Instalar LTX-2 en ComfyUI en Windows: Guía de Configuración CUDA y Primera Ejecución

Hola, soy Dora. Ese día, solo quería una rápida pasada de texto a vídeo para un boceto, y seguía viendo LTX‑2 mencionado en hilos de ComfyUI. A media mañana estaba mirando un gráfico en blanco y una carpeta llamada “ltx”, preguntándome si acababa de inscribirme en la ruleta de controladores de nuevo.
Tomé notas mientras lo configuraba en Windows 11. Si estás buscando “ltx‑2 comfyui windows” porque estás a mitad de la instalación, he estado allí. Aquí hay lo que me ayudó.
Lista de Verificación Previa a la Instalación (versiones de GPU / CUDA / controlador)
Una verificación rápida antes de comenzar te ahorra la hora que pasarás persiguiendo errores de DLL más tarde:
- GPU: Una tarjeta NVIDIA con al menos 12 GB de VRAM hizo que LTX‑2 fuera utilizable para mí en configuraciones modestas (ancho de 512–768, clips cortos). 8 GB pueden funcionar con configuraciones muy conservadoras, pero es ajustado y frecuentemente frustrante.
- Controladores: Actualiza a un controlador Game Ready o Studio reciente (usé el 552.xx).
- CUDA: No instalas un kit de herramientas CUDA completo para ComfyUI portátil. Solo necesitas los DLL de tiempo de ejecución que vienen con PyTorch. Por eso es importante que coincida con la compilación de PyTorch+CUDA (cu121 o cu122, etc.).
- Python: La compilación portátil de ComfyUI viene con su propio Python. Si ejecutas un venv personalizado, mantenlo alineado con la rueda de PyTorch que elijas.
- Redistribuible de VC++: Instala/repara el último Redistribuible de Microsoft Visual C++. Es un arreglo silencioso para errores de DLL de estilo “punto de entrada de procedimiento”.
Dos comprobaciones de cordura que hago antes de cualquier modelo pesado:
nvidia-smise ejecuta en una terminal y muestra el controlador limpiamente.python -c "import torch: print(torch.version, torch.cuda.is_available())"devuelve True para CUDA en cualquier entorno que ComfyUI use.
Nada de esto garantiza un viaje sin problemas, pero reduce los modos de fallo.
Actualizar ComfyUI a Versión Lista para LTX-2
Lo que hice:
- Actualiza ComfyUI primero. Si estás en la compilación portátil de GitHub, obtén la última versión o haz git pull y ejecuta los scripts de actualización.
- Abre ComfyUI Manager (si lo usas) y actualiza las dependencias principales. Permití que Manager reconstruyera el venv cuando se le pidió.
- Instala el paquete de nodos LTX‑2 desde su repositorio oficial. El nombre varía (he visto repos de estilo “ComfyUI-LTXVideo”/“LTX‑Video”): usé el vinculado desde la página oficial del modelo. Si la descripción de un repositorio dice que admite LTX‑Video v2/LTX‑2, ese es el que quieres.
Por qué esto importa en la práctica:
- LTX‑2 se apoya en características de PyTorch 2.3+ y compilaciones de CUDA 12.x. Mezclar torch antiguo (cu118) con nodos nuevos es una forma rápida de obtener errores de importación crípticos.
- Algunos paquetes exponen los conmutadores FP8/BF16 de manera diferente. Hacer coincidir el paquete de nodos y la versión de ComfyUI evita entradas incompatibles y gráficos sin salida.
Resistí la instalación nueva al principio, parecía innecesaria. Luego comparé: la compilación nueva comenzó al primer intento; la anterior seguía pidiendo operaciones faltantes. No eché de menos las conjeturas.
Colocación de Archivo de Modelo (paso a paso)
Aquí es donde normalmente pierdo tiempo. Los diferentes nodos esperan diferentes carpetas. Aquí hay lo que funcionó para mí con el paquete de nodos LTX‑2 que instalé, y el patrón general se mantiene incluso si tus nombres de carpeta difieren.
-
Encuentra las rutas esperadas del nodo. En ComfyUI, abre el nodo cargador de LTX y coloca el cursor sobre cualquier entrada de archivo. La mayoría de paquetes muestran la ruta relativa que están escaneando (por ejemplo,
models/ltx,models/checkpoints, o una subcarpeta personalizada comomodels/ltx_video). Si tienes dudas, consulta el archivo README del repositorio. Generalmente enumeran el directorio exacto. -
Descarga los pesos de LTX‑2 de la fuente oficial (a menudo Hugging Face, vinculado desde la página del modelo). Típicamente obtendrás un archivo
.safetensorso.pthprincipal más configuraciones. Algunos repositorios dividen codificadores de texto/VAE por separado; otros los agrupan. -
Coloca los archivos exactamente donde el nodo los busca. Para mi paquete:
ComfyUI/models/ltx_video/contenía el archivo de modelo principal. Si tu paquete dicemodels/checkpoints, usa ese en su lugar. El nombre debe aparecer en el menú desplegable del nodo después de un reinicio o un rescaneo. -
Opcional: codificador de texto / VAE. Si el nodo expone entradas separadas para codificadores o un VAE, sigue su orientación. Muchos nodos LTX‑2 ocultan esto y agrupan componentes internamente. Si está expuesto, coloca archivos CLIP/Tokenizer en
models/clipomodels/text_encoderssegún lo instruido por el archivo README. -
Reinicia ComfyUI. Lo sé, es obvio. Pero la recarga en caliente no siempre rescatea estas carpetas, y he mirado un menú desplegable vacío más veces de las que admito.
Pequeña nota: si Windows marca los archivos descargados como bloqueados (clic derecho > Propiedades > Desbloquear), limpia eso. He tenido Python rehusarse a tocar archivos “descargados de internet” en configuraciones más estrictas.
Errores Comunes de Windows (DLL / permisos)
“DLL load failed while importing …” o nvrtc64_X.dll faltante
- Causa: La compilación de PyTorch no coincidía con el tiempo de ejecución de CUDA esperado por el paquete de nodos, o el entorno mezcló cu118 y cu12x.
- Solución: Reinstala/confirma PyTorch 2.3+ con cu121/cu122 dentro del entorno de ComfyUI. Si ejecutas portátil, deja que Manager lo maneje. Actualizar controladores NVIDIA ayudó una vez.
“Acceso denegado” al escribir fotogramas/vídeo
- Causa: Apunté el nodo SaveVideo a una carpeta sincronizada con permisos agresivos (OneDrive).
- Solución: Escribe primero en una ruta local no sincronizada (por ejemplo,
ComfyUI/output/ltx_test). Mueve el archivo después.
Problemas de ruta larga en descompresión
- Causa: Límites de longitud de ruta de Windows más subcarpetas profundas de ComfyUI.
- Solución: Habilita rutas largas en Windows (Política de Grupo Local o registro) o descomprime más cerca de
C:\.
Antivirus escaneando fotogramas temporales a mitad de la renderización
- Síntoma: Bloqueo o tartamudeo de ComfyUI durante la codificación.
- Solución: Añade una exclusión para la carpeta ComfyUI o solo la ruta temporal de salida.
“No se pudo encontrar el modelo” aunque la carpeta es correcta
- Solución: Reinicia ComfyUI. Si aún no aparece, verifica la carpeta exacta esperada por el nodo. Algunos nodos LTX‑2 buscan en un nombre de directorio personalizado. Hazlo coincidir exactamente.
También me encontré con el clásico “funciona una vez, falla la siguiente ejecución”. Para mí, eso se redujo a una pestaña de navegador intentando previsualizar el MP4 parcial mientras el nodo de codificación aún estaba escribiendo. Cambié a escribir en un nombre de archivo nuevo por ejecución. La inestabilidad desapareció.
Flujo de Trabajo de Prueba de Primera Inferencia
Mantuve el primer gráfico pequeño. Nada elaborado, solo lo suficiente para confirmar el pipeline.
Lo que construí:
- Un nodo Prompt con una sola oración (10–20 tokens). Mantenlo simple.
- Nodo Cargador de LTX‑2 apuntando al modelo descargado.
- Un nodo Muestreador/Planificador de LTX‑2 (o como lo nombre tu paquete) con pocos pasos.
- Una ruta de Decodificación/Ensamblaje de Vídeo que escribe fotogramas en un nodo SaveVideo (MP4, H.264 está bien para una prueba de humo).
Parámetros que no me pelearon:
- Resolución: 512×288 o 640×360
- Fotogramas: 8–16 fotogramas (0.5–1 segundo)
- Pasos: 6–12
- Orientación/CFG: punto medio (5–7)
- Seed: número fijo (hace el troubleshooting menos ruidoso)
- Precisión: FP16 (predeterminado) a menos que tu nodo sugiera BF16 en Ada: ambos funcionaron para mí, FP16 usó menos VRAM
Lo que observo en la primera ejecución:
- Picos de VRAM en
nvidia-smi. Si estás pegado al 99% de VRAM instantáneamente, reduce la resolución o los fotogramas. - Tiempo hasta el primer fotograma. Mi primera ejecución limpia fue ~25–40 segundos para 16 fotogramas a 512×288 en una 4070, pasos=8. Cualquier cosa mucho más larga generalmente apuntaba a codificación de CPU o un cuello de botella de E/S.
Si tu renderización se completa pero el vídeo está vacío o corrupto, intenta:
- Escribir fotogramas PNG primero, luego permitir que un nodo separado o una herramienta externa ensamble el vídeo.
- Cambiar a un codificador diferente (H.264 vs H.265) o valor CRF.
La parte útil no fue la velocidad, fue ver un clip coherente. Ese es el momento en el que me relajo. Luego escalo cuidadosamente.
Sintonización de Rendimiento (lote / precisión)
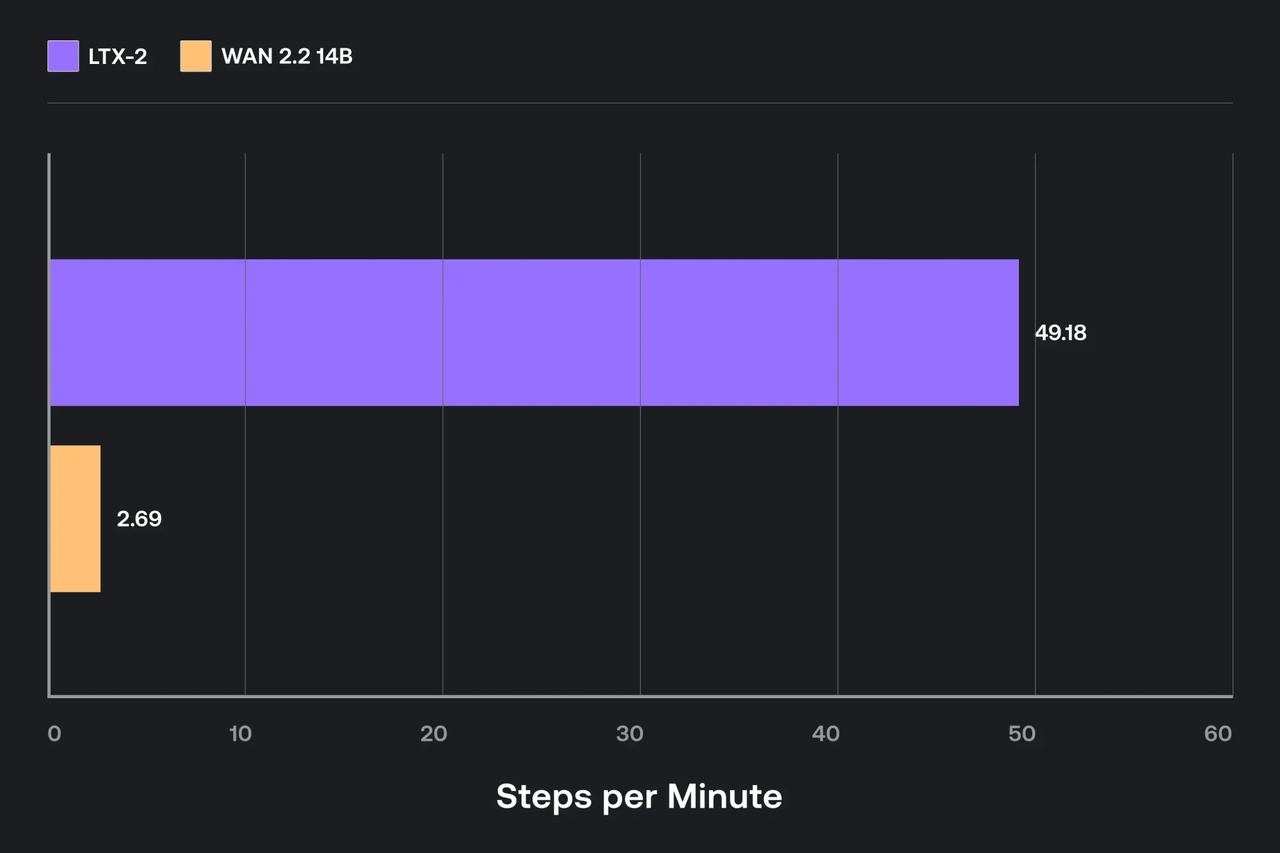
No perseguí la gloria de los puntos de referencia. Solo quería configuraciones que me evitaran estar atento a la memoria.
Lo que movió la aguja:
- Fotogramas antes del ancho. Era más fácil en VRAM mantener 12–16 fotogramas y aumentar el ancho a 640 que saltar a 24+ fotogramas. Los clips más largos suben rápido en memoria.
- Precisión: FP16 funcionó mejor en mi 4070. BF16 también funcionó pero usó un poco más de memoria. No gané calidad visible de BF16 en estos tamaños.
- Backend de atención: Si tu paquete expone un conmutador para
scaled_dot_product_attention(nativo de PyTorch) vs xFormers, prueba nativo primero en PyTorch reciente. Fue más estable para mí en Windows. - Tamaño de lote: Mantenlo en 1 para vídeo. Los mini‑lotes principalmente castigaron la VRAM sin ahorrar tiempo de reloj de pared en mi configuración.
- Compilación de Torch: Vale la pena probar, pero solo vi pequeñas ganancias para ejecuciones más largas. Para pruebas cortas de 8–16 fotogramas, el tiempo de compilación podría comerse los ahorros.
- E/S mixta: Escribir en un SSD local rápido importó más de lo esperado. Las carpetas de red lentas hicieron que la fase de codificación se viera como un problema de modelo cuando no lo era.
Una escala simple que no explotó VRAM para mí:
- 512×288, 12 fotogramas, pasos=8
- 640×360, 16 fotogramas, pasos=10
- 768×432, 16–24 fotogramas, pasos=12–14
Si alcanzas falta de memoria:
- Reduce fotogramas por 4 antes de bajar el ancho.
- Reduce pasos primero si solo necesitas un borrador.
- Cierra otras aplicaciones de GPU (reproductores de vídeo, navegador con aceleración por hardware). Tedioso, pero funciona.
También probé un pequeño modo de mosaico/parche que algunos paquetes ofrecen. Ayudó en anchos más altos pero a veces introdujo costuras. Bueno para experimentos: no es mi predeterminado.
Ruta de WaveSpeed (sin CUDA local necesario)
Probé una ejecución a través de una ruta alojada para evitar el cambio de GPU. La idea: permitir que ComfyUI hable con un trabajador remoto que ejecuta LTX‑2, para que tu caja de Windows local solo maneje la interfaz de usuario del gráfico.
Cómo se vió esto en la práctica:
- Instala un conector/extensión en ComfyUI (el que usé se etiquetaba a sí mismo como “WaveSpeed” en la lista de Manager). Después de instalar, apareció un nuevo conjunto de nodos para ejecución remota.
- Autentica o apúntalo a un punto final de trabajador. El mío usaba una clave de panel. La configuración tomó algunos minutos.
- Cambia el cargador/muestreador local de LTX‑2 por los equivalentes de WaveSpeed. Los mismos prompts, la misma forma de gráfico, solo nodos diferentes.
Salta las complejidades de configuración: Prueba LTX‑2 instantáneamente en WaveSpeed — sin GPU local, sin juego de controladores, solo ingresa tu prompt y comienza a renderizar.
Si tienes curiosidad, consulta los documentos oficiales del conector para los pasos de configuración actuales. No reconstruiría todo mi flujo de trabajo alrededor de esto, pero como ruta sin CUDA, fue refrescantemente aburrido, de una buena manera.
Artículos relacionados

Seedance 2.0 Próximamente: El Modelo de Video de Próxima Generación de ByteDance con Audio Nativo

Guía Completa de Seedance 2.0: Creación de Vídeo Multimodal

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: La Comparación Definitiva de Generación de Video

Guía Completa de Seedream 5.0-Preview: Generación Inteligente de Imágenes

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Comparación Completa
