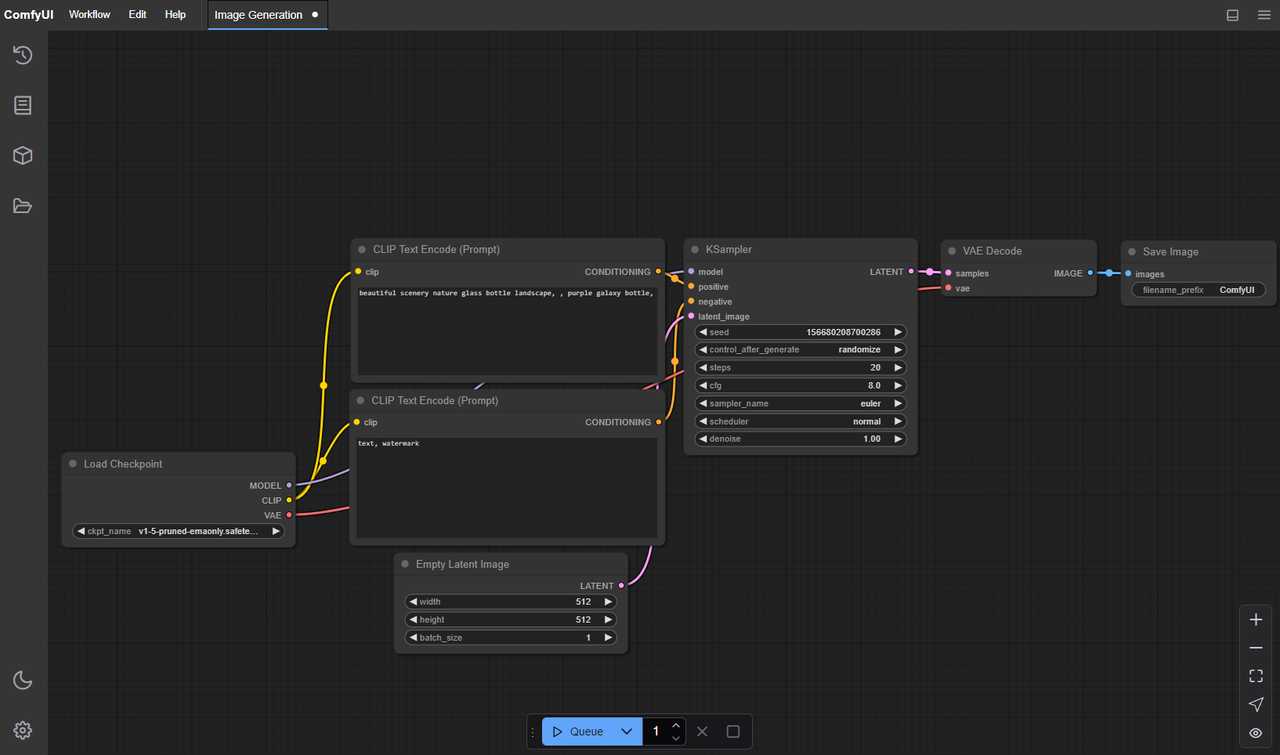
- Punto de control del modelo principal:
ComfyUI/models/checkpoints/LTX-2.safetensors - Codificador de texto/imagen (CLIP o similar):
ComfyUI/models/clip/LTX-2-encoder.safetensors- Algunas compilaciones usan nomenclatura open_clip: coloca esas en
models/clip/también.
- Algunas compilaciones usan nomenclatura open_clip: coloca esas en
- VAE (si está separado):
ComfyUI/models/vae/LTX-2-vae.safetensors - LoRA/parches (si los usas):
ComfyUI/models/loras/
Si estás usando nodos que dependen de archivos TensorRT o engine:
ComfyUI/models/trt/ltx-2/*.engineComfyUI/models/unet/ltx-2/*.engine
Dos hábitos aburridos pero útiles:
- Haz coincidir los nombres de archivo exactamente con lo que tu nodo espera. Mantengo los nombres cortos y elimino espacios.
- Después de mover archivos, usa la actualización del modelo de ComfyUI o reinicia. La recarga en caliente funciona a veces: un reinicio completo es más consistente.
Si usas un disco externo o una carpeta de modelos compartida, configura ComfyUI’s Extra Model Paths para que no busque silenciosamente en la unidad incorrecta. La sensibilidad a mayúsculas en Linux me ha afectado más de una vez.
Pesos NVFP4 vs NVFP8: Cuál Descargar
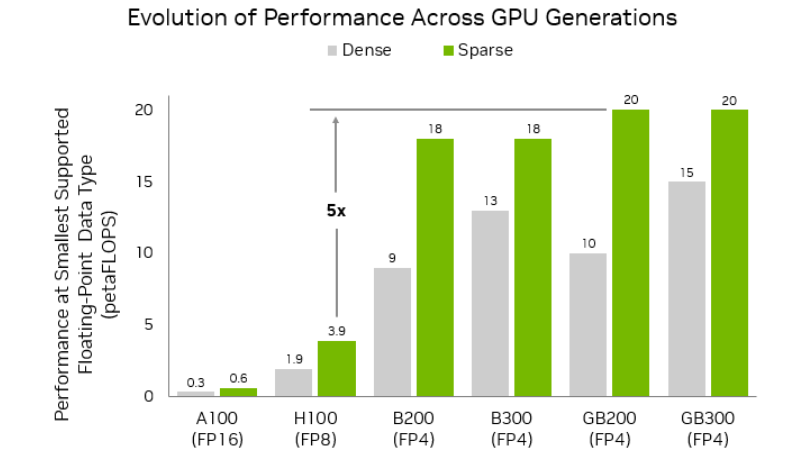 Estaba curioso si NVFP4 valía la compresión extra. Respuesta corta: tal vez, si estás apretado de VRAM y tus nodos realmente lo soportan.
Estaba curioso si NVFP4 valía la compresión extra. Respuesta corta: tal vez, si estás apretado de VRAM y tus nodos realmente lo soportan.
Así se sintió en la práctica en mi caja (GPU de clase Hopper, compilaciones de enero de 2026):
NVFP8
- Balance: Buen término medio. Notablemente menos memoria que precisión completa con desviación de salida mínima.
- Compatibilidad: Mejor. Más nodos y tiempos de ejecución aceptan FP8 que FP4 en este momento.
- Cuándo lo elijo: Ejecuciones diarias donde quiero estabilidad sobre la huella más pequeña.
NVFP4
- Huella: Más pequeña. Me permitió aumentar resolución o contexto un poco donde FP8 no lo haría.
- Desviación: Ligeramente más artefactos o suavidad en casos extremos. No siempre, pero lo suficiente para que lo note.
- Compatibilidad: Más exigente. Algunos cargadores caen o fallan si no detectan los kernels correctos.
- Cuándo lo elijo: Borradores rápidos, búsquedas de cuadrícula, o cuando el flujo de trabajo es estrictamente soportado por la ruta FP4 del nodo.
Una cosa más: estos formatos generalmente asumen que estás en una pila NVIDIA que puede acelerarlos adecuadamente. Si tu nodo no dice explícitamente “NVFP4/NVFP8 soportado,” me remito a la precisión completa o a una compilación .safetensors destilada. Perseguir ganancias marginales no vale la pena por el misterioso bloqueo a mitad de la representación.
Consejos de Aceleración y Verificación de Suma de Verificación de Descarga de LTX-2
Trato las grandes descargas de modelos como cualquier otro trabajo de archivo grande: aceléralo, luego verifica.
Aceleración que realmente ayudó:
- Aceleración de transferencia de Hugging Face: establece la variable de entorno
HF_HUB_ENABLE_HF_TRANSFER=1antes de usarhuggingface_hub. Esto activa su backend acelerado donde está disponible.
aria2c para fragmentos paralelos:
aria2c -x 16 -s 16 -k 1M -cLa bandera -c reanuda descargas parciales limpiamente cuando mi conexión se hiccupea en el 97%.
Descargas git-lfs sintonizadas
git lfs installluegogit clone.- Siguiendo la guía de instalación de Git LFS, si es un repositorio enorme, a veces uso sparse-checkout para evitar descargar ejemplos que no usaré.
Verificación que realmente hago (y no me salto más)
Compara SHA256 de la tarjeta del modelo (o los archivos .sha256 del repositorio) contra tu archivo local.
- macOS/Linux:
shasum -a 256 - Windows:
certutil -hashfile SHA256
Comprobación de cordura del tamaño de archivo
- Si el tamaño esperado es 4.2 GB y veo 3.3 GB, me detengo allí. Los archivos parciales ocasionalmente “cargan,” luego lanzan errores de basura más tarde.
Pequeño hábito que ahorra tiempo: mantengo un pequeño README.txt junto a los archivos del modelo con la URL de origen, fecha y hash. Cuando regreso tres meses después, no tengo que invertir las decisiones de mi yo pasado.
Correcciones de “Model Not Found”
Este error se comió una hora que no recuperaré. Aquí están las correcciones que realmente movieron la aguja para mí:
- Carpeta incorrecta: ComfyUI espera puntos de control en
models/checkpoints/, codificadores enmodels/clip/, y VAEs enmodels/vae/. Colócalos en cualquier otro lugar y el escáner puede ignorarlos. - Desajuste de nombre de archivo: Algunos nodos buscan un nombre base específico. Si el nodo dice
ltx-2.safetensors, no lo llamesLTX-2 (final).safetensors. Renombro agresivamente. - Sensibilidad a mayúsculas:
ltx-2.safetensors≠LTX-2.safetensorsen Linux. Pregúntame cómo lo sé. - Indexación de caché: Actualiza modelos o reinicia ComfyUI después de mover archivos. El índice no siempre es en tiempo real.
- Dependencia faltante: Si el nodo espera un codificador externo y solo descargaste el modelo principal, obtendrás un error vago. Descarga el codificador listado en la tarjeta del modelo e intenta de nuevo.
- Modelo bloqueado sin token: Si clonaste sin iniciar sesión (o tu token expiró), los archivos locales pueden ser tallos. Vuelve a iniciar sesión con
huggingface-cli loginy vuelve a descargar. - Nodos personalizados y rutas alternativas: Algunos nodos anulan carpetas predeterminadas. Verifica su README para rutas esperadas o variables de entorno. Cuando dudes, coloca un enlace simbólico desde tu directorio de modelos compartido a la ruta local esperada.
Cuando estoy atrapado, apunto temporalmente el nodo a un modelo conocido y pequeño solo para confirmar que el cargador funciona. Si el pequeño carga, el bug está en los archivos de LTX-2, no en mi entorno.
Salta Descargas de LTX-2 Usando WaveSpeed
Probé una ruta diferente en una laptop de viaje: salta completamente las descargas locales y ejecuta LTX-2 a través de WaveSpeed. Transmite u hospeda los pesos remotamente para que puedas conectar un gráfico similar a ComfyUI sin estacionar 10+ GB en tu disco.
 Lo que funcionó para mí:
Lo que funcionó para mí:
- La incorporación fue ligera. Apunté el gráfico a su punto final de LTX-2 y no toqué carpetas locales.
- Los inicios en frío fueron más lentos (la primera ejecución pone en marcha una sesión), pero las ejecuciones en caliente se sentían normales para lotes pequeños.
- Mantuvo el ventilador de mi laptop de aullar. Solo eso lo hizo útil en el camino.
Compensaciones que noté:
- Latencia: Hay una pequeña sobrecarga, más obvia con muchas ejecuciones cortas. Para largos renderizados, dejé de notarlo.
- Control: Renuncias a algunos pinning de versión. Mantienen modelos parcheados, lo cual es agradable, hasta que quieres reproducir un resultado anterior.
- Costo/cuotas: No es “gratis como una descarga.” Si estás en un presupuesto ajustado o necesitas mucho trabajo por lotes, las instalaciones locales aún ganan.
- Privacidad: Mantengo indicaciones y activos sensibles localmente. Para trabajo público o de prueba, estoy bien.
Quién podría gustarle esto: gente probando LTX-2 en máquinas con poca potencia, o cualquiera que quiera dibujar un flujo de trabajo antes de comprometerse con una configuración local completa. Si eres rico en VRAM y te importa la reproducibilidad exacta, las instalaciones locales se sienten mejor.
No esperaba que me gustara, pero para experimentos rápidos, saltarse la descarga fue un pequeño alivio.
Artículos relacionados

Seedance 2.0 Próximamente: El Modelo de Video de Próxima Generación de ByteDance con Audio Nativo

Guía Completa de Seedance 2.0: Creación de Vídeo Multimodal

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: La Comparación Definitiva de Generación de Video

Guía Completa de Seedream 5.0-Preview: Generación Inteligente de Imágenes

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Comparación Completa
